उच्च-आयामी डेटा क्या है? (परिभाषा एवं उदाहरण)
उच्च-आयामी डेटा एक डेटा सेट को संदर्भित करता है जिसमें सुविधाओं पी की संख्या अवलोकनों की संख्या एन से अधिक है, जिसे अक्सर पी >> एन के रूप में लिखा जाता है।
उदाहरण के लिए, पी = 6 विशेषताओं और केवल एन = 3 अवलोकनों वाले डेटासेट को उच्च-आयामी डेटा माना जाएगा क्योंकि सुविधाओं की संख्या अवलोकनों की संख्या से अधिक है।
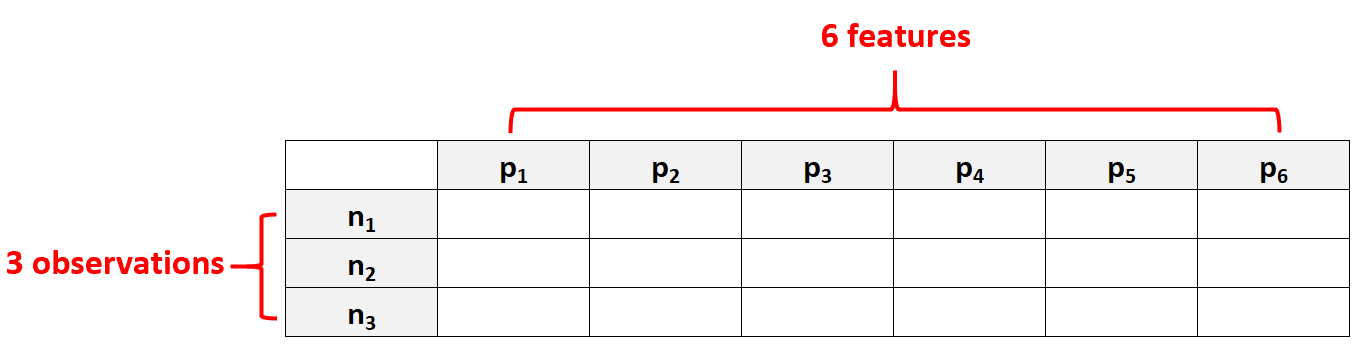
लोगों द्वारा की जाने वाली एक सामान्य गलती यह मान लेना है कि “उच्च-आयामी डेटा” का अर्थ केवल कई विशेषताओं वाला डेटा सेट है। हालाँकि, यह ग़लत है. एक डेटासेट में 10,000 विशेषताएं हो सकती हैं, लेकिन यदि इसमें 100,000 अवलोकन हैं, तो यह उच्च-आयामी नहीं है।
नोट: उच्च-आयामी डेटा के पीछे के गणित की गहन चर्चा के लिए सांख्यिकीय शिक्षण के तत्वों के अध्याय 18 का संदर्भ लें।
उच्च-आयामी डेटा एक समस्या क्यों है?
जब किसी डेटासेट में सुविधाओं की संख्या अवलोकनों की संख्या से अधिक हो जाती है, तो हमारे पास कभी भी कोई नियतात्मक उत्तर नहीं होगा।
दूसरे शब्दों में, ऐसा मॉडल ढूंढना असंभव हो जाता है जो भविष्यवक्ता चर और प्रतिक्रिया चर के बीच संबंध का वर्णन कर सके, क्योंकि हमारे पास मॉडल को प्रशिक्षित करने के लिए पर्याप्त अवलोकन नहीं हैं।
उच्च-आयामी डेटा के उदाहरण
निम्नलिखित उदाहरण विभिन्न डोमेन में उच्च-आयामी डेटासेट का वर्णन करते हैं।
उदाहरण 1: स्वास्थ्य डेटा
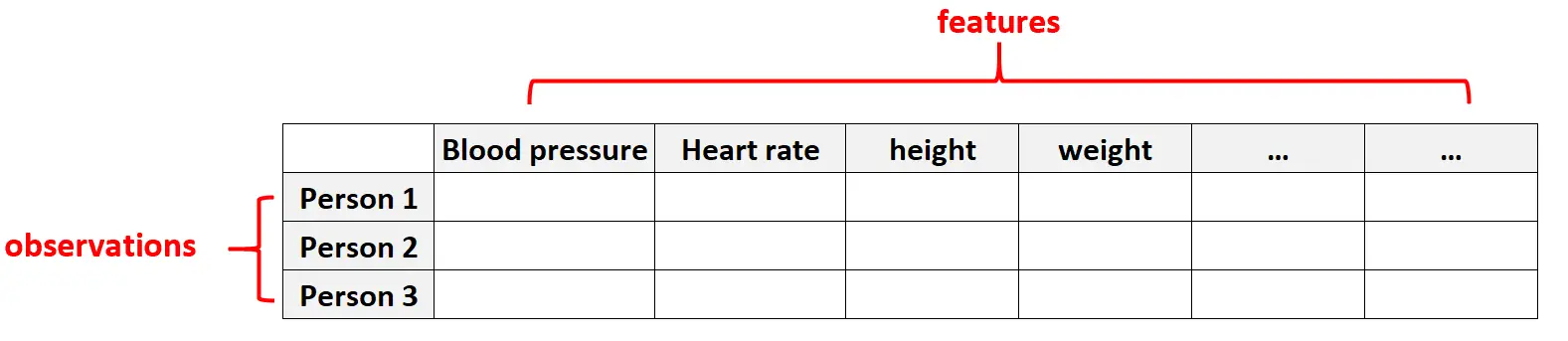
उच्च-आयामी डेटा स्वास्थ्य देखभाल डेटासेट में आम है जहां किसी दिए गए व्यक्ति के लिए सुविधाओं की संख्या बहुत अधिक हो सकती है (यानी रक्तचाप, शेष हृदय गति, प्रतिरक्षा प्रणाली की स्थिति, सर्जिकल इतिहास, ऊंचाई, वजन, मौजूदा स्थितियां, आदि)।
इन डेटासेट में, सुविधाओं की संख्या अवलोकनों की संख्या से अधिक होना आम बात है।
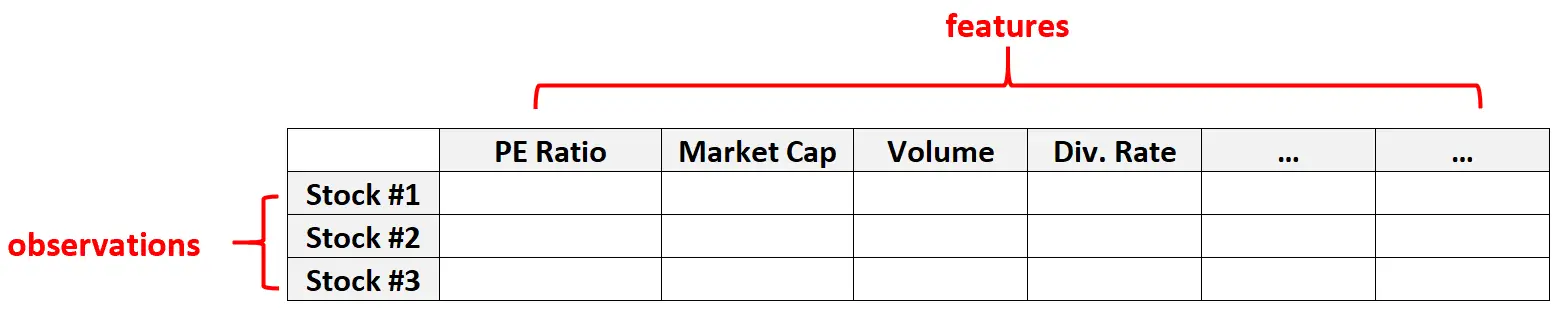
उदाहरण 2: वित्तीय डेटा
उच्च-आयामी डेटा वित्तीय डेटासेट में भी आम है जहां किसी दिए गए स्टॉक के लिए सुविधाओं की संख्या काफी बड़ी हो सकती है (यानी पीई अनुपात, बाजार पूंजीकरण, ट्रेडिंग वॉल्यूम, लाभांश दर, आदि)
इस प्रकार के डेटासेट में, इकाइयों की संख्या व्यक्तिगत क्रियाओं की संख्या से कहीं अधिक होना आम बात है।
उदाहरण 3: जीनोमिक्स
उच्च-आयामी डेटा जीनोमिक्स के क्षेत्र में भी आम है, जहां किसी व्यक्ति की आनुवंशिक विशेषताओं की संख्या बहुत अधिक हो सकती है।

बड़े डेटा को कैसे संभालें
उच्च-आयामी डेटा को संसाधित करने के दो सामान्य तरीके हैं:
1. कम सुविधाएँ शामिल करना चुनें.
उच्च-आयामी डेटा से निपटने से बचने का सबसे स्पष्ट तरीका डेटासेट में कम सुविधाओं को शामिल करना है।
यह तय करने के कई तरीके हैं कि डेटासेट से कौन सी सुविधाएँ हटाई जाएँ, जिनमें शामिल हैं:
- कई गुम मानों वाली सुविधाओं को हटाएं: यदि डेटासेट में दिए गए कॉलम में कई गुम मान हैं, तो आप अधिक जानकारी खोए बिना इसे पूरी तरह से हटाने में सक्षम हो सकते हैं।
- कम-विचरण सुविधाओं को हटाएं: यदि किसी डेटासेट में दिए गए कॉलम में ऐसे मान हैं जो बहुत कम बदलते हैं, तो आप इसे हटाने में सक्षम हो सकते हैं क्योंकि यह अन्य सुविधाओं की तुलना में प्रतिक्रिया चर के बारे में अधिक उपयोगी जानकारी प्रदान करने की संभावना नहीं है।
- प्रतिक्रिया चर के साथ कम सहसंबंध वाली सुविधाओं को हटाएं: यदि कोई निश्चित सुविधा उस प्रतिक्रिया चर के साथ अत्यधिक सहसंबद्ध नहीं है, जिसमें आप रुचि रखते हैं, तो आप संभवतः इसे डेटासेट से हटा सकते हैं, क्योंकि यह संभावना नहीं है कि यह एक मॉडल में एक उपयोगी सुविधा है।
2. नियमितीकरण विधि का प्रयोग करें.
डेटासेट से सुविधाओं को हटाए बिना उच्च-आयामी डेटा को संभालने का दूसरा तरीका नियमितीकरण तकनीक का उपयोग करना है जैसे:
इनमें से प्रत्येक तकनीक का उपयोग उच्च-आयामी डेटा को कुशलतापूर्वक संसाधित करने के लिए किया जा सकता है।
आप इस पृष्ठ पर सभी सांख्यिकीय मशीन लर्निंग ट्यूटोरियल की पूरी सूची पा सकते हैं।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने