पायथन में आरओसी वक्र कैसे बनाएं (चरण दर चरण)
लॉजिस्टिक रिग्रेशन एक सांख्यिकीय पद्धति है जिसका उपयोग हम रिग्रेशन मॉडल को फिट करने के लिए करते हैं जब प्रतिक्रिया चर द्विआधारी होता है। यह मूल्यांकन करने के लिए कि लॉजिस्टिक रिग्रेशन मॉडल डेटा सेट में कितनी अच्छी तरह फिट बैठता है, हम निम्नलिखित दो मैट्रिक्स देख सकते हैं:
- संवेदनशीलता: संभावना है कि मॉडल किसी अवलोकन के लिए सकारात्मक परिणाम की भविष्यवाणी करता है जब परिणाम वास्तव में सकारात्मक होता है। इसे “सच्ची सकारात्मक दर” भी कहा जाता है।
- विशिष्टता: संभावना है कि मॉडल किसी अवलोकन के लिए नकारात्मक परिणाम की भविष्यवाणी करता है जब परिणाम वास्तव में नकारात्मक होता है। इसे “सच्ची नकारात्मक दर” भी कहा जाता है।
इन दो मापों को देखने का एक तरीका एक आरओसी वक्र बनाना है, जो “रिसीवर ऑपरेटिंग विशेषता” वक्र के लिए है। यह एक ग्राफ़ है जो लॉजिस्टिक रिग्रेशन मॉडल की संवेदनशीलता और विशिष्टता को प्रदर्शित करता है।
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि पायथन में आरओसी वक्र कैसे बनाया और व्याख्या किया जाए।
चरण 1: आवश्यक पैकेज आयात करें
सबसे पहले, हम पायथन में लॉजिस्टिक रिग्रेशन करने के लिए आवश्यक पैकेज आयात करेंगे:
import pandas as pd import numpy as np from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn import metrics import matplotlib. pyplot as plt
चरण 2: लॉजिस्टिक रिग्रेशन मॉडल को फिट करें
इसके बाद, हम एक डेटासेट आयात करेंगे और उसमें एक लॉजिस्टिक रिग्रेशन मॉडल फिट करेंगे:
#import dataset from CSV file on Github
url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv"
data = pd. read_csv (url)
#define the predictor variables and the response variable
X = data[[' student ',' balance ',' income ']]
y = data[' default ']
#split the dataset into training (70%) and testing (30%) sets
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.3,random_state=0)
#instantiate the model
log_regression = LogisticRegression()
#fit the model using the training data
log_regression. fit (X_train,y_train)
चरण 3: आरओसी वक्र बनाएं
इसके बाद, हम वास्तविक सकारात्मक दर और गलत सकारात्मक दर की गणना करेंगे और मैटप्लोटलिब डेटा विज़ुअलाइज़ेशन पैकेज का उपयोग करके एक आरओसी वक्र बनाएंगे:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr)
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. show ()
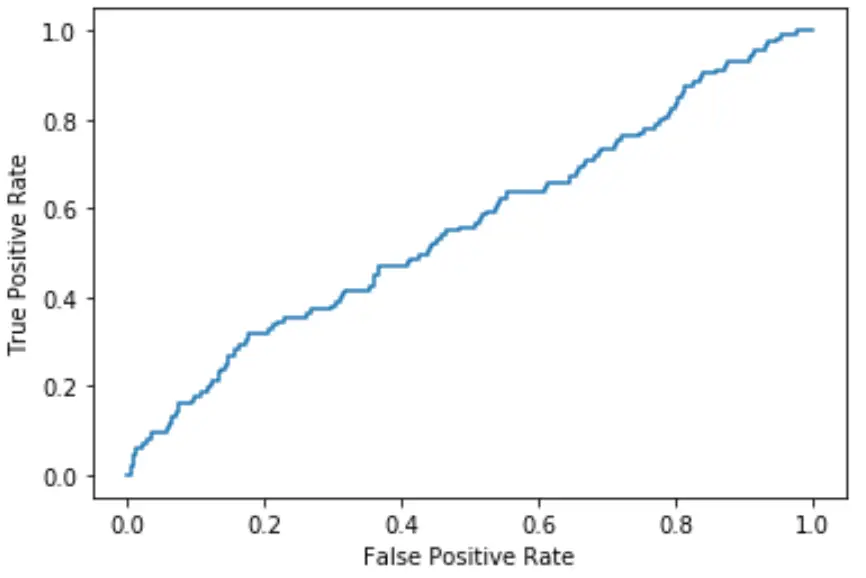
वक्र प्लॉट के ऊपरी बाएँ कोने के जितना करीब फिट होगा, मॉडल उतना ही बेहतर ढंग से डेटा को श्रेणियों में वर्गीकृत करने में सक्षम होगा।
जैसा कि हम ऊपर दिए गए ग्राफ़ से देख सकते हैं, यह लॉजिस्टिक रिग्रेशन मॉडल डेटा को श्रेणियों में क्रमबद्ध करने का बहुत खराब काम करता है।
इसे मापने के लिए, हम एयूसी – वक्र के नीचे का क्षेत्र – की गणना कर सकते हैं जो हमें बताता है कि प्लॉट का कितना हिस्सा वक्र के नीचे है।
AUC 1 के जितना करीब होगा, मॉडल उतना ही बेहतर होगा। 0.5 के बराबर एयूसी वाला मॉडल यादृच्छिक वर्गीकरण करने वाले मॉडल से बेहतर नहीं है।
चरण 4: एयूसी की गणना करें
हम मॉडल के एयूसी की गणना करने और इसे आरओसी प्लॉट के निचले दाएं कोने में प्रदर्शित करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
auc = metrics. roc_auc_score (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr,label=" AUC= "+str(auc))
plt. ylabel (' True Positive Rate ')
plt. xlabel (' False Positive Rate ')
plt. legend (loc=4)
plt. show ()
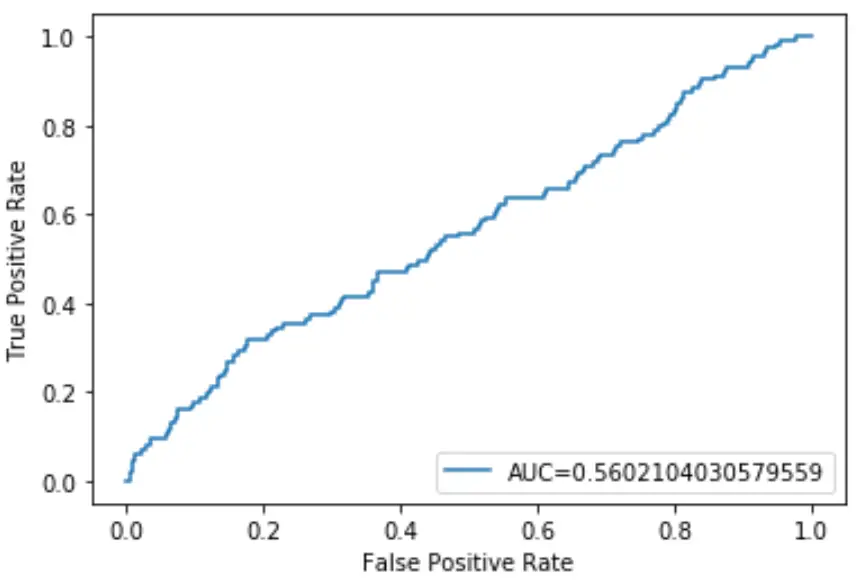
इस लॉजिस्टिक रिग्रेशन मॉडल का AUC 0.5602 निकला। चूंकि यह आंकड़ा 0.5 पर बंद है, यह पुष्टि करता है कि मॉडल डेटा को वर्गीकृत करने का खराब काम कर रहा है।
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने