कच्चा डेटा क्या माना जाता है? (परिभाषा एवं उदाहरण)
आंकड़ों में, कच्चा डेटा उस डेटा को संदर्भित करता है जो सीधे प्राथमिक स्रोत से एकत्र किया गया है और किसी भी तरह से संसाधित नहीं किया गया है।
किसी भी प्रकार के डेटा एनालिटिक्स प्रोजेक्ट में, पहला कदम कच्चा डेटा एकत्र करना है। एक बार जब यह डेटा एकत्र हो जाता है, तो इसे साफ किया जा सकता है, रूपांतरित किया जा सकता है, सारांशित किया जा सकता है और कल्पना की जा सकती है।
कच्चे डेटा को इकट्ठा करने का लाभ अंततः इसका उपयोग कुछ घटनाओं को बेहतर ढंग से समझने या एक प्रकार का पूर्वानुमान मॉडल बनाने के लिए करने में सक्षम होना है।
निम्नलिखित उदाहरण दिखाता है कि कच्चे डेटा को कैसे एकत्र किया जा सकता है और वास्तविक जीवन में उपयोग किया जा सकता है।
उदाहरण: कच्चे डेटा का संग्रह और उपयोग
खेल एक ऐसा क्षेत्र है जहां अक्सर कच्चा डेटा एकत्र किया जाता है। उदाहरण के लिए, पेशेवर बास्केटबॉल खिलाड़ियों से संबंधित विभिन्न आँकड़ों के लिए कच्चा डेटा एकत्र किया जा सकता है।
चरण 1: कच्चा डेटा एकत्र करें
कल्पना कीजिए कि एक बास्केटबॉल स्काउट एक पेशेवर बास्केटबॉल टीम के 10 खिलाड़ियों के लिए निम्नलिखित कच्चा डेटा एकत्र करता है: 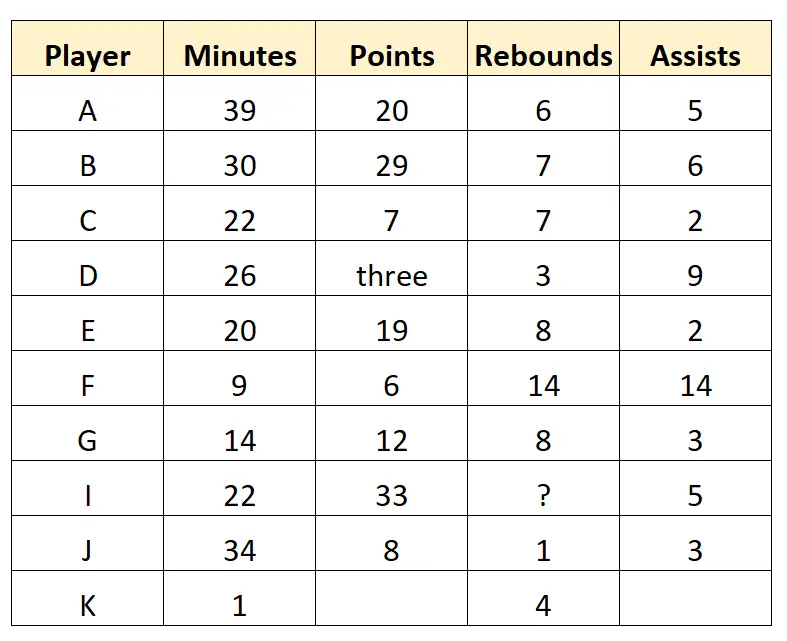
यह डेटासेट कच्चे डेटा का प्रतिनिधित्व करता है क्योंकि इसे सीधे स्काउट द्वारा एकत्र किया जाता है और इसे किसी भी तरह से साफ या संसाधित नहीं किया गया है।
चरण 2: कच्चा डेटा साफ़ करें
सारांश तालिकाओं, ग्राफ़, या कुछ और बनाने के लिए इस डेटा का उपयोग करने से पहले, स्काउट को पहले किसी भी लापता मान को हटाना होगा और किसी भी “गंदे” डेटा मान को साफ़ करना होगा।
उदाहरण के लिए, हम डेटासेट में कई मान देख सकते हैं जिन्हें बदलने या हटाने की आवश्यकता है:
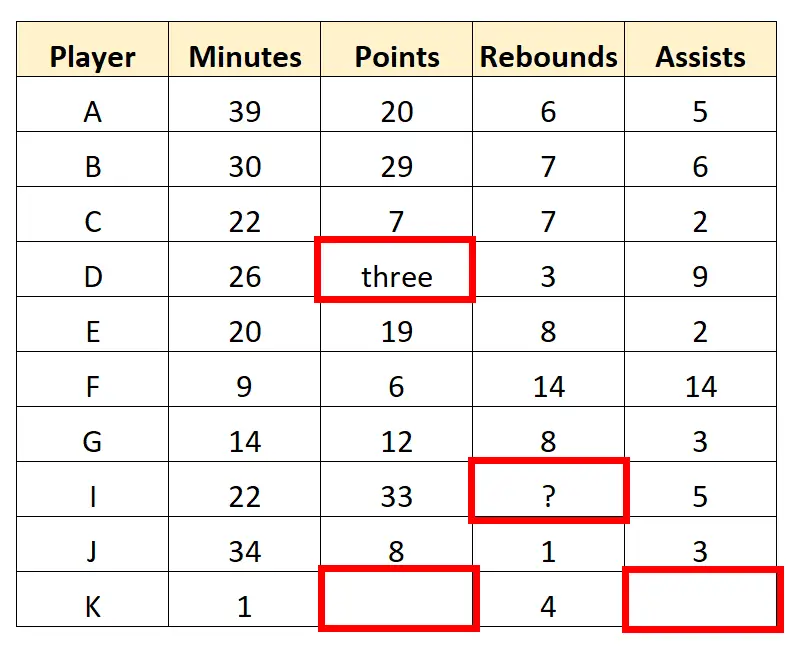
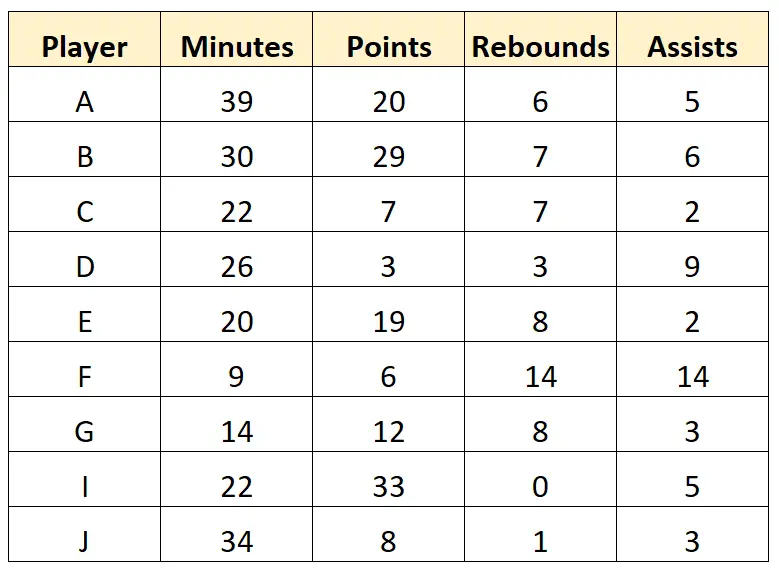
स्काउट अंतिम पंक्ति को पूरी तरह से हटाने का निर्णय ले सकता है क्योंकि इसमें कई गायब मान हैं। इसके बाद यह निम्नलिखित “स्वच्छ” डेटा प्राप्त करने के लिए डेटासेट में वर्ण मानों को साफ़ कर सकता है:
चरण 3: डेटा को सारांशित करें
एक बार डेटा साफ हो जाने के बाद, स्काउट डेटासेट में प्रत्येक चर का सारांश दे सकता है। उदाहरण के लिए, यह “मिनट” चर के लिए निम्नलिखित सारांश आंकड़ों की गणना कर सकता है:
- औसत : 24 मिनट
- माध्यिका : 22 मिनट
- मानक विचलन : 9.45 मिनट
चरण 4: डेटा को विज़ुअलाइज़ करें
डेटा मूल्यों को बेहतर ढंग से समझने के लिए स्काउट डेटासेट में चर की कल्पना कर सकता है।
उदाहरण के लिए, वह प्रत्येक खिलाड़ी द्वारा खेले गए कुल मिनटों की कल्पना करने के लिए निम्नलिखित बार चार्ट बना सकता है:
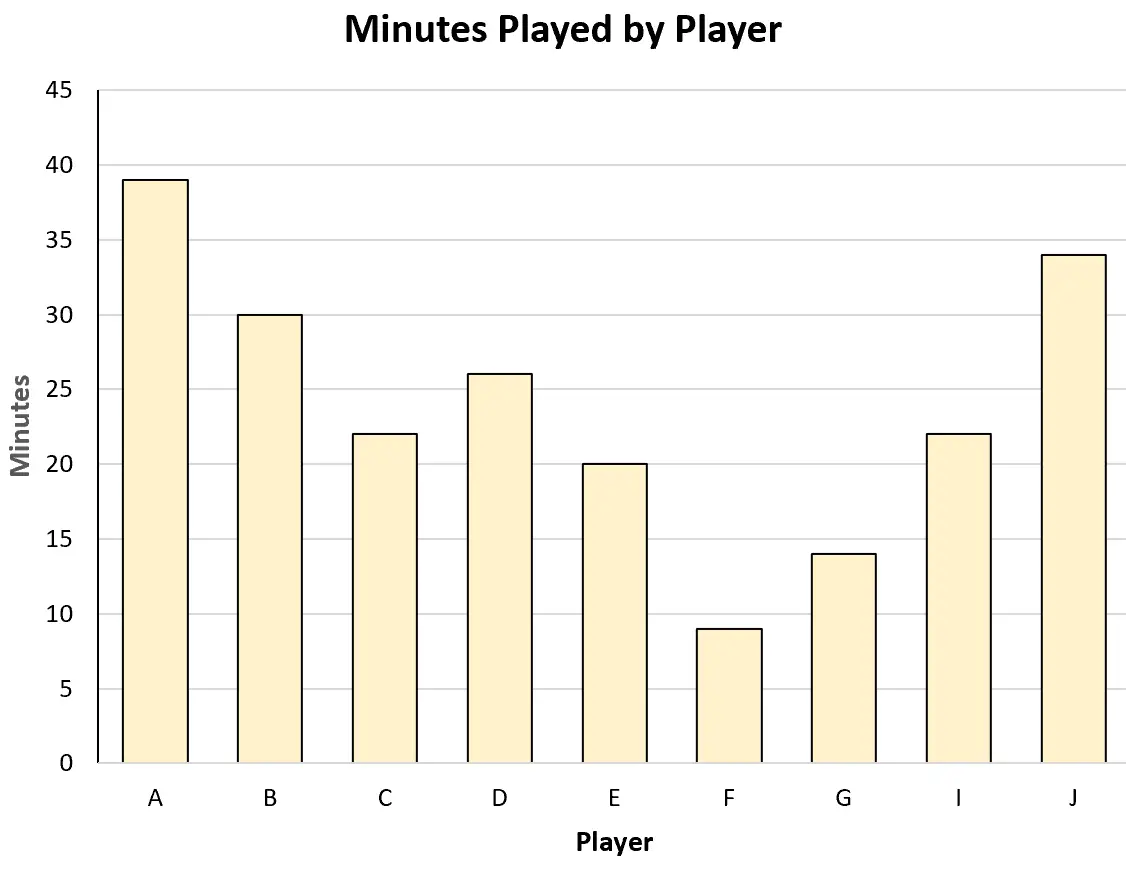
या वह खेले गए मिनटों और अर्जित अंकों के बीच संबंध की कल्पना करने के लिए निम्नलिखित स्कैटरप्लॉट बना सकता है:
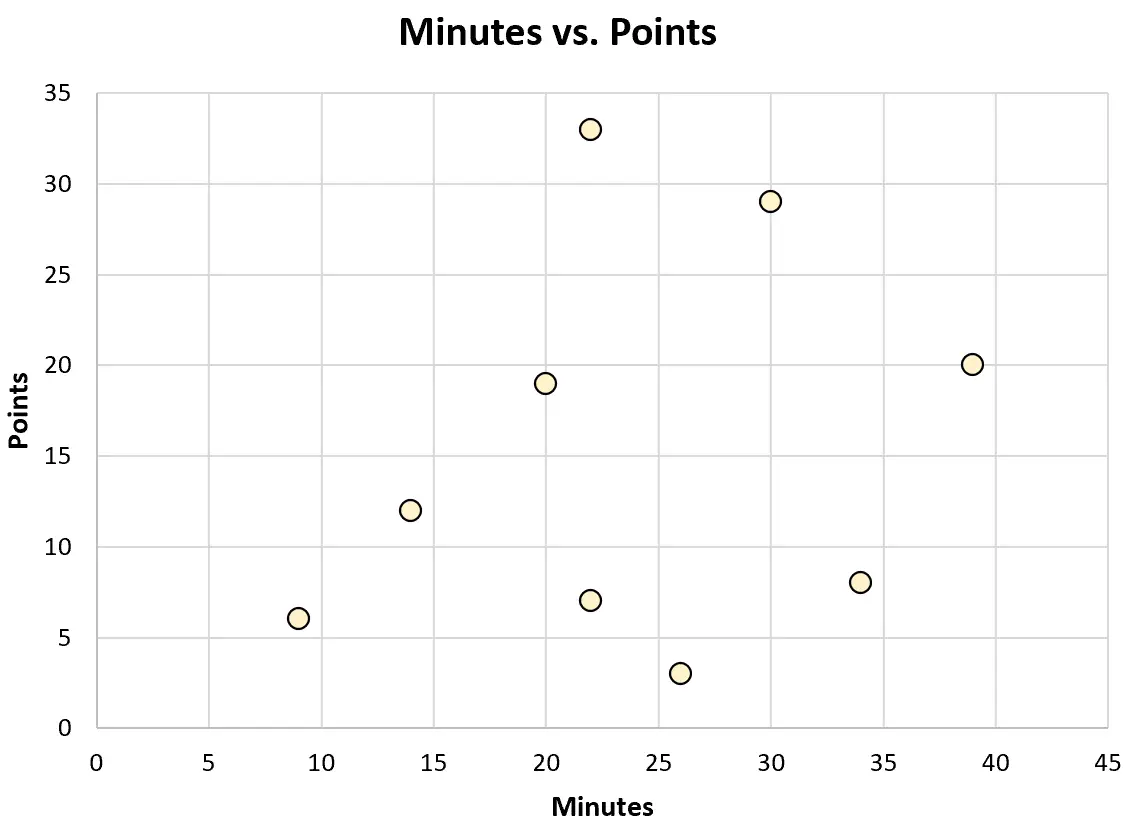
इस प्रकार के प्रत्येक चार्ट उसे डेटा को बेहतर ढंग से समझने में मदद कर सकते हैं।
चरण 5: मॉडल बनाने के लिए डेटा का उपयोग करें
अंत में, एक बार डेटा साफ हो जाने के बाद, स्काउट कुछ प्रकार के पूर्वानुमानित मॉडल को अनुकूलित करने का निर्णय ले सकता है।
उदाहरण के लिए, यह एक सरल रैखिक प्रतिगमन मॉडल में फिट हो सकता है और प्रत्येक खिलाड़ी द्वारा बनाए गए कुल अंकों की भविष्यवाणी करने के लिए खेले गए मिनटों का उपयोग कर सकता है।
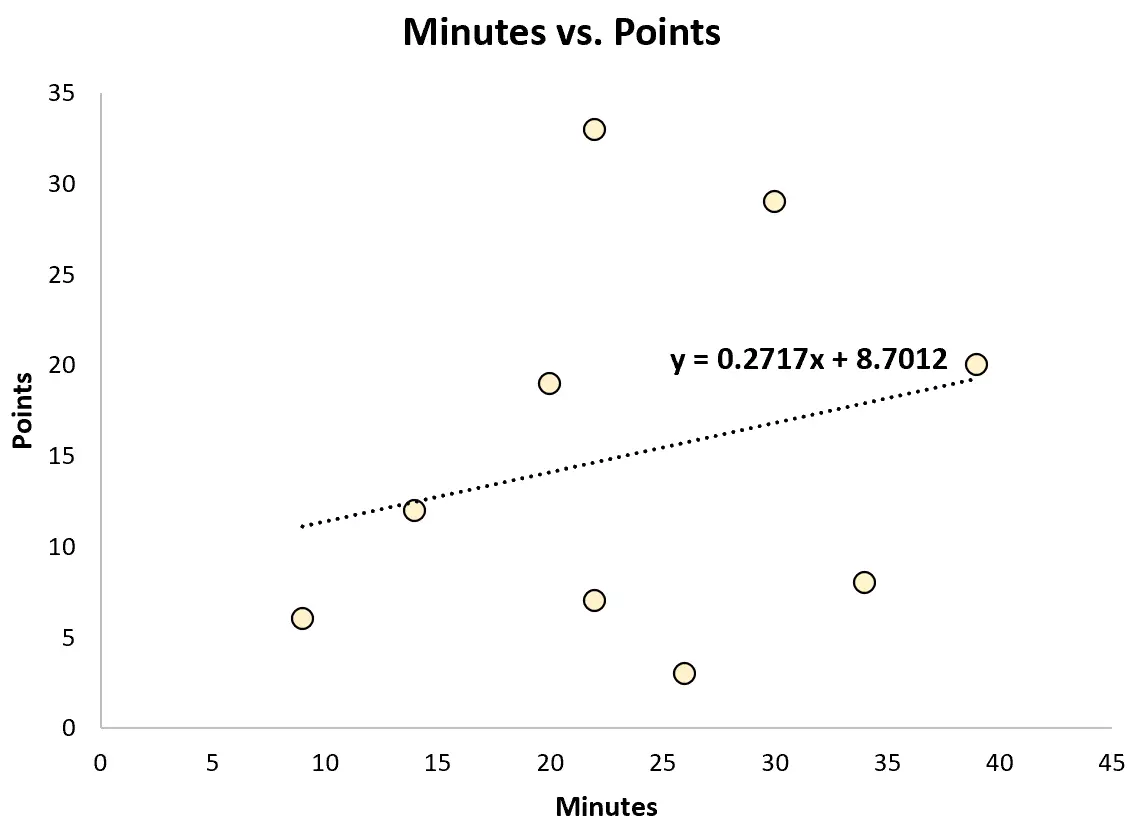
फिट प्रतिगमन समीकरण है:
अंक = 8.7012 + 0.2717*(मिनट)
स्काउट इस समीकरण का उपयोग यह अनुमान लगाने के लिए कर सकता है कि खिलाड़ी खेले गए मिनटों की संख्या के आधार पर कितने अंक अर्जित करेगा। उदाहरण के लिए, एक एथलीट जो 30 मिनट खेलता है उसे 16.85 अंक प्राप्त करने चाहिए:
अंक = 8.7012 + 0.2717*(30) = 16.85
अतिरिक्त संसाधन
आँकड़े क्यों महत्वपूर्ण हैं?
सांख्यिकी में नमूना आकार क्यों महत्वपूर्ण है?
सांख्यिकी में अवलोकन क्या है?
सांख्यिकी में सारणीबद्ध डेटा क्या हैं?
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने