कोचरन का q परीक्षण क्या है? (परिभाषा & #038; उदाहरण)
कोचरन का क्यू परीक्षण एक सांख्यिकीय परीक्षण है जिसका उपयोग यह निर्धारित करने के लिए किया जाता है कि क्या “सफलताओं” का अनुपात तीन या अधिक समूहों में बराबर है जिसमें प्रत्येक समूह में समान व्यक्ति दिखाई देते हैं।
उदाहरण के लिए, हम यह निर्धारित करने के लिए कोचरन के क्यू परीक्षण का उपयोग कर सकते हैं कि तीन अलग-अलग अध्ययन तकनीकों का उपयोग करते समय परीक्षा उत्तीर्ण करने वाले छात्रों का अनुपात बराबर है या नहीं।
कोचरन का क्यू टेस्ट करने के चरण
कोचरन का क्यू परीक्षण निम्नलिखित शून्य और वैकल्पिक परिकल्पनाओं का उपयोग करता है:
शून्य परिकल्पना (एच 0 ): सभी समूहों में “सफलताओं” का अनुपात समान है
वैकल्पिक परिकल्पना ( एचए ): कम से कम एक समूह में “सफलताओं” का अनुपात भिन्न है
परीक्षण आँकड़े की गणना इस प्रकार की जाती है:
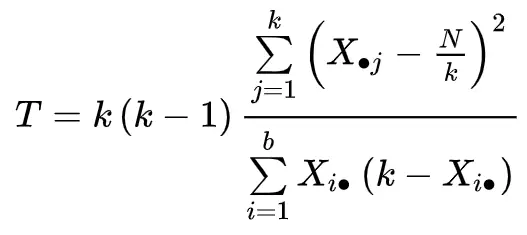
सोना:
- k: उपचारों की संख्या (या “समूह”)
- एक्सजे: जेवें उपचार के लिए कॉलम का कुल
- बी: ब्लॉक की संख्या
- शी. : ith ब्लॉक के लिए लाइन का कुल योग
- एन: कुल योग
टी परीक्षण आँकड़ा स्वतंत्रता की k-1 डिग्री के साथ ची-स्क्वायर वितरण का अनुसरण करता है।
यदि परीक्षण आँकड़ों से जुड़ा पी-मूल्य एक निश्चित स्तर के महत्व से नीचे है (जैसे कि α = 0.05), तो हम शून्य परिकल्पना को अस्वीकार कर सकते हैं और निष्कर्ष निकाल सकते हैं कि हमारे पास यह कहने के लिए पर्याप्त सबूत हैं कि “सफलताओं” का अनुपात अलग है कम से कम एक समूह.
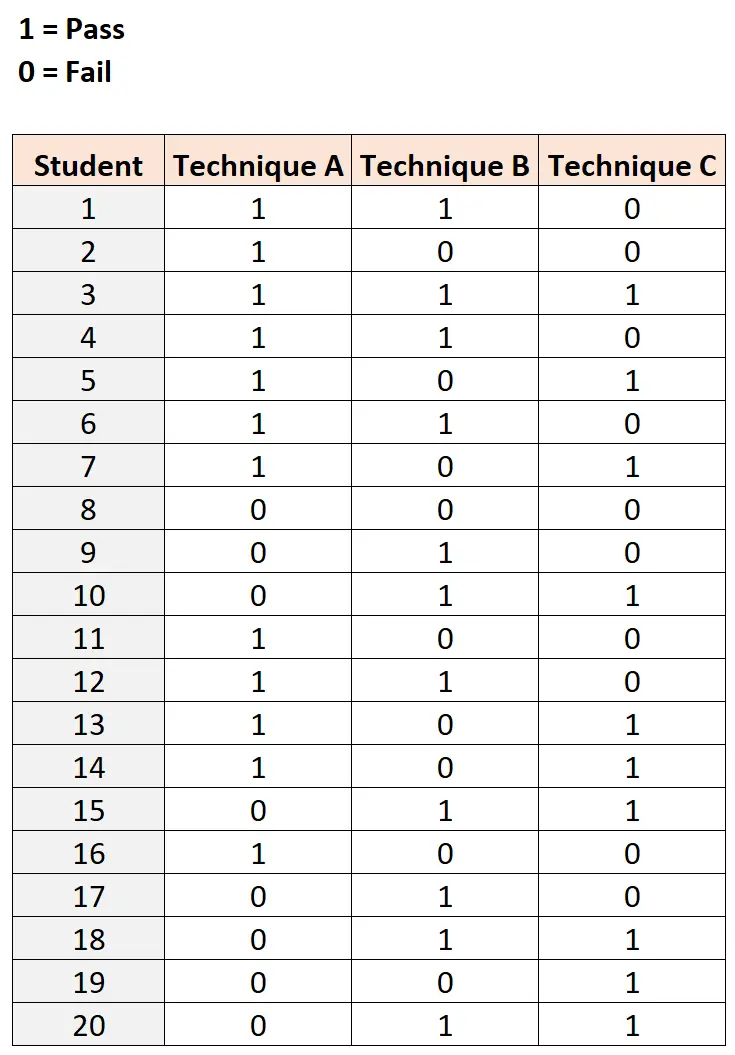
उदाहरण: कोचरन का क्यू परीक्षण
मान लीजिए कि एक शोधकर्ता जानना चाहता है कि क्या तीन अलग-अलग अध्ययन तकनीकों से छात्रों के बीच सफलता दर का अनुपात अलग-अलग होता है।
इसका परीक्षण करने के लिए, वह 20 छात्रों को भर्ती करती है, जिनमें से प्रत्येक तीन अलग-अलग अध्ययन तकनीकों का उपयोग करके समान कठिनाई की परीक्षा देते हैं। परिणाम नीचे दर्शाए गए है:
कोचरन का क्यू परीक्षण करने के लिए, हम सांख्यिकीय सॉफ़्टवेयर का उपयोग कर सकते हैं क्योंकि इसे मैन्युअल रूप से निष्पादित करना कठिन हो सकता है।
यहां वह कोड है जिसका उपयोग हम इस डेटासेट को बनाने और आर सांख्यिकीय प्रोग्रामिंग भाषा में कोचरन के क्यू परीक्षण को करने के लिए कर सकते हैं:
#load DescTools package library (DescTools) #create dataset df <- data.frame(student= rep (1:20, each = 3 ), technique= rep (c('A', 'B', 'C'), times= 20 ), outcome=c(1, 1, 0, 1, 0, 0, 1, 1, 1, 1, 1, 0, 1, 0, 1, 1, 1, 0, 1, 0, 1, 0, 0, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 1, 0, 1, 1, 1, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 1, 0, 1, 1)) #perform Cochran's Q test CochranQTest(outcome ~ technique| student, data=df) Cochran's Q test data: outcome and technique and student Q = 0.33333, df = 2, p-value = 0.8465
परीक्षण परिणाम से हम निम्नलिखित देख सकते हैं:
- परीक्षण आँकड़ा 0.333 है
- संगत पी-मान 0.8465 है
चूँकि यह पी-मान 0.05 से कम नहीं है, हम शून्य परिकल्पना को अस्वीकार करने में विफल रहते हैं।
इसका मतलब यह है कि हमारे पास यह कहने के लिए पर्याप्त सबूत नहीं हैं कि छात्रों द्वारा उपयोग की जाने वाली अध्ययन तकनीक से सफलता दर के विभिन्न अनुपात होते हैं।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने