सामान्यता की जांच करने के लिए qq प्लॉट का उपयोग कैसे करें
एक QQ प्लॉट, जिसका संक्षिप्त रूप “क्वांटाइल-क्वांटाइल” है, का उपयोग यह मूल्यांकन करने के लिए किया जाता है कि डेटा सेट संभावित रूप से सैद्धांतिक वितरण से आता है या नहीं।
ज्यादातर मामलों में, इस प्रकार के प्लॉट का उपयोग यह निर्धारित करने के लिए किया जाता है कि डेटा सेट सामान्य वितरण का पालन करता है या नहीं।
यदि डेटा सामान्य रूप से वितरित किया जाता है, तो QQ प्लॉट पर बिंदु एक सीधी विकर्ण रेखा पर स्थित होंगे।
इसके विपरीत, ग्राफ़ पर जितने अधिक महत्वपूर्ण बिंदु एक सीधी विकर्ण रेखा से विचलित होते हैं, डेटा सेट के सामान्य वितरण का पालन करने की संभावना उतनी ही कम होती है।
निम्नलिखित उदाहरण दिखाते हैं कि सामान्यता की जांच के लिए आर में क्यूक्यू प्लॉट कैसे बनाएं।
उदाहरण 1: सामान्य डेटा के लिए QQ प्लॉट
निम्नलिखित कोड दिखाता है कि 200 अवलोकनों के साथ सामान्य रूप से वितरित डेटासेट कैसे उत्पन्न किया जाए और आर में डेटासेट के लिए क्यूक्यू प्लॉट कैसे बनाया जाए:
#make this example reproducible set. seeds (1) #create some fake data that follows a normal distribution data <- rnorm(200) #create QQ plot qqnorm(data) qqline(data)
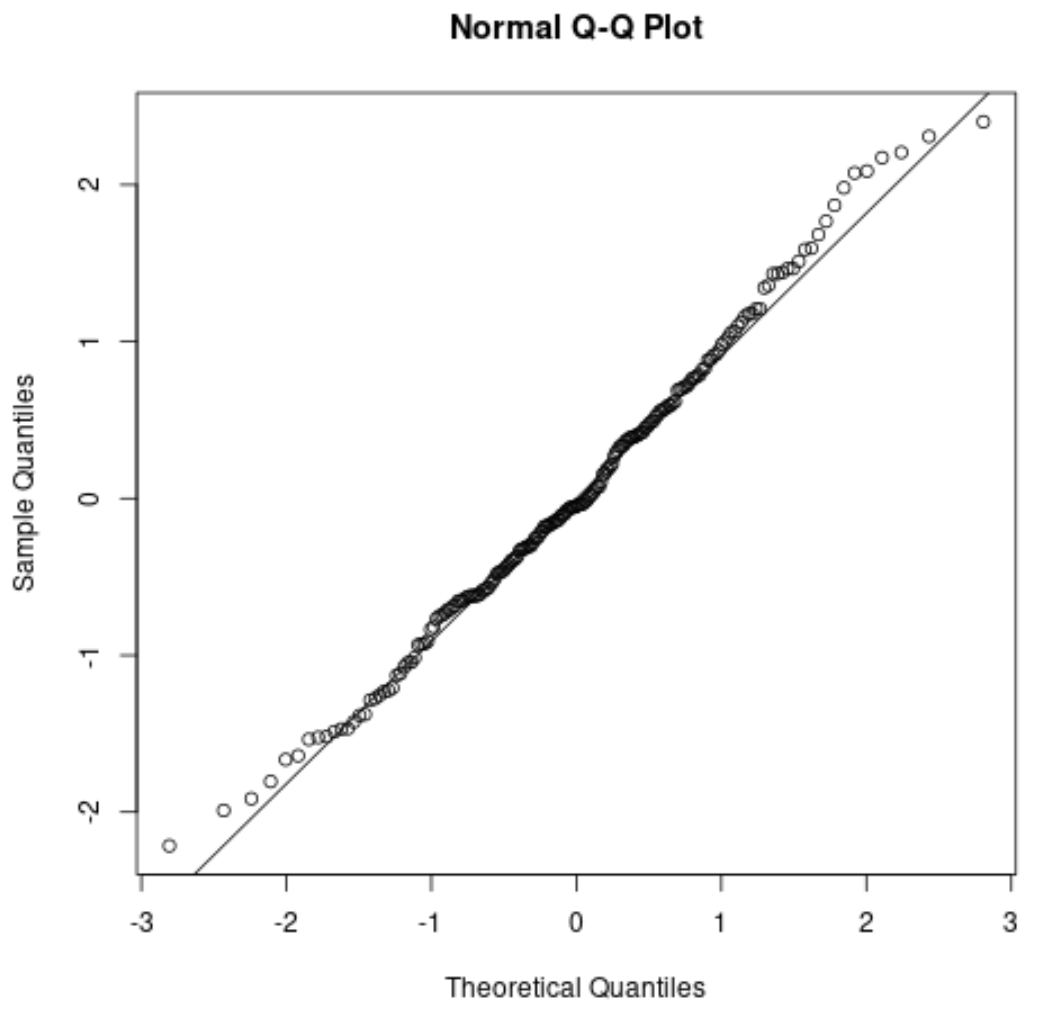
हम देख सकते हैं कि बिंदु मुख्य रूप से सीधी विकर्ण रेखा के साथ-साथ प्रत्येक पूंछ के साथ कुछ मामूली विचलन के साथ स्थित हैं।
इस ग्राफ़ के आधार पर, हम सुरक्षित रूप से मान सकते हैं कि यह डेटासेट सामान्य रूप से वितरित है।
उदाहरण 2: गैर-सामान्य डेटा के लिए QQ प्लॉट
निम्नलिखित कोड दिखाता है कि डेटा सेट के लिए QQ प्लॉट कैसे बनाया जाए जो 200 अवलोकनों के साथ एक घातांकीय वितरण का अनुसरण करता है:
#make this example reproducible set. seeds (1) #create some fake data that follows an exponential distribution data <- rexp(200, rate=3) #create QQ plot qqnorm(data) qqline(data)
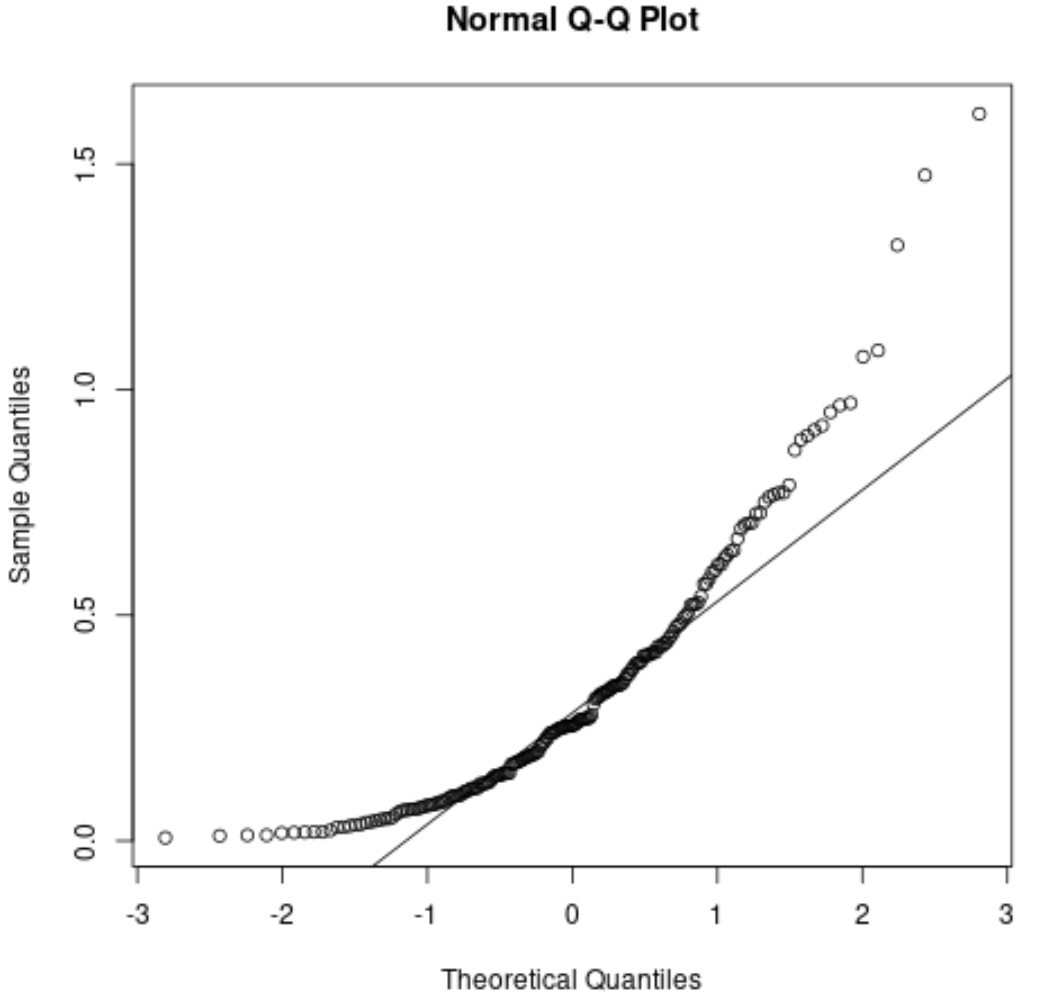
हम देखते हैं कि बिंदु विकर्ण रेखा से काफी विचलन करते हैं। यह स्पष्ट रूप से इंगित करता है कि डेटासेट सामान्य रूप से वितरित नहीं है।
यह समझ में आना चाहिए कि हमने निर्दिष्ट किया है कि डेटा को एक घातांकीय वितरण का पालन करना चाहिए।
QQ प्लॉट और हिस्टोग्राम
यह ध्यान दिया जाना चाहिए कि QQ प्लॉट यह जांचने का एक तरीका है कि डेटा सेट सामान्य वितरण का पालन करता है या नहीं।
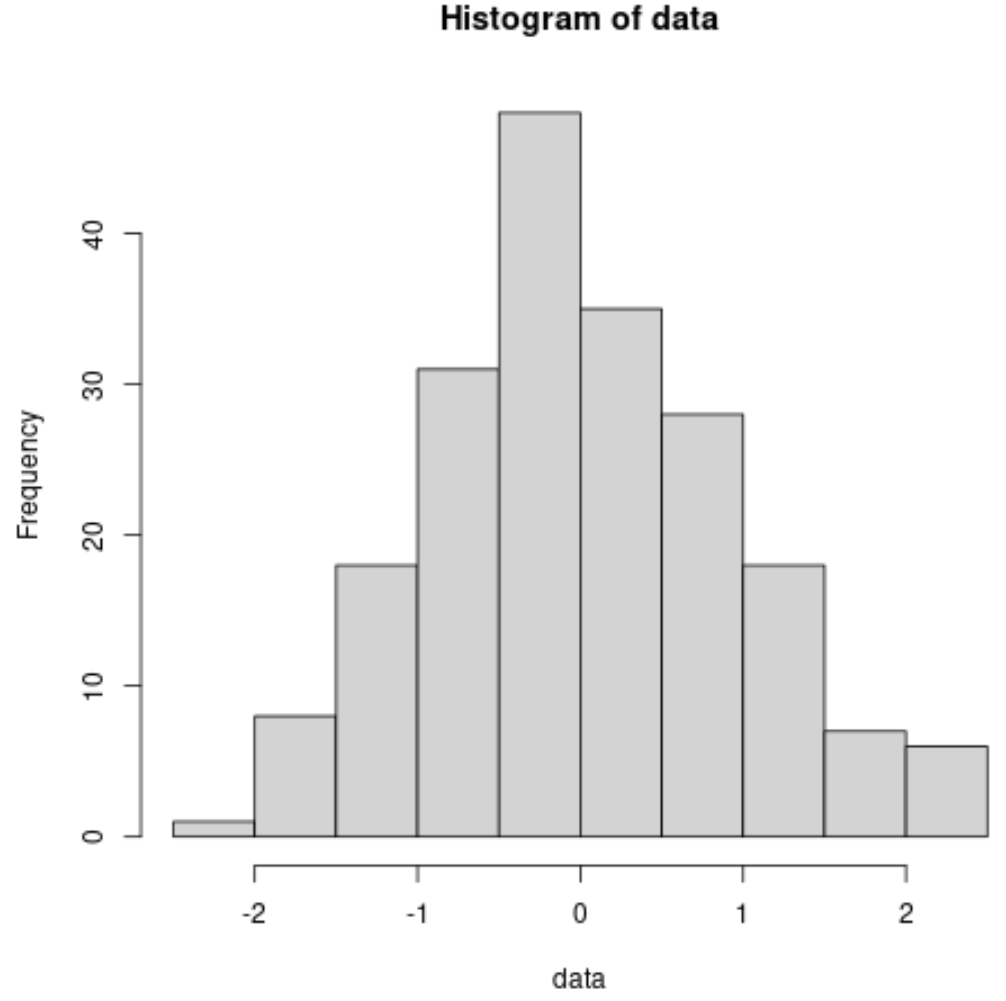
सामान्यता को दृष्टिगत रूप से जांचने का दूसरा तरीका डेटा सेट का हिस्टोग्राम बनाना है। यदि डेटा हिस्टोग्राम में लगभग एक घंटी वक्र आकार का अनुसरण करता है, तो हम मान सकते हैं कि डेटा सेट सामान्य रूप से वितरित है।
उदाहरण के लिए, यहां बताया गया है कि पहले सामान्य रूप से वितरित डेटा सेट के लिए हिस्टोग्राम कैसे बनाया जाए:
#make this example reproducible set. seeds (1) #create some fake data that follows a normal distribution data <- rnorm(200) #create a histogram to visualize the distribution hist(data)
और यहां डेटासेट के लिए एक हिस्टोग्राम बनाने का तरीका बताया गया है जो एक घातीय पूर्व वितरण का अनुसरण करता है:
#make this example reproducible set. seeds (1) #create some fake data that follows an exponential distribution data <- rexp(200, rate=3) #create a histogram to visualize the distribution hist(data)
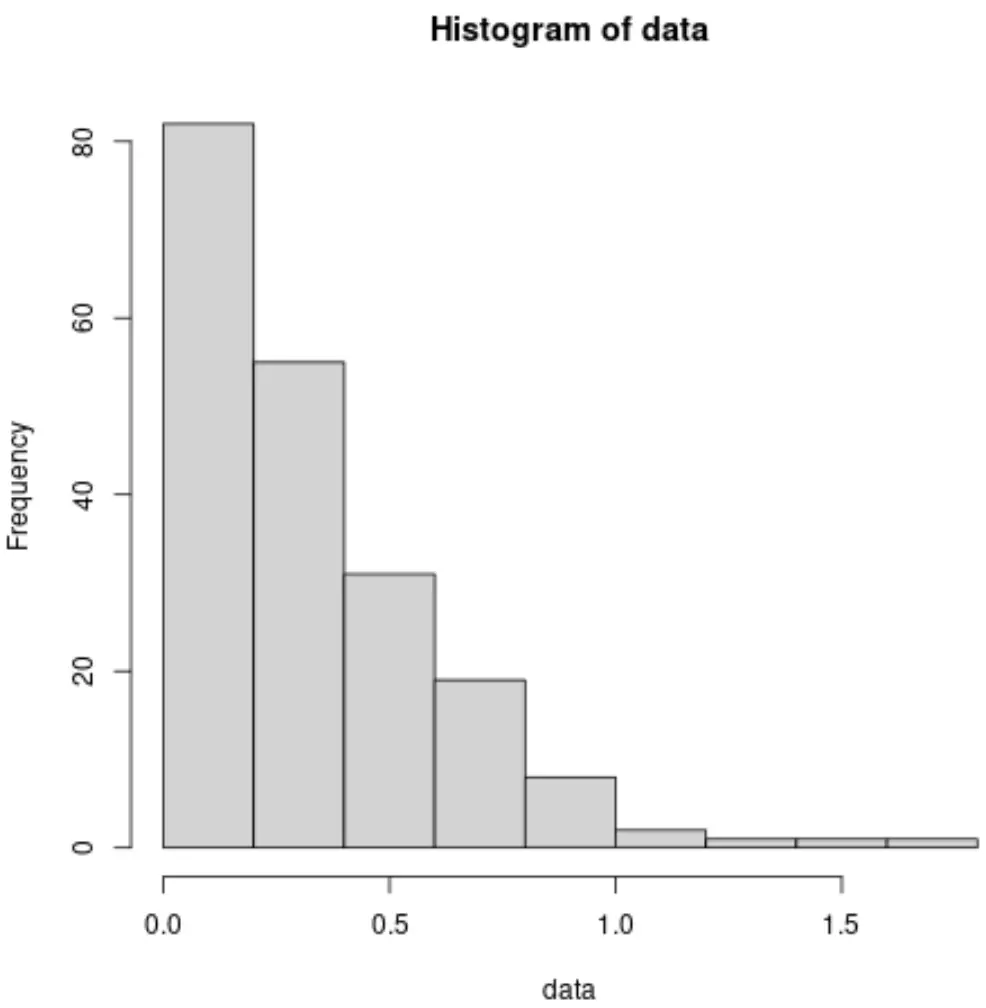
हम देखते हैं कि हिस्टोग्राम बिल्कुल भी घंटी वक्र जैसा नहीं दिखता है, जो स्पष्ट रूप से इंगित करता है कि डेटा सामान्य वितरण का पालन नहीं करता है।
अतिरिक्त संसाधन
सांख्यिकी में सामान्यता की धारणा क्या है?
R में QQ प्लॉट कैसे बनाएं
एक्सेल में QQ प्लॉट कैसे बनाएं
पायथन में QQ प्लॉट कैसे बनाएं
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने