एसएएस में सरल रैखिक प्रतिगमन कैसे करें
सरल रेखीय प्रतिगमन एक ऐसी तकनीक है जिसका उपयोग हम एक भविष्यवक्ता चर और एक प्रतिक्रिया चर के बीच संबंध को समझने के लिए कर सकते हैं।
यह तकनीक एक ऐसी पंक्ति ढूंढती है जो डेटा को सबसे अच्छी तरह से “फिट” करती है और निम्नलिखित रूप लेती है:
ŷ = बी 0 + बी 1 एक्स
सोना:
- ŷ : अनुमानित प्रतिक्रिया मूल्य
- बी 0 : प्रतिगमन रेखा की उत्पत्ति
- बी 1 : प्रतिगमन रेखा का ढलान
यह समीकरण हमें भविष्यवक्ता चर और प्रतिक्रिया चर के बीच संबंध को समझने में मदद करता है।
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि एसएएस में एक सरल रैखिक प्रतिगमन कैसे करें।
चरण 1: डेटा बनाएं
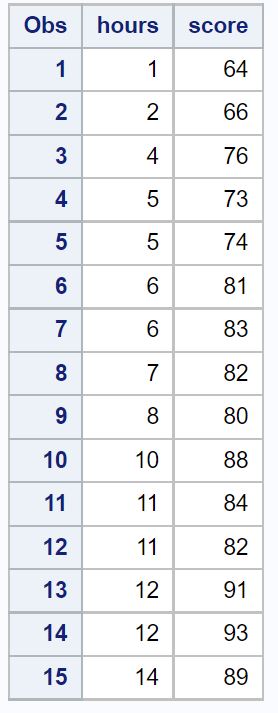
इस उदाहरण के लिए, हम एक डेटासेट बनाएंगे जिसमें अध्ययन किए गए घंटों की कुल संख्या और 15 छात्रों के अंतिम परीक्षा ग्रेड शामिल होंगे।
हम भविष्यवक्ता चर के रूप में घंटों और प्रतिक्रिया चर के रूप में स्कोर का उपयोग करके एक सरल रैखिक प्रतिगमन मॉडल फिट करेंगे।
निम्नलिखित कोड दिखाता है कि एसएएस में इस डेटासेट को कैसे बनाया जाए:
/*create dataset*/ data exam_data; input hours score; datalines ; 1 64 2 66 4 76 5 73 5 74 6 81 6 83 7 82 8 80 10 88 11 84 11 82 12 91 12 93 14 89 ; run ; /*view dataset*/ proc print data =exam_data;
चरण 2: सरल रैखिक प्रतिगमन मॉडल फिट करें
इसके बाद, हम सरल रैखिक प्रतिगमन मॉडल को फिट करने के लिए proc reg का उपयोग करेंगे:
/*fit simple linear regression model*/ proc reg data =exam_data; model score = hours; run ;
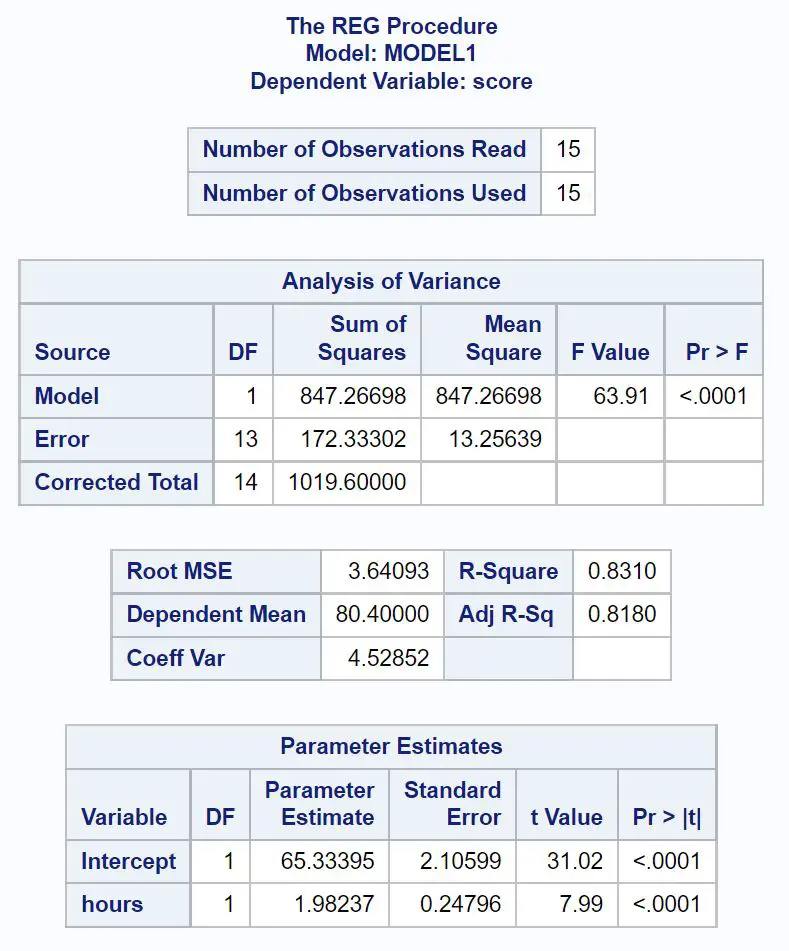
परिणाम में प्रत्येक तालिका से सबसे महत्वपूर्ण मानों की व्याख्या करने का तरीका यहां बताया गया है:
गैप विश्लेषण तालिका:
प्रतिगमन मॉडल का समग्र एफ-मान 63.91 है और संबंधित पी-मान <0.0001 है।
चूँकि यह पी-मान 0.05 से कम है, हम यह निष्कर्ष निकालते हैं कि समग्र रूप से प्रतिगमन मॉडल सांख्यिकीय रूप से महत्वपूर्ण है। दूसरे शब्दों में, परीक्षा परिणाम की भविष्यवाणी के लिए घंटे एक उपयोगी चर हैं।
मॉडल फ़िट तालिका:
आर-स्क्वायर मान हमें परीक्षा के अंकों में भिन्नता का प्रतिशत बताता है जिसे अध्ययन किए गए घंटों की संख्या से समझाया जा सकता है।
सामान्य तौर पर, प्रतिगमन मॉडल का आर-वर्ग मान जितना बड़ा होगा, प्रतिक्रिया चर के मूल्य की भविष्यवाणी करने में भविष्यवक्ता चर उतना ही बेहतर होगा।
इस मामले में, परीक्षा के अंकों में 83.1% भिन्नता को अध्ययन किए गए घंटों की संख्या से समझाया जा सकता है। यह मान काफी अधिक है, जो दर्शाता है कि अध्ययन किए गए घंटे परीक्षा परिणामों की भविष्यवाणी करने में एक बहुत ही उपयोगी चर है।
पैरामीटर अनुमान की तालिका:
इस तालिका से हम फिट प्रतिगमन समीकरण देख सकते हैं:
स्कोर = 65.33 + 1.98*(घंटे)
हम इसका अर्थ यह निकालते हैं कि अध्ययन किया गया प्रत्येक अतिरिक्त घंटा परीक्षा स्कोर में औसतन 1.98 अंक की वृद्धि से जुड़ा है।
मूल मान हमें बताता है कि शून्य घंटे तक अध्ययन करने वाले छात्र का औसत परीक्षा स्कोर 65.33 है।
हम इस समीकरण का उपयोग किसी छात्र द्वारा अध्ययन किए गए घंटों की संख्या के आधार पर अपेक्षित परीक्षा स्कोर खोजने के लिए भी कर सकते हैं।
उदाहरण के लिए, एक छात्र जो 10 घंटे पढ़ाई करता है, उसे 85.13 का परीक्षा स्कोर प्राप्त करना चाहिए:
स्कोर = 65.33 + 1.98*(10) = 85.13
चूँकि इस तालिका में घंटों के लिए पी-वैल्यू (<0.0001) 0.05 से कम है, हम निष्कर्ष निकालते हैं कि यह एक सांख्यिकीय रूप से महत्वपूर्ण भविष्यवक्ता चर है।
चरण 3: अवशिष्ट भूखंडों का विश्लेषण करें
सरल रैखिक प्रतिगमन मॉडल अवशेषों के बारे में दो महत्वपूर्ण धारणाएँ बनाता है:
- अवशेष सामान्य रूप से वितरित किये जाते हैं।
- भविष्यवक्ता चर के प्रत्येक स्तर पर अवशिष्टों में समान भिन्नता (” होमोसेडैस्टिसिटी “) होती है।
यदि ये धारणाएँ पूरी नहीं होती हैं, तो हमारे प्रतिगमन मॉडल के परिणाम विश्वसनीय नहीं हो सकते हैं।
यह सत्यापित करने के लिए कि ये धारणाएँ पूरी हुई हैं, हम उन अवशिष्ट प्लॉटों का विश्लेषण कर सकते हैं जिन्हें एसएएस स्वचालित रूप से आउटपुट में प्रदर्शित करता है:
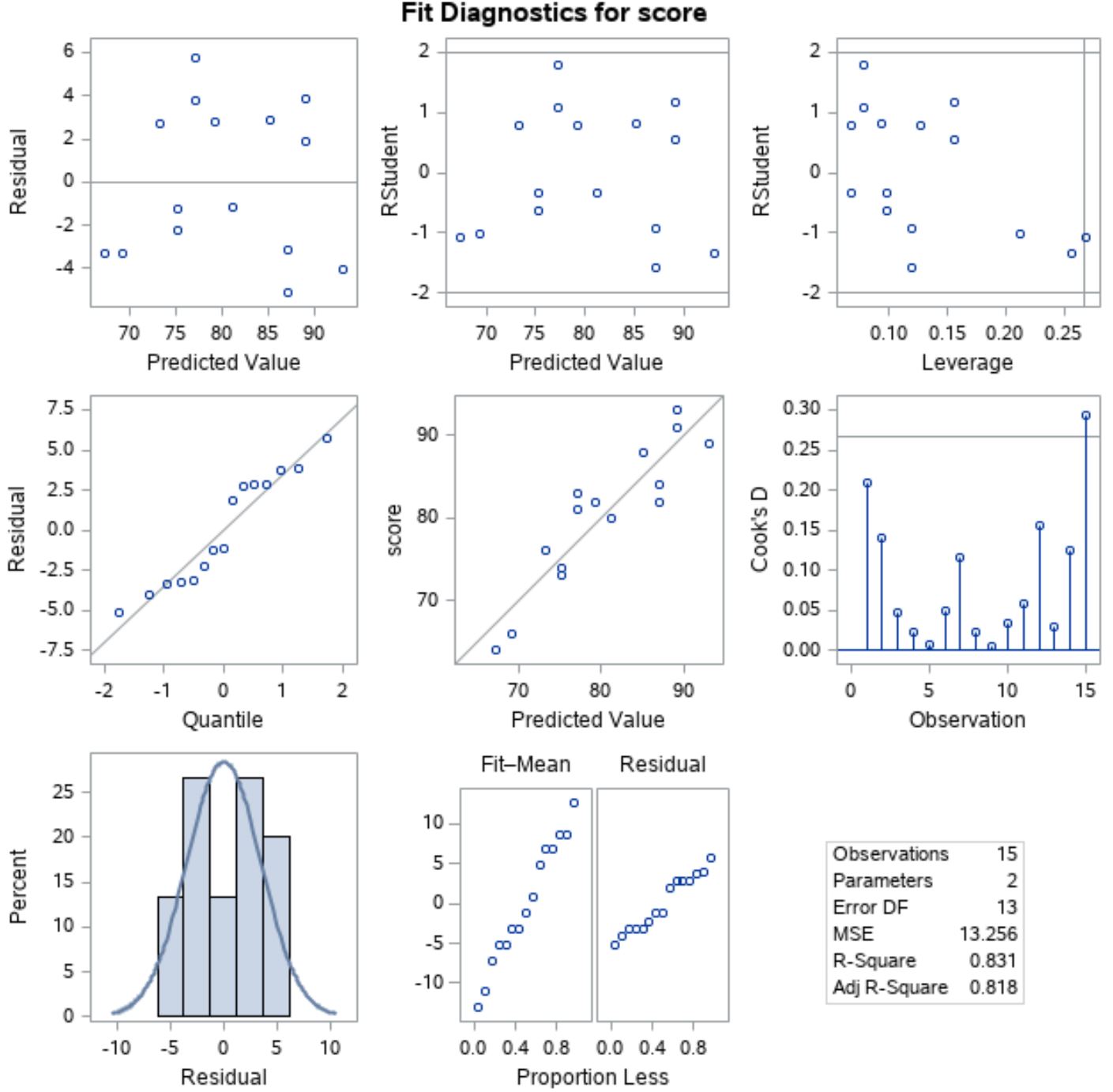
यह सत्यापित करने के लिए कि अवशेष सामान्य रूप से वितरित हैं, हम मध्य रेखा के बाईं स्थिति में x-अक्ष के साथ “क्वांटाइल” और y-अक्ष के साथ “अवशिष्ट” के साथ प्लॉट का विश्लेषण कर सकते हैं।
इस प्लॉट को QQ प्लॉट कहा जाता है, जो “क्वांटाइल-क्वांटाइल” के लिए संक्षिप्त है, और इसका उपयोग यह निर्धारित करने के लिए किया जाता है कि डेटा सामान्य रूप से वितरित किया गया है या नहीं। यदि डेटा सामान्य रूप से वितरित किया जाता है, तो QQ प्लॉट पर बिंदु एक सीधी विकर्ण रेखा पर स्थित होंगे।
ग्राफ़ से हम देख सकते हैं कि बिंदु लगभग एक सीधी विकर्ण रेखा पर स्थित हैं, इसलिए हम मान सकते हैं कि अवशेष सामान्य रूप से वितरित हैं।
इसके बाद, यह सत्यापित करने के लिए कि अवशेष समरूप हैं, हम पहली पंक्ति के बाईं स्थिति में x-अक्ष के साथ “अनुमानित मान” और y-अक्ष के साथ “अवशिष्ट” के साथ प्लॉट को देख सकते हैं।
यदि कथानक बिंदु बिना किसी स्पष्ट पैटर्न के शून्य के आसपास बेतरतीब ढंग से बिखरे हुए हैं, तो हम मान सकते हैं कि अवशेष समरूप हैं।
कथानक से हम देख सकते हैं कि बिंदु पूरे कथानक में प्रत्येक स्तर पर लगभग समान भिन्नता के साथ यादृच्छिक रूप से शून्य के आसपास बिखरे हुए हैं, इसलिए हम मान सकते हैं कि अवशेष समरूप हैं।
चूँकि दोनों धारणाएँ पूरी होती हैं, हम मान सकते हैं कि सरल रैखिक प्रतिगमन मॉडल के परिणाम विश्वसनीय हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि एसएएस में अन्य सामान्य कार्य कैसे करें:
एसएएस में वन-वे एनोवा कैसे निष्पादित करें
एसएएस में दो-तरफ़ा एनोवा कैसे निष्पादित करें
एसएएस में सहसंबंध की गणना कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने