एक्सेल में कन्फ्यूजन मैट्रिक्स कैसे बनाएं
लॉजिस्टिक रिग्रेशन एक प्रकार का रिग्रेशन है जिसका उपयोग हम तब कर सकते हैं जब प्रतिक्रिया चर द्विआधारी हो।
लॉजिस्टिक रिग्रेशन मॉडल की गुणवत्ता का आकलन करने का एक सामान्य तरीका एक भ्रम मैट्रिक्स बनाना है, जो एक 2 × 2 तालिका है जो मॉडल के अनुमानित मूल्यों बनाम परीक्षण डेटासेट के वास्तविक मूल्यों को दिखाती है।

निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि एक्सेल में कन्फ्यूजन मैट्रिक्स कैसे बनाया जाए।
चरण 1: डेटा दर्ज करें
सबसे पहले, आइए लॉजिस्टिक रिग्रेशन मॉडल द्वारा अनुमानित मूल्यों के साथ प्रतिक्रिया चर के लिए वास्तविक मूल्यों का एक कॉलम दर्ज करें:
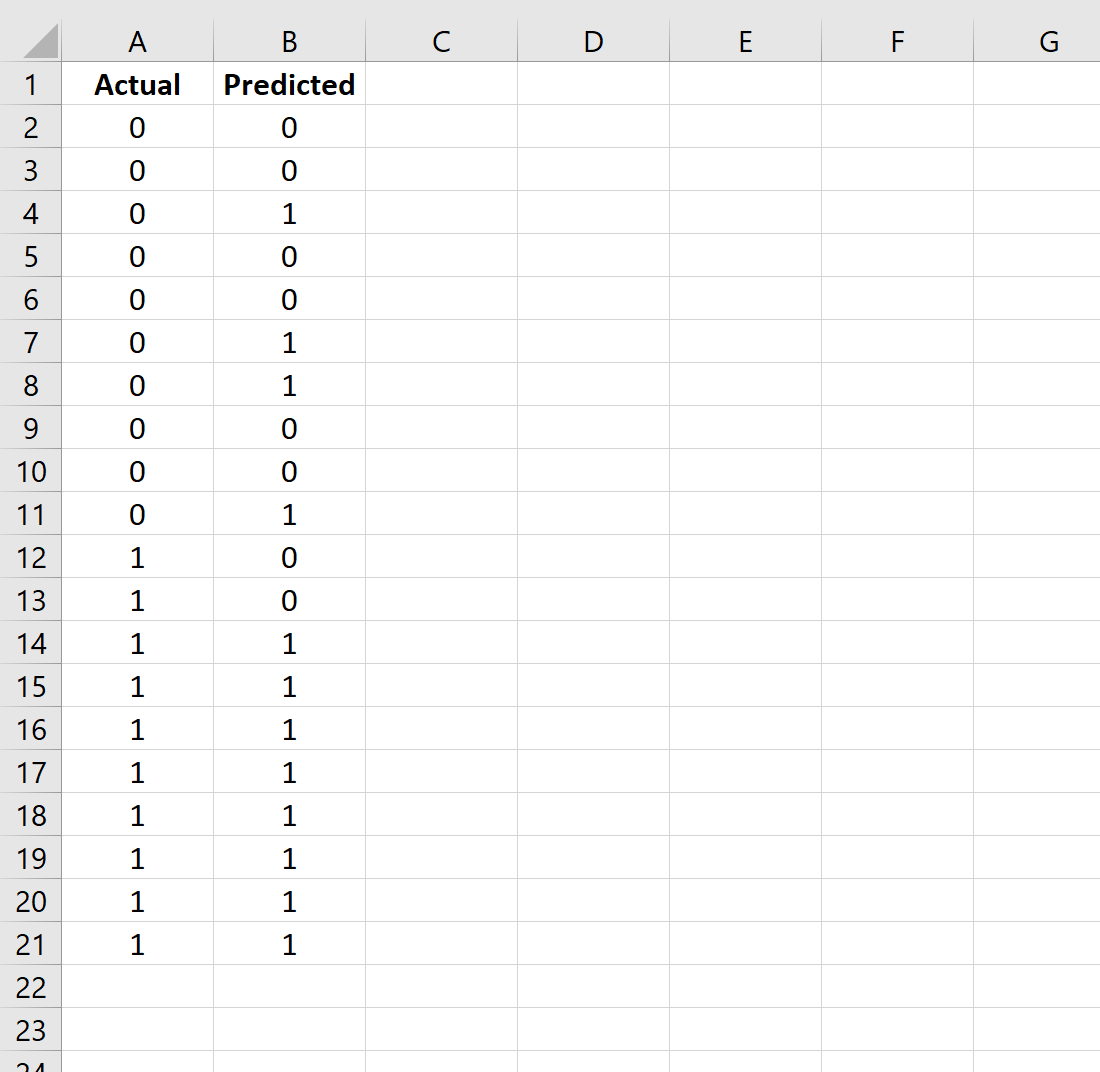
चरण 2: कन्फ्यूजन मैट्रिक्स बनाएं
इसके बाद, हम वास्तविक कॉलम में “0” और अनुमानित कॉलम में “0” मानों की संख्या की गणना करने के लिए COUNTIFS() सूत्र का उपयोग करेंगे:
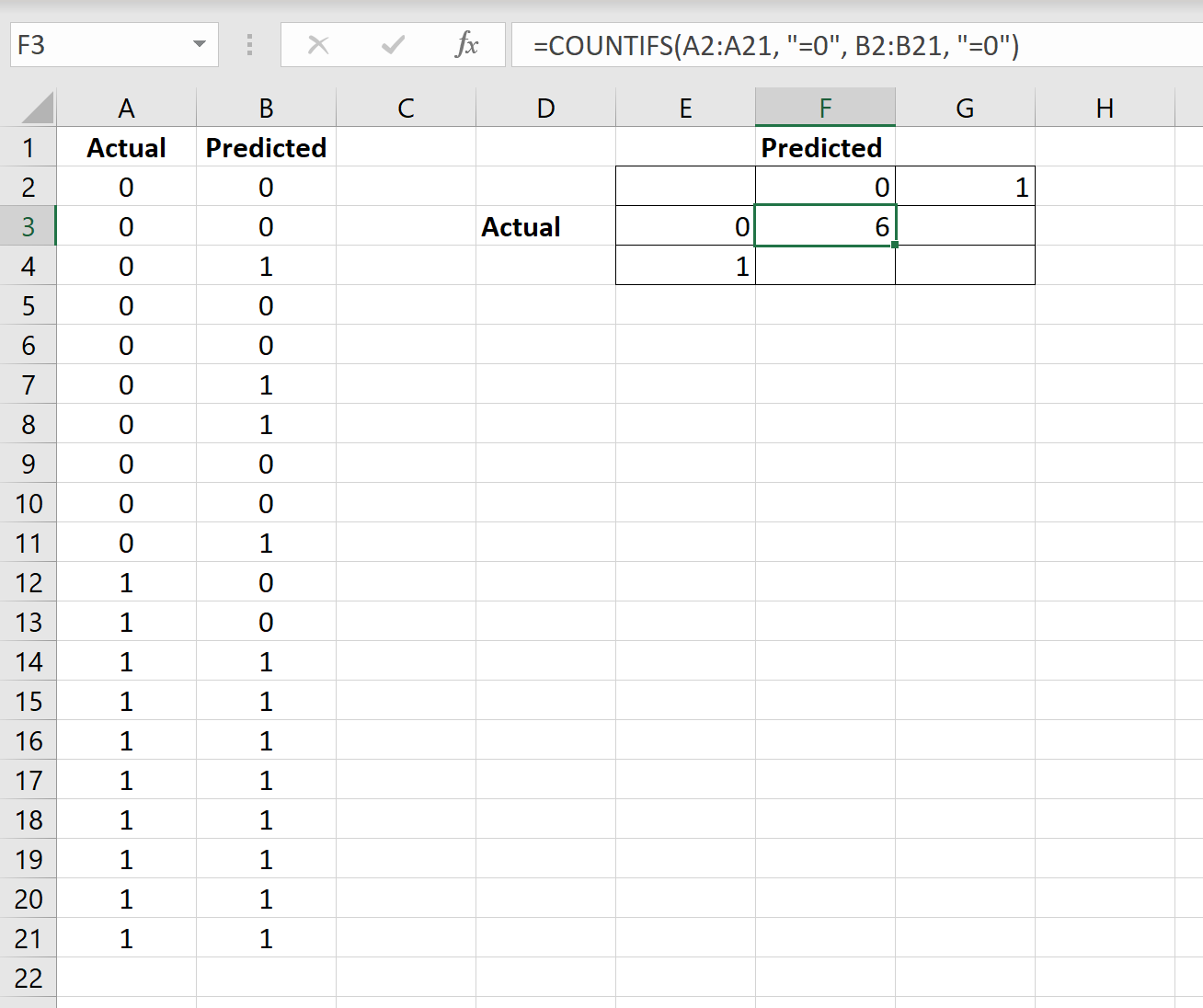
हम भ्रम मैट्रिक्स में अन्य सभी कोशिकाओं को भरने के लिए एक समान सूत्र का उपयोग करेंगे:
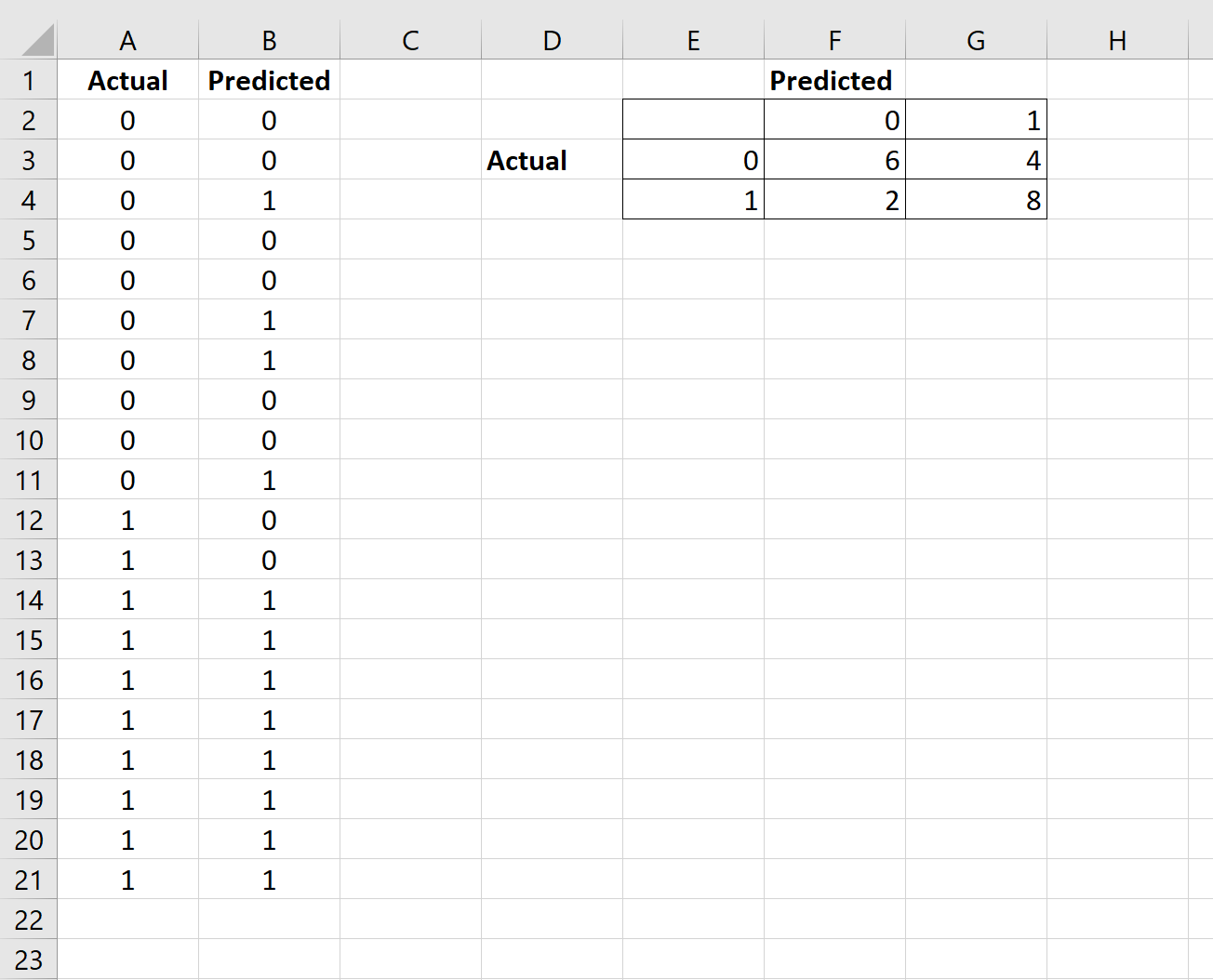
चरण 3: सटीकता, परिशुद्धता और स्मरण की गणना करें
एक बार जब हम भ्रम मैट्रिक्स बना लेते हैं, तो हम निम्नलिखित मैट्रिक्स की गणना कर सकते हैं:
- सटीकता : सही भविष्यवाणियों का प्रतिशत
- सटीकता : कुल सकारात्मक भविष्यवाणियों के सापेक्ष सकारात्मक भविष्यवाणियों को सही करें
- अनुस्मारक : कुल वास्तविक सकारात्मकताओं के विरुद्ध सकारात्मक भविष्यवाणियों को सही करना
निम्नलिखित सूत्र बताते हैं कि एक्सेल में इनमें से प्रत्येक माप की गणना कैसे करें:
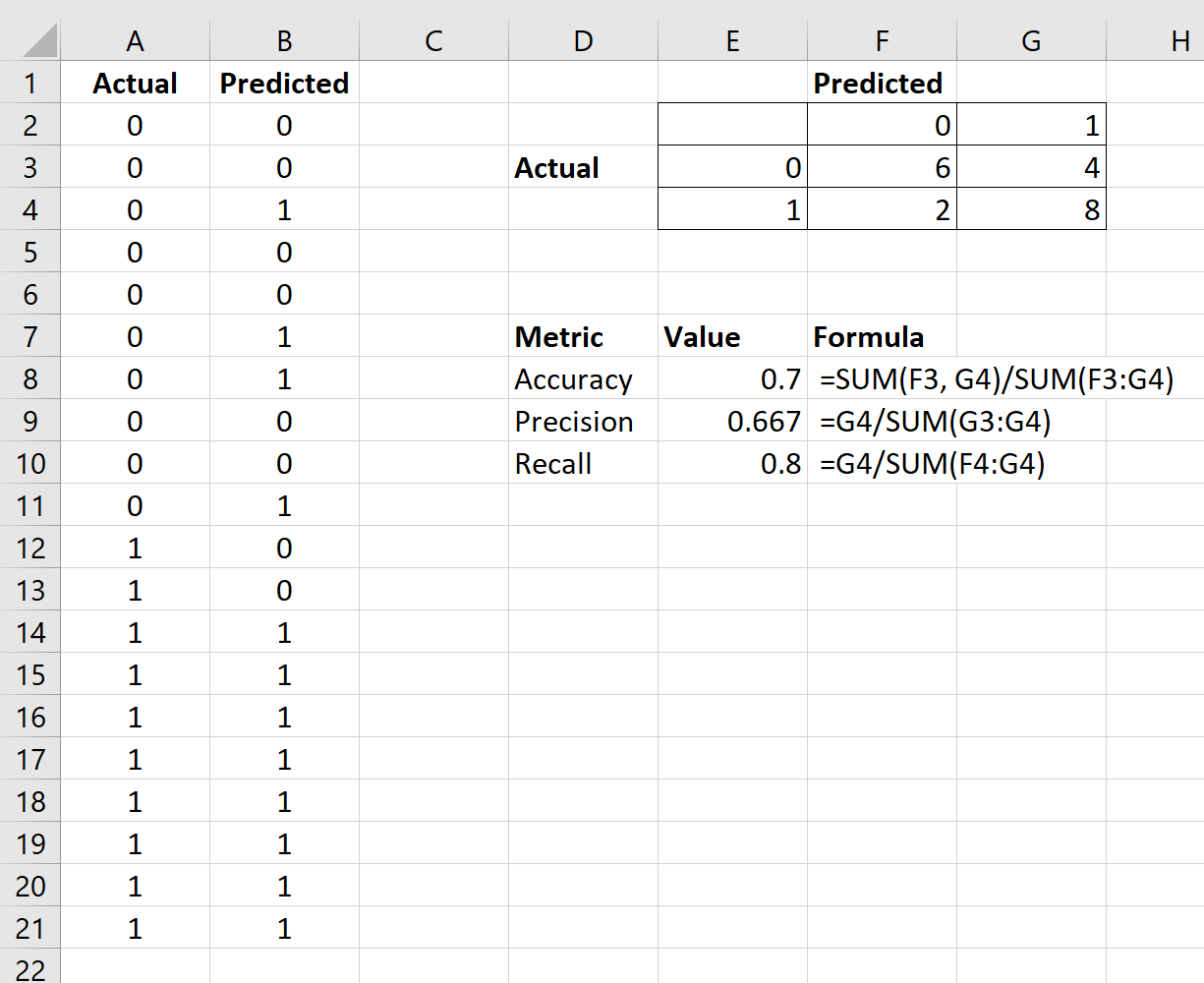
परिशुद्धता जितनी अधिक होगी, मॉडल उतना ही अधिक अवलोकनों को सही ढंग से वर्गीकृत करने में सक्षम होगा।
इस उदाहरण में, हमारे मॉडल की सटीकता 0.7 है जो हमें बताती है कि इसने 70% अवलोकनों को सही ढंग से वर्गीकृत किया है।
यदि हम चाहें, तो हम इस सटीकता की तुलना अन्य लॉजिस्टिक रिग्रेशन मॉडल से कर सकते हैं ताकि यह निर्धारित किया जा सके कि अवलोकनों को 0 या 1 की श्रेणियों में वर्गीकृत करने में कौन सा मॉडल सबसे अच्छा है।
अतिरिक्त संसाधन
लॉजिस्टिक रिग्रेशन का परिचय
लॉजिस्टिक रिग्रेशन के 3 प्रकार
लॉजिस्टिक रिग्रेशन बनाम लीनियर रिग्रेशन
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने