एसएएस में प्रोसी क्लस्टर का उपयोग कैसे करें (उदाहरण के साथ)
क्लस्टरिंग एक मशीन लर्निंग तकनीक है जो डेटा सेट के भीतर अवलोकनों के समूहों को खोजने का प्रयास करती है।
लक्ष्य ऐसे समूहों को ढूंढना है कि प्रत्येक क्लस्टर के भीतर अवलोकन एक-दूसरे के समान हों, जबकि विभिन्न समूहों में अवलोकन एक-दूसरे से काफी भिन्न हों।
एसएएस में क्लस्टरिंग करने का सबसे आसान तरीका PROC CLUSTER का उपयोग करना है।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में PROC CLUSTER का उपयोग कैसे करें।
उदाहरण: एसएएस में प्रोसी क्लस्टर का उपयोग कैसे करें
मान लें कि हमारे पास निम्नलिखित डेटासेट हैं जिसमें 20 अलग-अलग बास्केटबॉल खिलाड़ियों के लिए अंक, सहायता और रिबाउंड की जानकारी शामिल है:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
मान लीजिए कि हम एक-दूसरे के समान आंकड़ों वाले खिलाड़ियों के “समूहों” की पहचान करने के लिए कुछ समूह बनाना चाहते हैं।
निम्नलिखित कोड दिखाता है कि क्लस्टरिंग करने के लिए एसएएस में PROC क्लस्टर का उपयोग कैसे करें:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
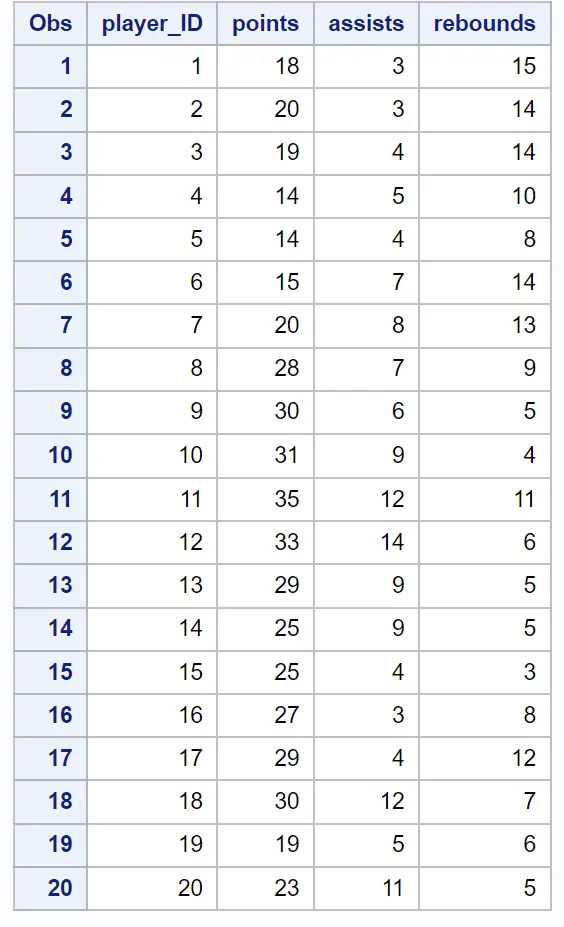
परिणाम की पहली सारणी यह जानकारी प्रदान करती है कि क्लस्टरिंग कैसे की गई:
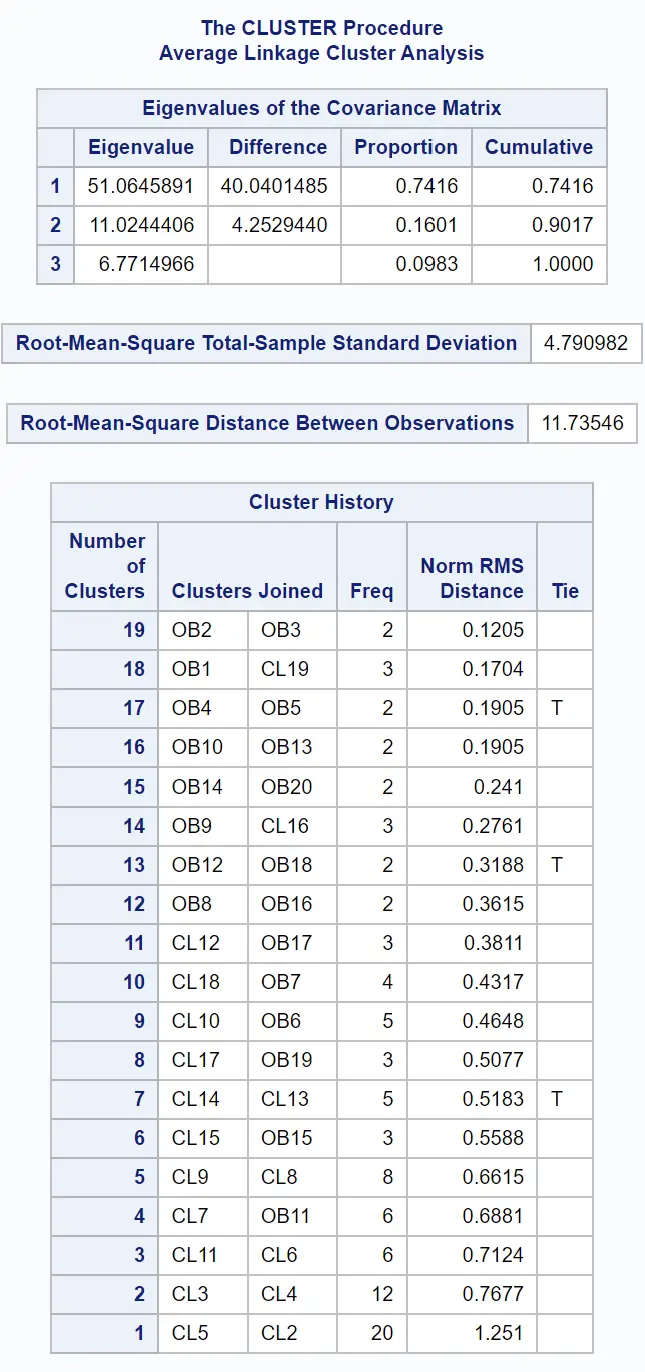
एक डेंड्रोग्राम भी तैयार किया जाता है ताकि हम डेटासेट में अवलोकनों के बीच समानता का निरीक्षण कर सकें:
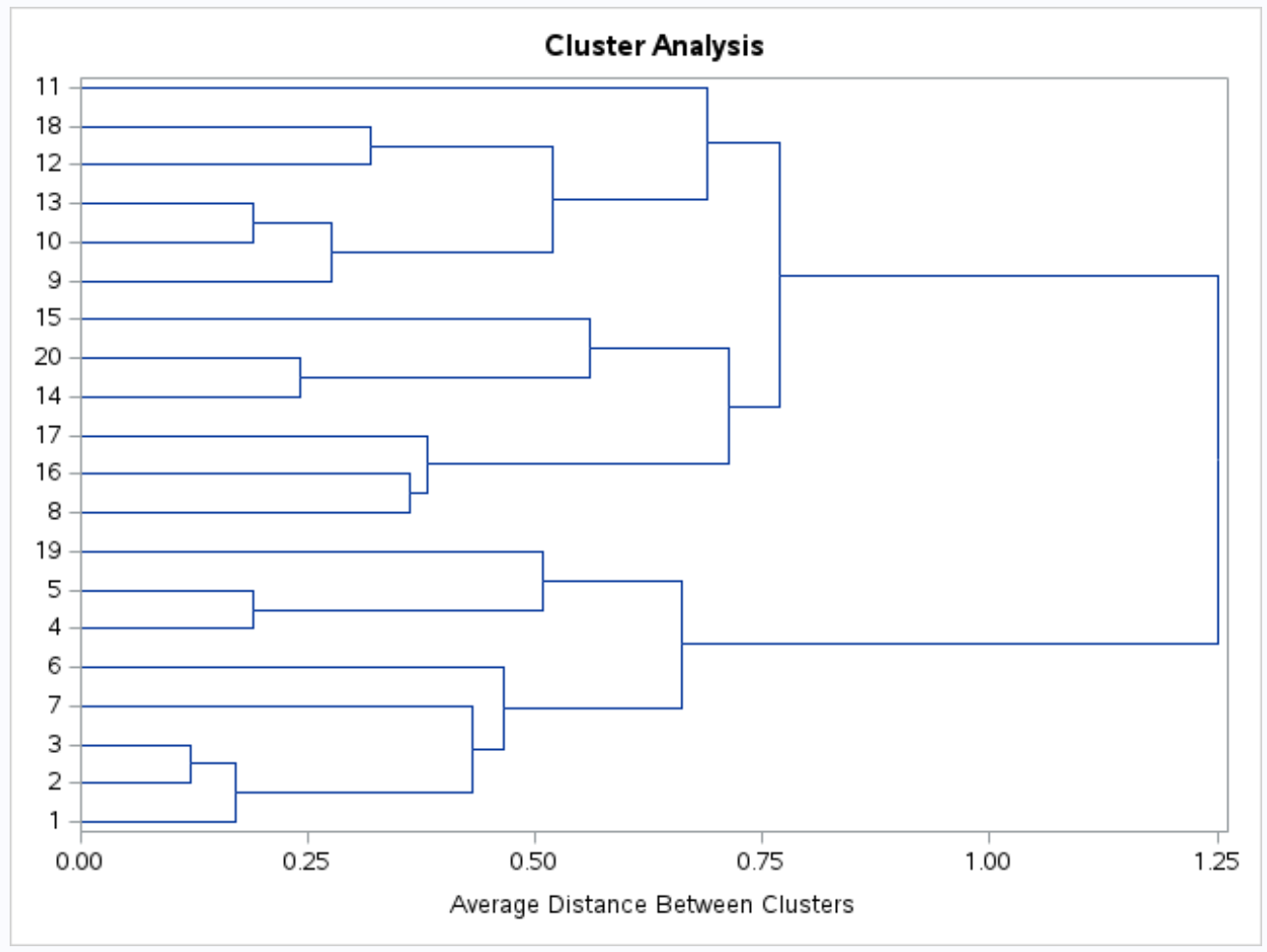
y-अक्ष व्यक्तिगत अवलोकन दिखाता है और x-अक्ष समूहों के बीच की औसत दूरी दिखाता है।
इस डेंड्रोग्राम को देखने से ऐसा प्रतीत होता है कि अवलोकन स्वाभाविक रूप से तीन समूहों में आते हैं:
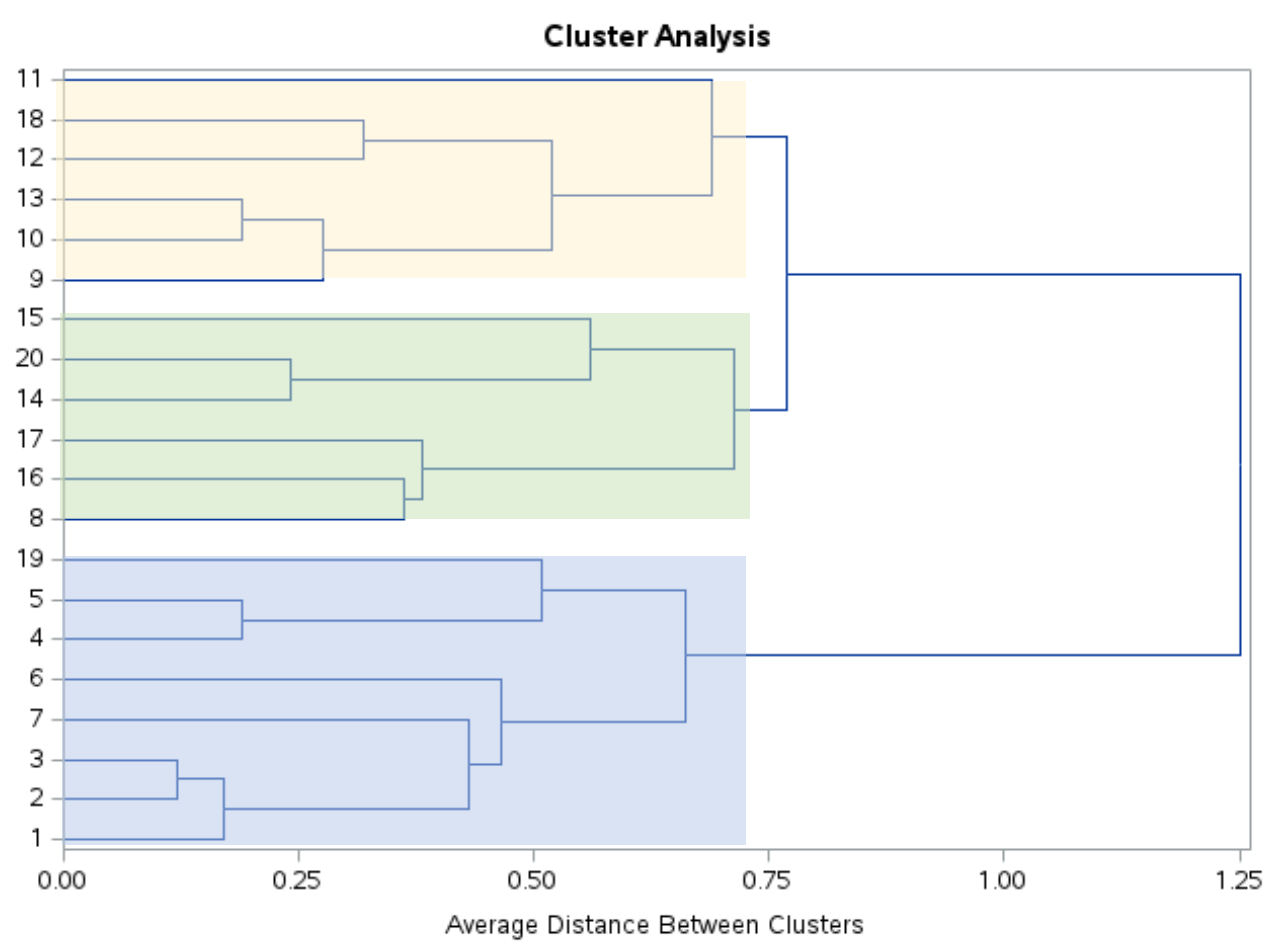
फिर हम एसएएस को मूल डेटासेट में प्रत्येक अवलोकन को तीन समूहों में से एक को निर्दिष्ट करने के लिए कहने के लिए ncl=3 के साथ PROC TREE स्टेटमेंट का उपयोग कर सकते हैं:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
परिणामी डेटासेट प्रत्येक मूल अवलोकन को उस क्लस्टर के साथ दिखाता है जिससे वे संबंधित हैं:
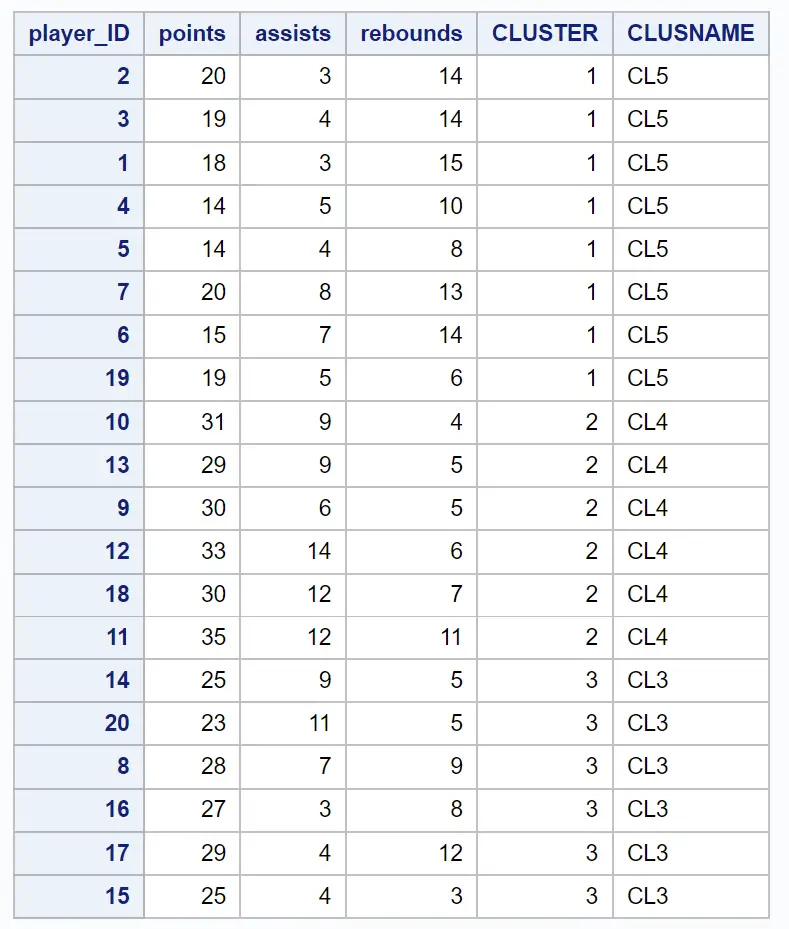
उदाहरण के लिए, हम देख सकते हैं: आईडी 2, 3, 1, 4, 5, 7, 6 और 19 वाले सभी खिलाड़ी क्लस्टर 1 से संबंधित हैं।
यह हमें बताता है कि ये आठ खिलाड़ी अंक, सहायता और रिबाउंड चर के मामले में “समान” हैं।
नोट : इस उदाहरण के लिए, हमने क्लस्टरिंग के लिए लिंकिंग विधि के रूप में औसत का उपयोग करना चुना। आपके द्वारा उपयोग की जा सकने वाली अन्य बाइंडिंग विधियों की पूरी सूची के लिए एसएएस दस्तावेज़ देखें।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि एसएएस में अन्य सामान्य कार्य कैसे करें:
एसएएस में प्रमुख घटक विश्लेषण कैसे करें
एसएएस में मल्टीपल लीनियर रिग्रेशन कैसे करें
एसएएस में लॉजिस्टिक रिग्रेशन कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने