पर्यवेक्षित और पर्यवेक्षित शिक्षण का एक त्वरित परिचय
मशीन लर्निंग के क्षेत्र में एल्गोरिदम का एक विशाल सेट शामिल है जिसका उपयोग डेटा को समझने के लिए किया जा सकता है। इन एल्गोरिदम को निम्नलिखित दो श्रेणियों में से एक में वर्गीकृत किया जा सकता है:
1. पर्यवेक्षित शिक्षण एल्गोरिदम: एक या अधिक इनपुट के आधार पर परिणाम का अनुमान लगाने या भविष्यवाणी करने के लिए एक मॉडल बनाना शामिल है।
2. अप्रशिक्षित शिक्षण एल्गोरिदम: इसमें इनपुट से संरचना और संबंध ढूंढना शामिल है। कोई “पर्यवेक्षण” आउटपुट नहीं है.
यह ट्यूटोरियल प्रत्येक के कई उदाहरणों के साथ इन दो प्रकार के एल्गोरिदम के बीच अंतर बताता है।
पर्यवेक्षित शिक्षण एल्गोरिदम
एक पर्यवेक्षित शिक्षण एल्गोरिदम का उपयोग तब किया जा सकता है जब हमारे पास एक या अधिक व्याख्यात्मक चर ( X1, प्रतिक्रिया चर:
वाई = एफ (एक्स) + ε
जहां f व्यवस्थित जानकारी का प्रतिनिधित्व करता है जो X, Y के बारे में प्रदान करता है और जहां ε शून्य के माध्य के साथ X से स्वतंत्र एक यादृच्छिक त्रुटि शब्द है।
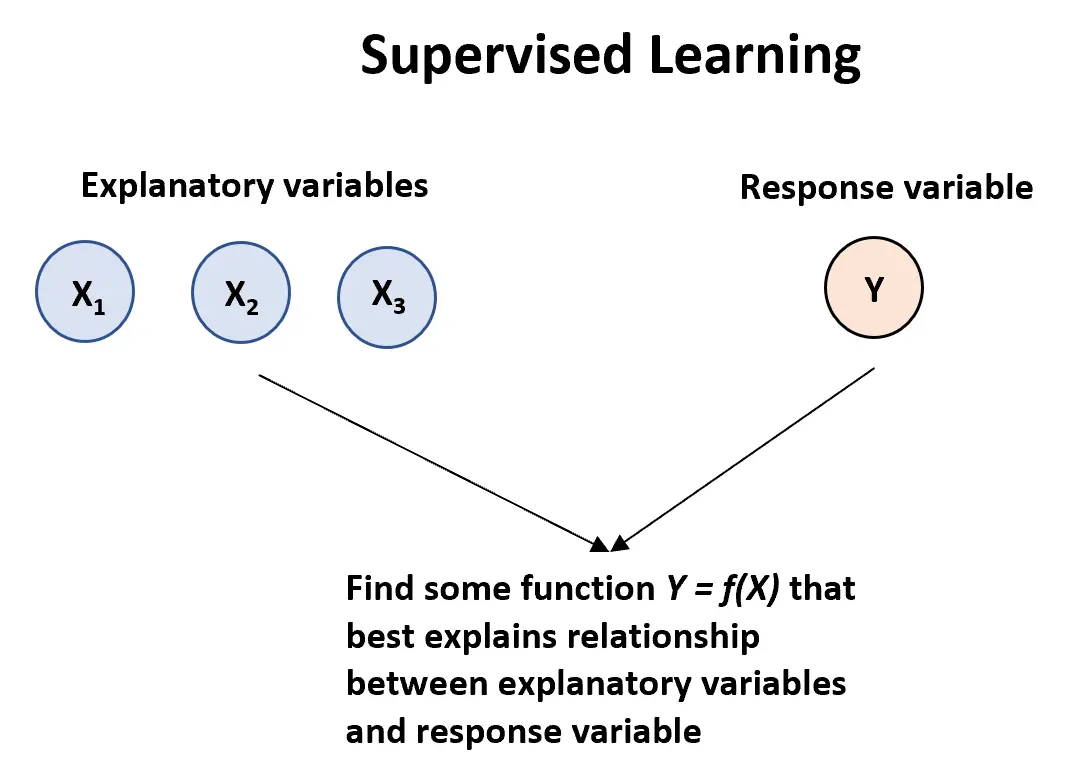
पर्यवेक्षित शिक्षण एल्गोरिदम के दो मुख्य प्रकार हैं:
1. प्रतिगमन: आउटपुट चर निरंतर है (उदाहरण के लिए वजन, ऊंचाई, समय, आदि)
2. वर्गीकरण: आउटपुट चर श्रेणीबद्ध है (जैसे पुरुष या महिला, सफलता या विफलता, सौम्य या घातक, आदि)
हम पर्यवेक्षित शिक्षण एल्गोरिदम का उपयोग क्यों करते हैं इसके दो मुख्य कारण हैं:
1. भविष्यवाणी: हम अक्सर प्रतिक्रिया चर के मूल्य की भविष्यवाणी करने के लिए व्याख्यात्मक चर के एक सेट का उपयोग करते हैं (उदाहरण के लिए, घर की कीमत की भविष्यवाणी करने के लिए वर्ग फुटेज और शयनकक्षों की संख्या का उपयोग करना)।
2. अनुमान: हमें यह समझने में रुचि हो सकती है कि जब व्याख्यात्मक चर का मूल्य बदलता है तो प्रतिक्रिया चर कैसे प्रभावित होता है (उदाहरण के लिए, जब कमरों की संख्या एक बढ़ जाती है, तो औसतन अचल संपत्ति की कीमत कितनी बढ़ जाती है?)
इस पर निर्भर करते हुए कि हमारा लक्ष्य अनुमान है या भविष्यवाणी (या दोनों का मिश्रण), हम फ़ंक्शन f का अनुमान लगाने के लिए विभिन्न तरीकों का उपयोग कर सकते हैं। उदाहरण के लिए, रैखिक मॉडल आसान व्याख्या प्रदान करते हैं, लेकिन व्याख्या करने में कठिनाई वाले गैर-रेखीय मॉडल अधिक सटीक भविष्यवाणियां प्रदान कर सकते हैं।
यहां सबसे अधिक उपयोग किए जाने वाले पर्यवेक्षित शिक्षण एल्गोरिदम की सूची दी गई है:
- रेखीय प्रतिगमन
- संभार तन्त्र परावर्तन
- रैखिक विभेदक विश्लेषण
- द्विघात विभेदक विश्लेषण
- निर्णय के पेड़
- नादान बेयस
- समर्थन वेक्टर मशीन
- तंत्रिका – तंत्र
अप्रशिक्षित शिक्षण एल्गोरिदम
जब हमारे पास वेरिएबल्स ( एक्स 1 , डेटा) की एक सूची होती है तो एक अनसुपरवाइज्ड लर्निंग एल्गोरिदम का उपयोग किया जा सकता है।
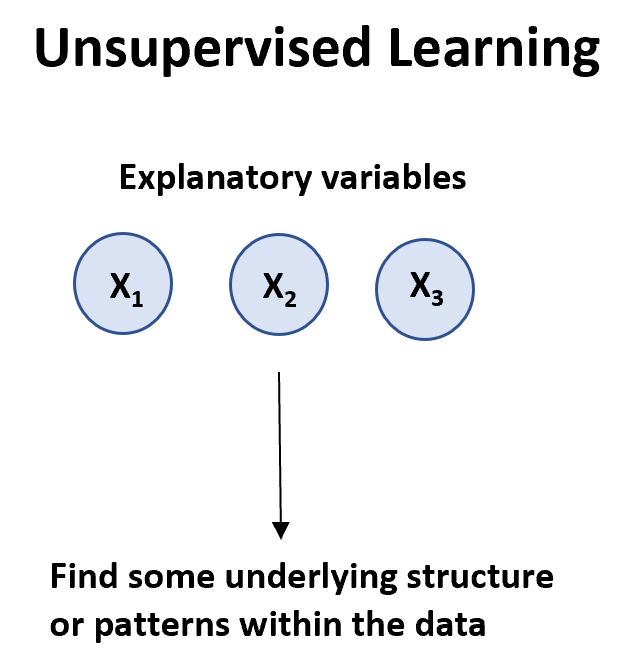
अप्रशिक्षित शिक्षण एल्गोरिदम के दो मुख्य प्रकार हैं:
1. क्लस्टरिंग: इस प्रकार के एल्गोरिदम का उपयोग करके, हम डेटा सेट में अवलोकनों के “क्लस्टर” ढूंढने का प्रयास करते हैं जो एक दूसरे के समान होते हैं। इसका उपयोग अक्सर खुदरा क्षेत्र में किया जाता है जब कोई व्यवसाय समान खरीदारी आदतों वाले ग्राहकों के समूहों की पहचान करना चाहता है ताकि वे कुछ ग्राहक समूहों को लक्षित करने के लिए विशिष्ट विपणन रणनीतियाँ बना सकें।
2. एसोसिएशन: इस प्रकार के एल्गोरिदम का उपयोग करके, हम “नियम” खोजने का प्रयास करते हैं जिनका उपयोग एसोसिएशन स्थापित करने के लिए किया जा सकता है। उदाहरण के लिए, खुदरा विक्रेता एक एसोसिएशन एल्गोरिदम विकसित कर सकते हैं जो इंगित करता है कि “यदि कोई ग्राहक उत्पाद एक्स खरीदता है, तो वे उत्पाद वाई भी खरीद सकते हैं।”
यहां सबसे अधिक उपयोग किए जाने वाले अनपर्यवेक्षित शिक्षण एल्गोरिदम की सूची दी गई है:
- प्रमुख कंपोनेंट विश्लेषण
- K- का अर्थ है क्लस्टरिंग
- के-मेडोइड्स का समूहन
- श्रेणीबद्ध वर्गीकरण
- एक प्राथमिक एल्गोरिथ्म
सारांश: पर्यवेक्षित या पर्यवेक्षित शिक्षण
निम्नलिखित तालिका पर्यवेक्षित और अनुपयोगी शिक्षण एल्गोरिदम के बीच अंतर को सारांशित करती है:
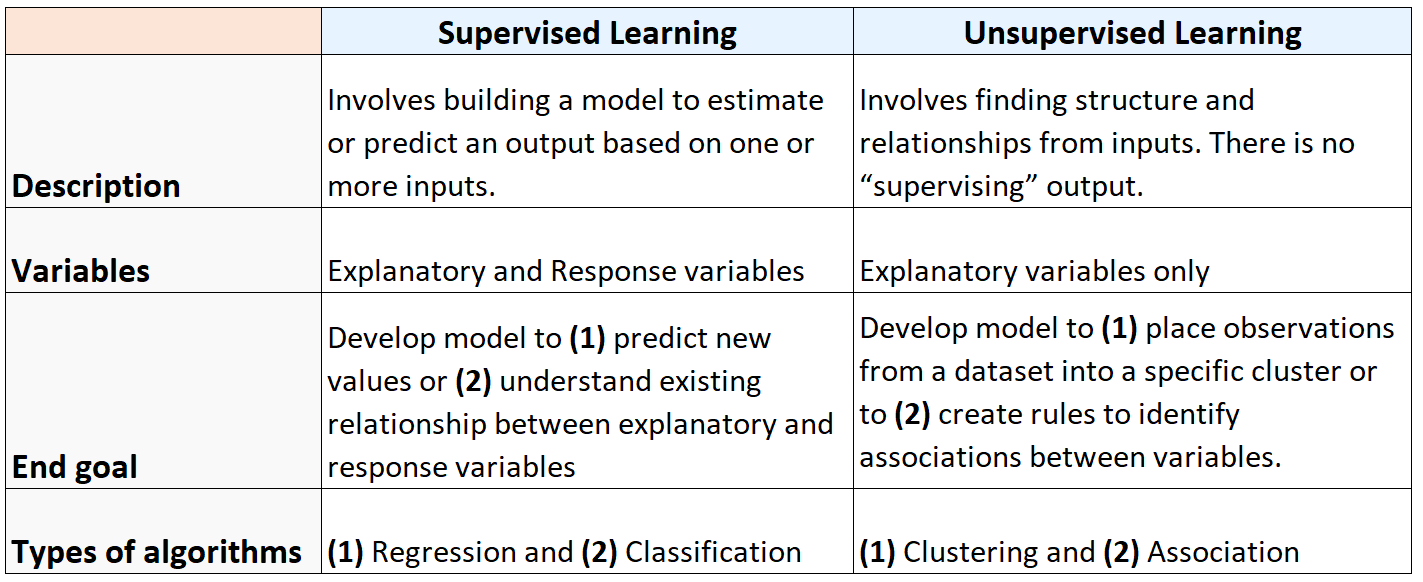
और निम्नलिखित चित्र मशीन लर्निंग एल्गोरिदम के प्रकारों का सारांश प्रस्तुत करता है:

लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने