आर में यादृच्छिक वन कैसे बनाएं (चरण दर चरण)
जब भविष्यवक्ता चर के एक सेट और एक प्रतिक्रिया चर के बीच संबंध बहुत जटिल होता है, तो हम अक्सर उनके बीच संबंध को मॉडल करने के लिए गैर-रेखीय तरीकों का उपयोग करते हैं।
ऐसी ही एक विधि निर्णय वृक्ष बनाना है। हालाँकि, एकल निर्णय वृक्ष का उपयोग करने का नकारात्मक पक्ष यह है कि इसमें उच्च भिन्नता का सामना करना पड़ता है।
अर्थात्, यदि हम डेटासेट को दो हिस्सों में विभाजित करते हैं और निर्णय वृक्ष को दोनों हिस्सों में लागू करते हैं, तो परिणाम बहुत भिन्न हो सकते हैं।
एकल निर्णय वृक्ष के विचरण को कम करने के लिए हम जिस एक विधि का उपयोग कर सकते हैं वह एक यादृच्छिक वन मॉडल बनाना है, जो निम्नानुसार काम करता है:
1. मूल डेटासेट से बी बूटस्ट्रैप्ड नमूने लें।
2. प्रत्येक बूटस्ट्रैप नमूने के लिए एक निर्णय वृक्ष बनाएं।
- पेड़ का निर्माण करते समय, हर बार विभाजन पर विचार किया जाता है, केवल एम भविष्यवक्ताओं का एक यादृच्छिक नमूना पी भविष्यवक्ताओं के पूर्ण सेट से विभाजन के लिए उम्मीदवार माना जाता है। आम तौर पर, हम √p के बराबर m चुनते हैं।
3. अंतिम मॉडल प्राप्त करने के लिए प्रत्येक पेड़ से पूर्वानुमानों का औसत निकालें।
यह पता चला है कि यादृच्छिक वन एकल निर्णय वृक्षों और यहां तक कि बैग्ड मॉडल की तुलना में अधिक सटीक मॉडल तैयार करते हैं।
यह ट्यूटोरियल आर में डेटासेट के लिए यादृच्छिक फ़ॉरेस्ट मॉडल बनाने का चरण-दर-चरण उदाहरण प्रदान करता है।
चरण 1: आवश्यक पैकेज लोड करें
सबसे पहले, हम इस उदाहरण के लिए आवश्यक पैकेज लोड करेंगे। इस सरल उदाहरण के लिए, हमें केवल एक पैकेज की आवश्यकता है:
library (randomForest)
चरण 2: यादृच्छिक वन मॉडल को समायोजित करें
इस उदाहरण के लिए, हम एयर क्वालिटी नामक एक अंतर्निहित आर डेटासेट का उपयोग करेंगे जिसमें 153 व्यक्तिगत दिनों में न्यूयॉर्क शहर में वायु गुणवत्ता का माप शामिल है।
#view structure of air quality dataset str(airquality) 'data.frame': 153 obs. of 6 variables: $ Ozone: int 41 36 12 18 NA 28 23 19 8 NA ... $Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ... $ Wind: num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ... $ Temp: int 67 72 74 62 56 66 65 59 61 69 ... $Month: int 5 5 5 5 5 5 5 5 5 5 ... $Day: int 1 2 3 4 5 6 7 8 9 10 ... #find number of rows with missing values sum(! complete . cases (airquality)) [1] 42
इस डेटासेट में गायब मानों वाली 42 पंक्तियाँ हैं। इसलिए, एक यादृच्छिक वन मॉडल को फ़िट करने से पहले, हम कॉलम माध्यकों के साथ प्रत्येक कॉलम में लापता मान भरेंगे:
#replace NAs with column medians for (i in 1: ncol (air quality)) { airquality[,i][ is . na (airquality[, i])] <- median (airquality[, i], na . rm = TRUE ) }
संबंधित: आर में लुप्त मानों को कैसे आरोपित करें
निम्नलिखित कोड दिखाता है कि रैंडमफॉरेस्ट पैकेज से रैंडमफॉरेस्ट() फ़ंक्शन का उपयोग करके आर में एक यादृच्छिक वन मॉडल को कैसे फिट किया जाए।
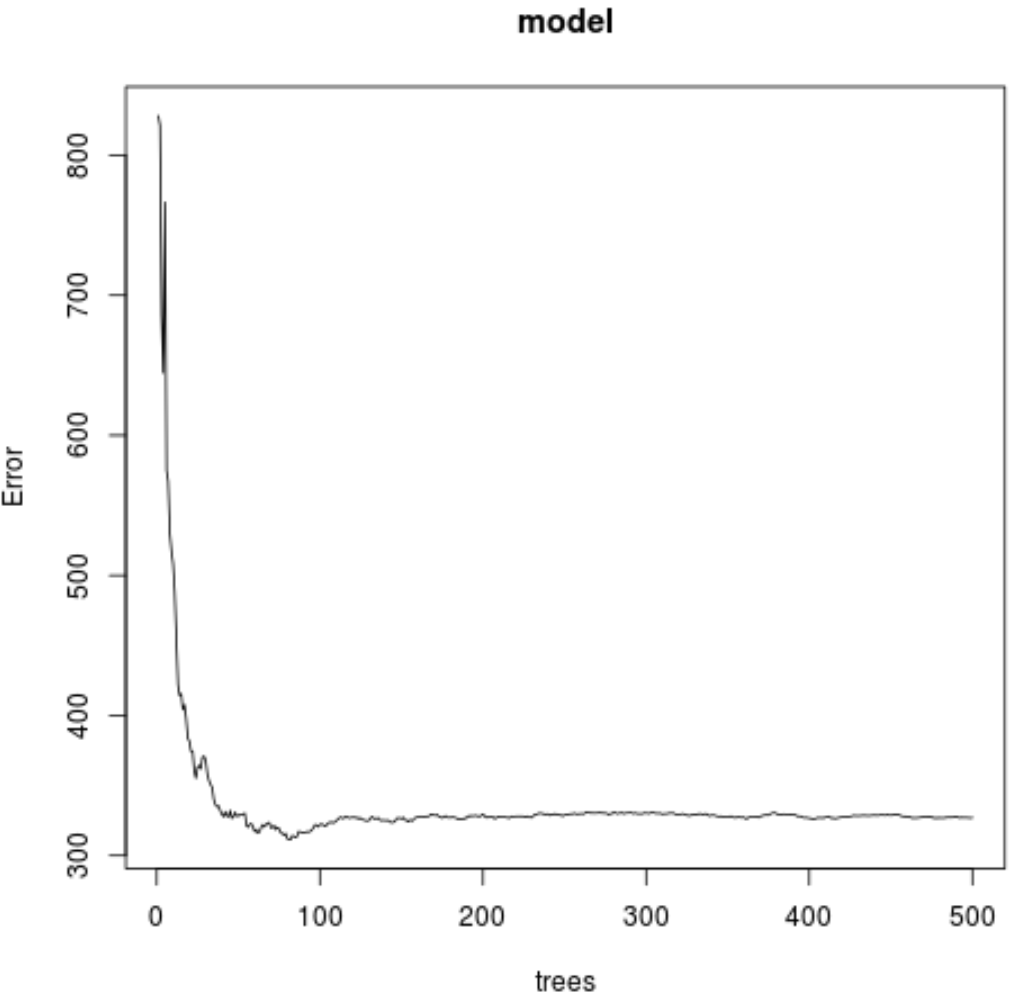
#make this example reproducible set.seed(1) #fit the random forest model model <- randomForest( formula = Ozone ~ ., data = airquality ) #display fitted model model Call: randomForest(formula = Ozone ~ ., data = airquality) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 1 Mean of squared residuals: 327.0914 % Var explained: 61 #find number of trees that produce lowest test MSE which.min(model$mse) [1] 82 #find RMSE of best model sqrt(model$mse[ which . min (model$mse)]) [1] 17.64392
परिणाम से, हम देख सकते हैं कि जिस मॉडल ने सबसे कम परीक्षण माध्य वर्ग त्रुटि (MSE) उत्पन्न की, उसमें 82 पेड़ों का उपयोग किया गया।
हम यह भी देख सकते हैं कि इस मॉडल की मूल माध्य वर्ग त्रुटि 17.64392 थी। हम इसे ओजोन के अनुमानित मूल्य और वास्तविक देखे गए मूल्य के बीच औसत अंतर के रूप में सोच सकते हैं।
हम उपयोग किए गए पेड़ों की संख्या के आधार पर एमएसई परीक्षण का प्लॉट तैयार करने के लिए निम्नलिखित कोड का भी उपयोग कर सकते हैं:
#plot the MSE test by number of trees
plot(model)
और हम एक प्लॉट बनाने के लिए varImpPlot() फ़ंक्शन का उपयोग कर सकते हैं जो अंतिम मॉडल में प्रत्येक भविष्यवक्ता चर के महत्व को प्रदर्शित करता है:
#produce variable importance plot
varImpPlot(model)
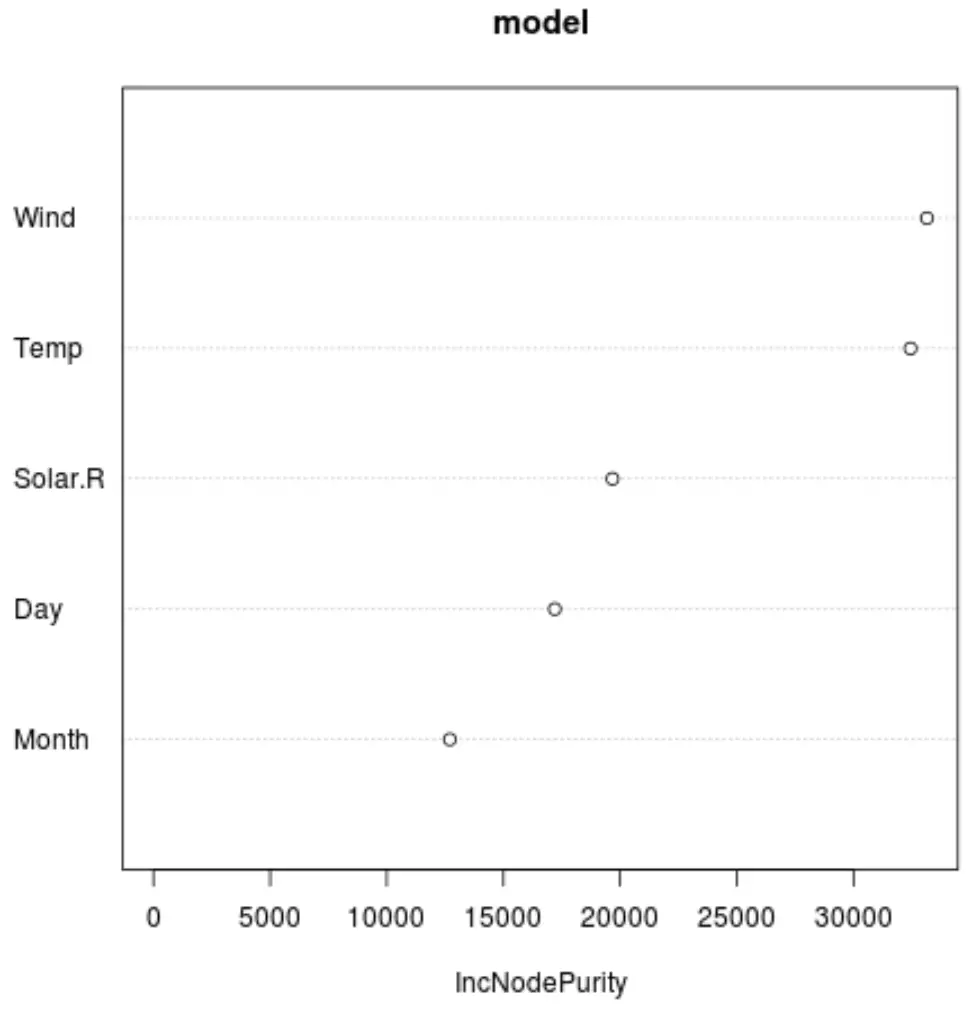
x-अक्ष, y-अक्ष पर प्रदर्शित विभिन्न भविष्यवक्ताओं में विभाजन के एक फ़ंक्शन के रूप में प्रतिगमन पेड़ों की नोड शुद्धता में औसत वृद्धि प्रदर्शित करता है।
ग्राफ़ से, हम देख सकते हैं कि पवन सबसे महत्वपूर्ण भविष्यवक्ता चर है, इसके बाद तापमान आता है।
चरण 3: मॉडल को समायोजित करें
डिफ़ॉल्ट रूप से, रैंडमफ़ॉरेस्ट() फ़ंक्शन प्रत्येक विभाजन के लिए संभावित उम्मीदवारों के रूप में 500 पेड़ों और (कुल भविष्यवक्ता/3) यादृच्छिक रूप से चयनित भविष्यवक्ताओं का उपयोग करता है। हम ट्यूनआरएफ() फ़ंक्शन का उपयोग करके इन मापदंडों को समायोजित कर सकते हैं।
निम्नलिखित कोड दिखाता है कि निम्नलिखित विशिष्टताओं का उपयोग करके इष्टतम मॉडल कैसे खोजा जाए:
- ntreeTry: बनाए जाने वाले पेड़ों की संख्या।
- mtryStart: प्रत्येक डिवीजन में ध्यान में रखने के लिए भविष्यवक्ता चर की प्रारंभिक संख्या।
- स्टेपफ़ैक्टर: जब तक अनुमानित आउट-ऑफ़-बैग त्रुटि में एक निश्चित मात्रा में सुधार होना बंद नहीं हो जाता, तब तक बढ़ने वाला कारक।
- सुधार: वह राशि जिसके द्वारा चरण कारक को बढ़ाना जारी रखने के लिए बैग निकास त्रुटि में सुधार किया जाना चाहिए।
model_tuned <- tuneRF(
x=airquality[,-1], #define predictor variables
y=airquality$Ozone, #define response variable
ntreeTry= 500 ,
mtryStart= 4 ,
stepFactor= 1.5 ,
improve= 0.01 ,
trace= FALSE #don't show real-time progress
)
यह फ़ंक्शन निम्नलिखित प्लॉट तैयार करता है, जो x-अक्ष पर पेड़ों का निर्माण करते समय प्रत्येक विभाजन पर उपयोग किए जाने वाले भविष्यवक्ताओं की संख्या और y-अक्ष पर अनुमानित आउट-ऑफ-बैग त्रुटि प्रदर्शित करता है:
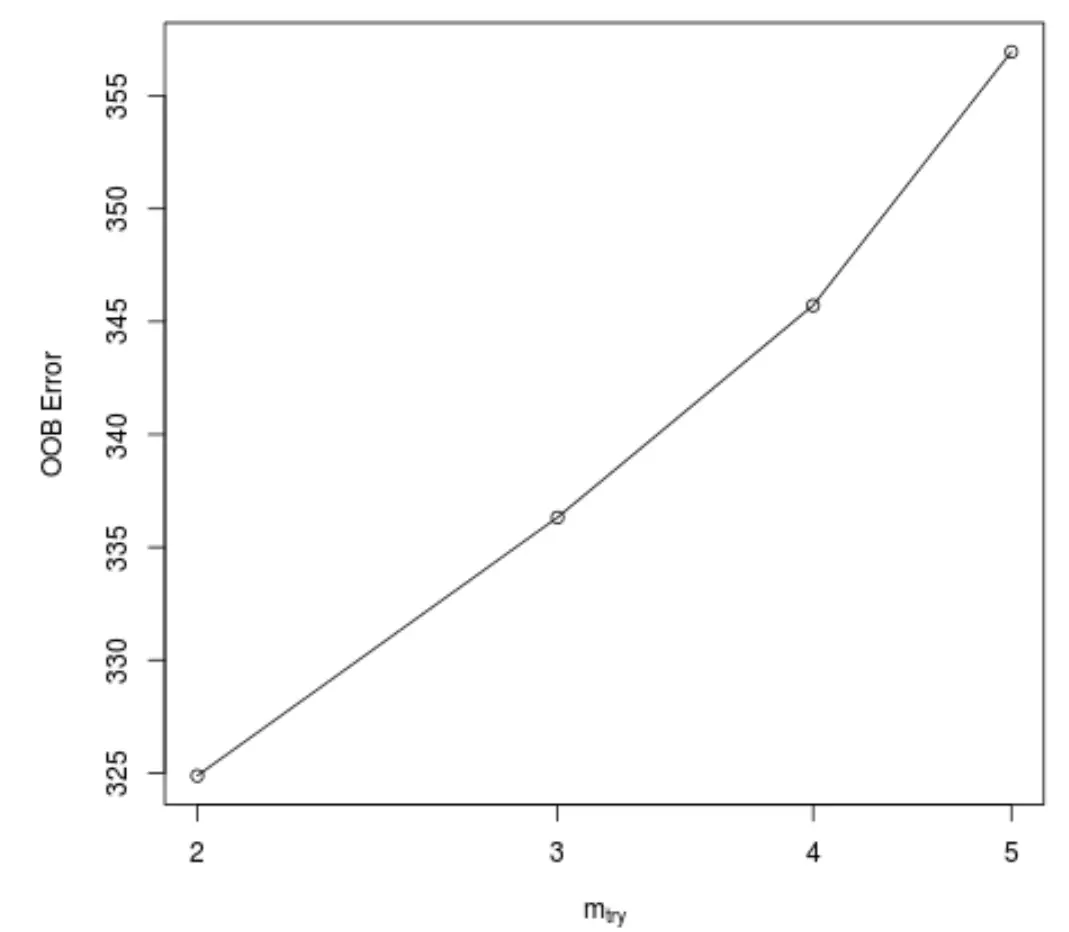
हम देख सकते हैं कि पेड़ों का निर्माण करते समय प्रत्येक विभाजन पर 2 यादृच्छिक रूप से चुने गए भविष्यवक्ताओं का उपयोग करके सबसे कम OOB त्रुटि प्राप्त की जाती है।
यह वास्तव में प्रारंभिक रैंडमफॉरेस्ट() फ़ंक्शन द्वारा उपयोग की जाने वाली डिफ़ॉल्ट सेटिंग (कुल भविष्यवक्ता/3 = 6/3 = 2) से मेल खाती है।
चरण 4: पूर्वानुमान लगाने के लिए अंतिम मॉडल का उपयोग करें
अंत में, हम नई टिप्पणियों के बारे में भविष्यवाणियां करने के लिए समायोजित यादृच्छिक वन मॉडल का उपयोग कर सकते हैं।
#define new observation new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5) #use fitted bagged model to predict Ozone value of new observation predict(model, newdata=new) 27.19442
भविष्यवक्ता चर के मूल्यों के आधार पर, फिट यादृच्छिक वन मॉडल भविष्यवाणी करता है कि इस विशेष दिन पर ओजोन मूल्य 27.19442 होगा।
इस उदाहरण में प्रयुक्त पूरा आर कोड यहां पाया जा सकता है।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने