आर में नेस्टेड एनोवा कैसे निष्पादित करें (चरण दर चरण)
नेस्टेड एनोवा एक प्रकार का एनोवा (“विचरण का विश्लेषण”) है जिसमें कम से कम एक कारक दूसरे कारक के भीतर निहित होता है।
उदाहरण के लिए, मान लीजिए कि एक शोधकर्ता यह जानना चाहता है कि क्या तीन अलग-अलग उर्वरक पौधों की वृद्धि के विभिन्न स्तरों का उत्पादन करते हैं।
इसका परीक्षण करने के लिए, तीन अलग-अलग तकनीशियन चार पौधों पर उर्वरक ए छिड़कते हैं, तीन अन्य तकनीशियन चार पौधों पर उर्वरक बी छिड़कते हैं, और तीन अन्य तकनीशियन चार पौधों पर उर्वरक सी छिड़कते हैं।
इस परिदृश्य में, प्रतिक्रिया चर पौधे की वृद्धि है और दो कारक तकनीशियन और उर्वरक हैं। यह पता चला है कि तकनीशियन उर्वरक में निहित है:
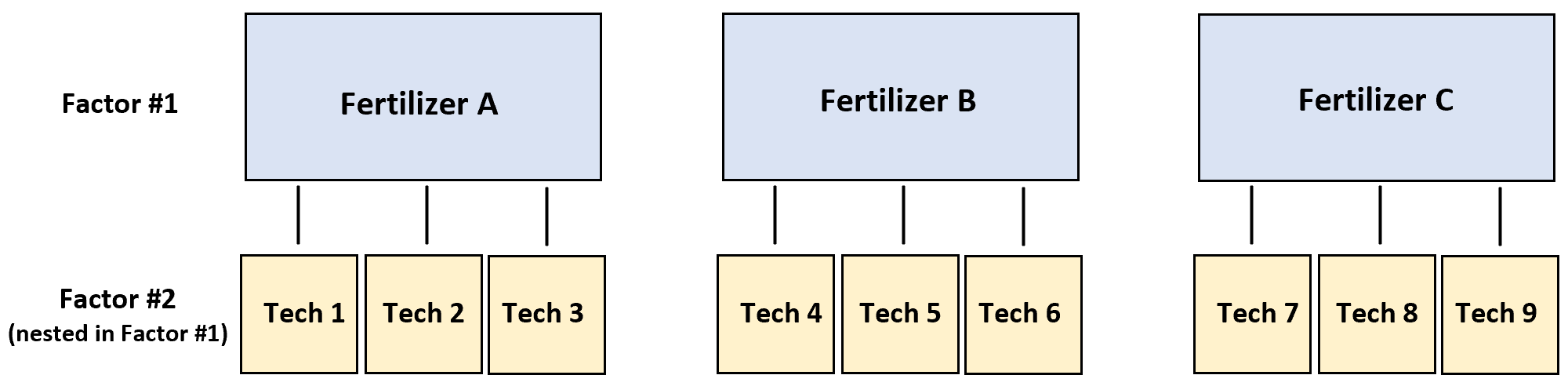
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि आर में इस नेस्टेड एनोवा को कैसे निष्पादित किया जाए।
चरण 1: डेटा बनाएं
सबसे पहले, आइए अपने डेटा को R में रखने के लिए एक डेटा फ़्रेम बनाएं:
#create data df <- data. frame (growth=c(13, 16, 16, 12, 15, 16, 19, 16, 15, 15, 12, 15, 19, 19, 20, 22, 23, 18, 16, 18, 19, 20, 21, 21, 21, 23, 24, 22, 25, 20, 20, 22, 24, 22, 25, 26), fertilizer=c(rep(c(' A ', ' B ', ' C '), each= 12 )), tech=c(rep(1:9, each= 4 ))) #view first six rows of data head(df) growth fertilizer tech 1 13 A 1 2 16 A 1 3 16 A 1 4 12 A 1 5 15 A 2 6 16 A 2
चरण 2: नेस्टेड एनोवा को समायोजित करें
हम R में नेस्टेड ANOVA को फ़िट करने के लिए निम्नलिखित सिंटैक्स का उपयोग कर सकते हैं:
एओवी(उत्तर ~ कारक ए / कारक बी)
सोना:
- प्रतिक्रिया: प्रतिक्रिया चर
- कारक ए: पहला कारक
- कारक बी: पहला कारक में निहित दूसरा कारक
निम्नलिखित कोड दिखाता है कि हमारे डेटासेट के लिए नेस्टेड एनोवा को कैसे फिट किया जाए:
#fit nested ANOVA nest <- aov(df$growth ~ df$fertilizer / factor(df$tech)) #view summary of nested ANOVA summary(nest) Df Sum Sq Mean Sq F value Pr(>F) df$fertilizer 2 372.7 186.33 53.238 4.27e-10 *** df$fertilizer:factor(df$tech) 6 31.8 5.31 1.516 0.211 Residuals 27 94.5 3.50 --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
चरण 3: परिणाम की व्याख्या करें
हम यह निर्धारित करने के लिए पी-वैल्यू कॉलम को देख सकते हैं कि प्रत्येक कारक का पौधे की वृद्धि पर सांख्यिकीय रूप से महत्वपूर्ण प्रभाव पड़ता है या नहीं।
ऊपर दी गई तालिका से, हम देख सकते हैं कि उर्वरक का पौधों की वृद्धि पर सांख्यिकीय रूप से महत्वपूर्ण प्रभाव पड़ता है (पी-वैल्यू <0.05), लेकिन तकनीशियन नहीं करता (पी-वैल्यू = 0.211)।
यह हमें बताता है कि यदि हम पौधों की वृद्धि बढ़ाना चाहते हैं, तो हमें उर्वरक लगाने वाले व्यक्तिगत तकनीशियन के बजाय उपयोग किए जाने वाले उर्वरक पर ध्यान केंद्रित करने की आवश्यकता है।
चरण 4: परिणामों की कल्पना करें
अंत में, हम उर्वरक और तकनीशियन द्वारा पौधों की वृद्धि के वितरण की कल्पना करने के लिए बॉक्सप्लॉट का उपयोग कर सकते हैं:
#load ggplot2 data visualization package library (ggplot2) #create boxplots to visualize plant growth ggplot(df, aes (x=factor(tech), y=growth, fill=fertilizer)) + geom_boxplot()
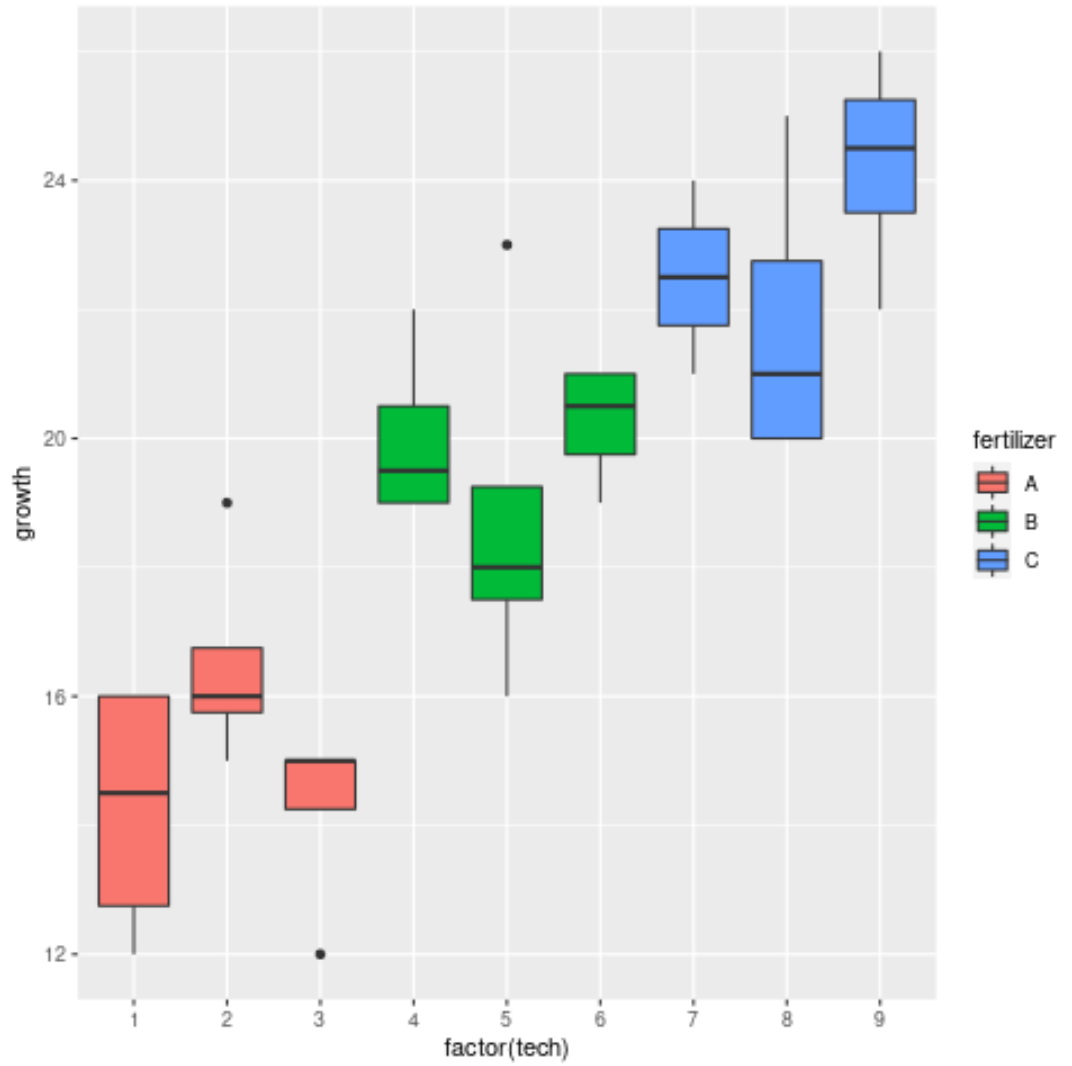
ग्राफ़ से पता चलता है कि तीन अलग-अलग उर्वरकों के बीच विकास में महत्वपूर्ण भिन्नता है, लेकिन प्रत्येक उर्वरक समूह के तकनीशियनों के बीच उतनी भिन्नता नहीं है।
ऐसा प्रतीत होता है कि यह नेस्टेड एनोवा के परिणामों से मेल खाता है और पुष्टि करता है कि उर्वरकों का पौधों की वृद्धि पर महत्वपूर्ण प्रभाव पड़ता है, लेकिन व्यक्तिगत तकनीशियन ऐसा नहीं करते हैं।
अतिरिक्त संसाधन
आर में एकतरफ़ा एनोवा कैसे निष्पादित करें
आर में दो-तरफा एनोवा कैसे निष्पादित करें
आर में एनोवा के बार-बार उपाय कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने