पायथन में क्यूबिक रिग्रेशन कैसे करें
क्यूबिक रिग्रेशन एक प्रकार का रिग्रेशन है जिसका उपयोग हम भविष्यवक्ता चर और प्रतिक्रिया चर के बीच संबंध को मापने के लिए कर सकते हैं जब चर के बीच संबंध गैर-रेखीय होता है।
यह ट्यूटोरियल बताता है कि पायथन में क्यूबिक रिग्रेशन कैसे करें।
उदाहरण: पायथन में घन प्रतिगमन
मान लीजिए कि हमारे पास निम्नलिखित पांडा डेटाफ़्रेम है जिसमें दो चर (x और y) हैं:
import pandas as pd #createDataFrame df = pd. DataFrame ({' x ': [6, 9, 12, 16, 22, 28, 33, 40, 47, 51, 55, 60], ' y ': [14, 28, 50, 64, 67, 57, 55, 57, 68, 74, 88, 110]}) #view DataFrame print (df) xy 0 6 14 1 9 28 2 12 50 3 16 64 4 22 67 5 28 57 6 33 55 7 40 57 8 47 68 9 51 74 10 55 88 11 60 110
यदि हम इस डेटा का एक सरल स्कैटरप्लॉट बनाते हैं, तो हम देख सकते हैं कि दो चर के बीच का संबंध गैर-रैखिक है:
import matplotlib. pyplot as plt
#create scatterplot
plt. scatter (df. x , df. y )
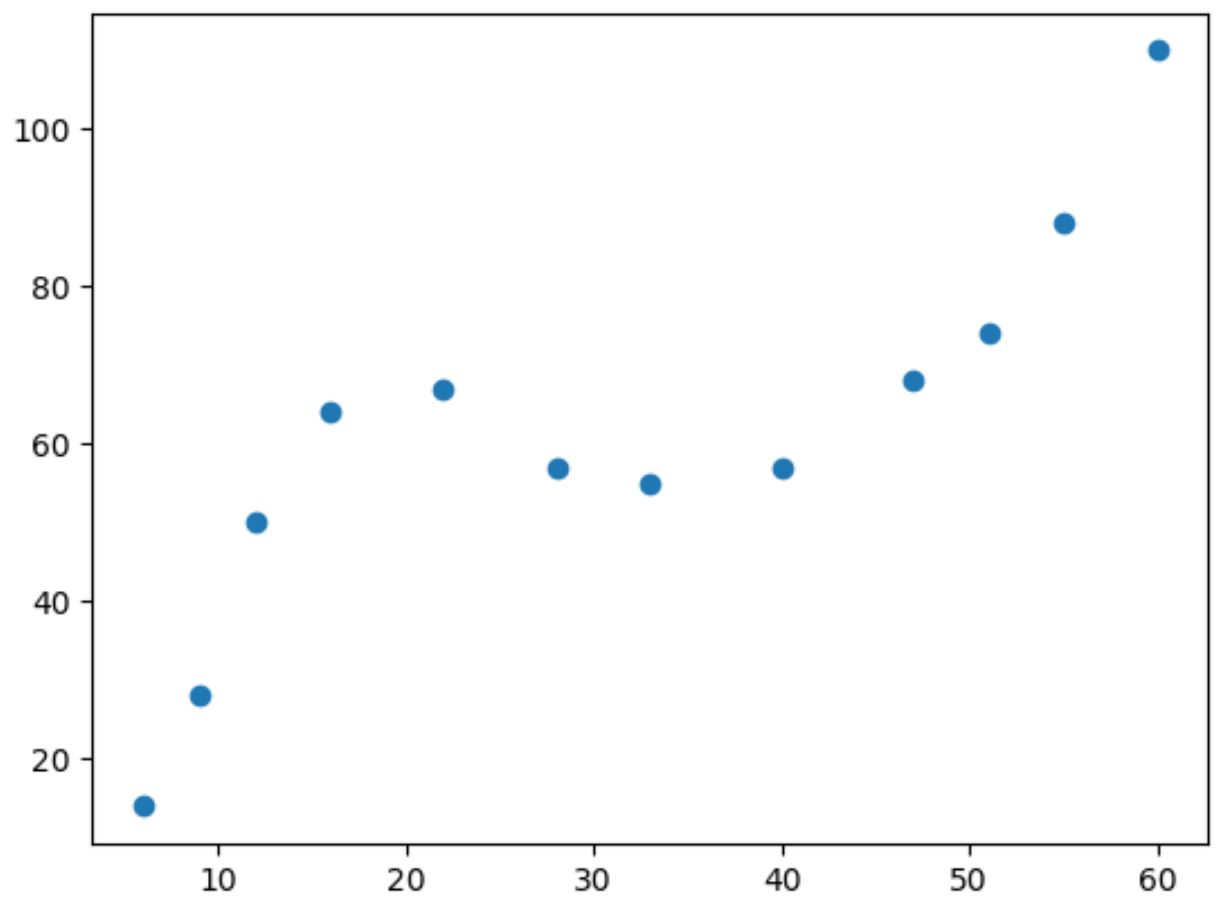
जैसे-जैसे x का मान बढ़ता है, y एक निश्चित बिंदु तक बढ़ता है, फिर घटता है, फिर बढ़ता है।
कथानक में दो “वक्रों” वाला यह पैटर्न दो चरों के बीच घन संबंध का संकेत है।
इसका मतलब यह है कि एक घन प्रतिगमन मॉडल दो चर के बीच संबंध को मापने के लिए एक अच्छा उम्मीदवार है।
घन प्रतिगमन करने के लिए, हम numpy.polyfit() फ़ंक्शन का उपयोग करके डिग्री 3 के साथ एक बहुपद प्रतिगमन मॉडल फिट कर सकते हैं:
import numpy as np #fit cubic regression model model = np. poly1d (np. polyfit (df. x , df. y , 3)) #add fitted cubic regression line to scatterplot polyline = np. linspace (1, 60, 50) plt. scatter (df. x , df. y ) plt. plot (polyline, model(polyline)) #add axis labels plt. xlabel (' x ') plt. ylabel (' y ') #displayplot plt. show ()
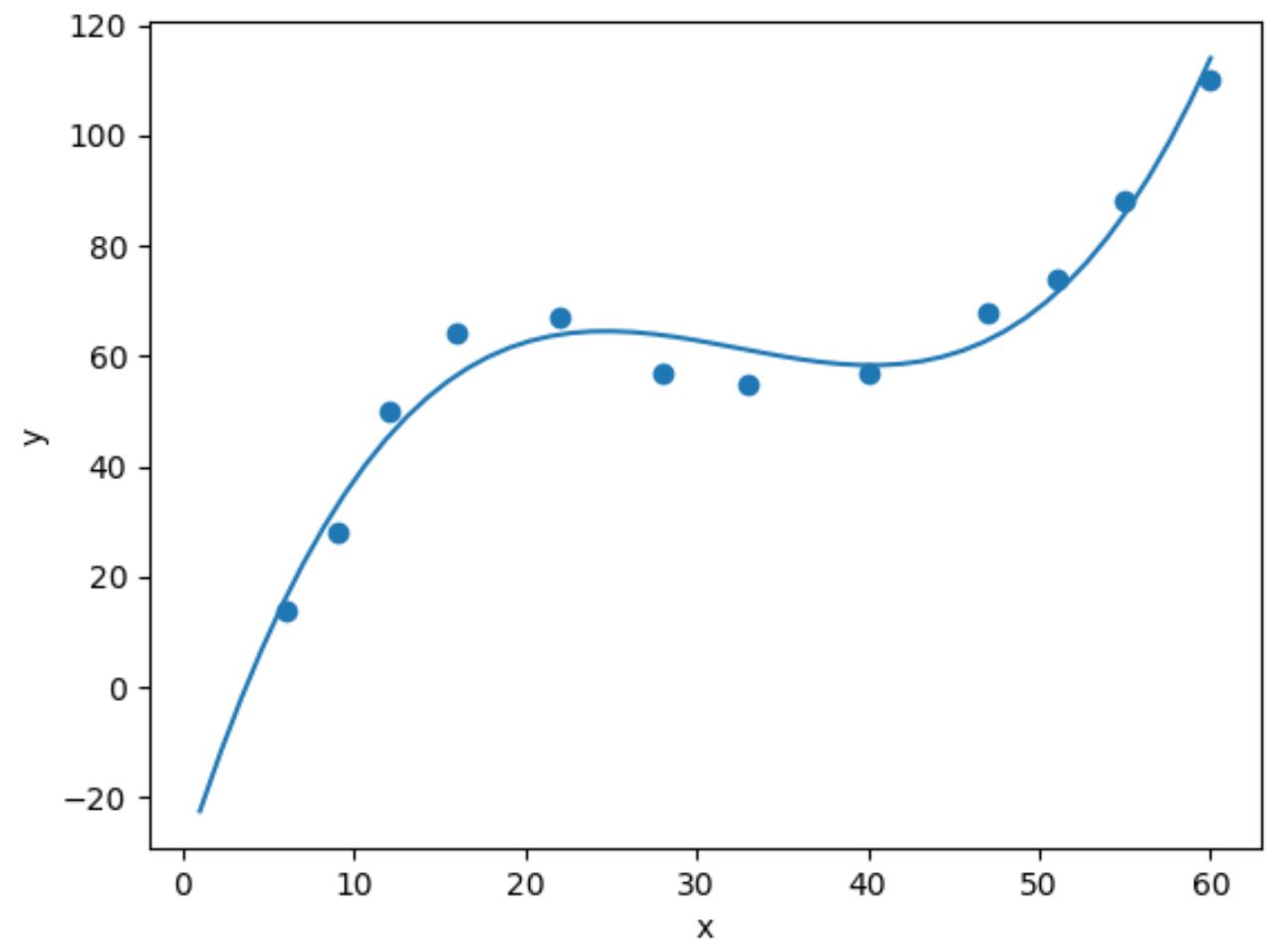
हम मॉडल गुणांकों को प्रिंट करके फिटेड क्यूबिक रिग्रेशन समीकरण प्राप्त कर सकते हैं:
print (model)
3 2
0.003302x - 0.3214x + 9.832x - 32.01
फिटेड क्यूबिक रिग्रेशन समीकरण है:
y = 0.003302(x) 3 – 0.3214(x) 2 + 9.832x – 30.01
हम x के मान के आधार पर y के अपेक्षित मान की गणना करने के लिए इस समीकरण का उपयोग कर सकते हैं।
उदाहरण के लिए, यदि x 30 है, तो y के लिए अपेक्षित मान 64.844 है:
y = 0.003302(30) 3 – 0.3214(30) 2 + 9.832(30) – 30.01 = 64.844
हम मॉडल का आर-वर्ग प्राप्त करने के लिए एक छोटा फ़ंक्शन भी लिख सकते हैं, जो प्रतिक्रिया चर में भिन्नता का अनुपात है जिसे भविष्यवक्ता चर द्वारा समझाया जा सकता है।
#define function to calculate r-squared def polyfit(x, y, degree): results = {} coeffs = np. polyfit (x, y, degree) p = np. poly1d (coeffs) #calculate r-squared yhat = p(x) ybar = np. sum (y)/len(y) ssreg = np. sum ((yhat-ybar) ** 2) sstot = np. sum ((y - ybar) ** 2) results[' r_squared '] = ssreg / sstot return results #find r-squared of polynomial model with degree = 3 polyfit(df. x , df. y , 3) {'r_squared': 0.9632469890057967}
इस उदाहरण में, मॉडल का आर वर्ग 0.9632 है।
इसका मतलब यह है कि प्रतिक्रिया चर में 96.32% भिन्नता को भविष्यवक्ता चर द्वारा समझाया जा सकता है।
चूँकि यह मान इतना अधिक है, यह हमें बताता है कि घन प्रतिगमन मॉडल दो चर के बीच संबंध को अच्छी तरह से मापता है।
संबंधित: एक अच्छा आर-वर्ग मान क्या है?
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पायथन में अन्य सामान्य कार्य कैसे करें:
पायथन में सरल रैखिक प्रतिगमन कैसे करें
पायथन में द्विघात प्रतिगमन कैसे करें
पायथन में बहुपद प्रतिगमन कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने