पांडा: एक्सेल फ़ाइल पढ़ते समय पंक्तियों को कैसे छोड़ें
किसी Excel फ़ाइल को पांडा डेटाफ़्रेम में पढ़ते समय पंक्तियों को छोड़ने के लिए आप निम्नलिखित विधियों का उपयोग कर सकते हैं:
विधि 1: एक विशिष्ट पंक्ति छोड़ें
#import DataFrame and skip row in index position 2 df = pd. read_excel (' my_data.xlsx ', skiprows=[ 2 ])
विधि 2: एकाधिक विशिष्ट पंक्तियों को अनदेखा करना
#import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' my_data.xlsx ' , skiprows=[2,4 ] )
विधि 3: पहली N पंक्तियों को अनदेखा करें
#import DataFrame and skip first 2 rows df = pd. read_excel (' my_data.xlsx ', skiprows= 2 )
निम्नलिखित उदाहरण दिखाते हैं कि प्लेयर_डेटा. xlsx नामक निम्नलिखित एक्सेल फ़ाइल के साथ अभ्यास में प्रत्येक विधि का उपयोग कैसे करें:
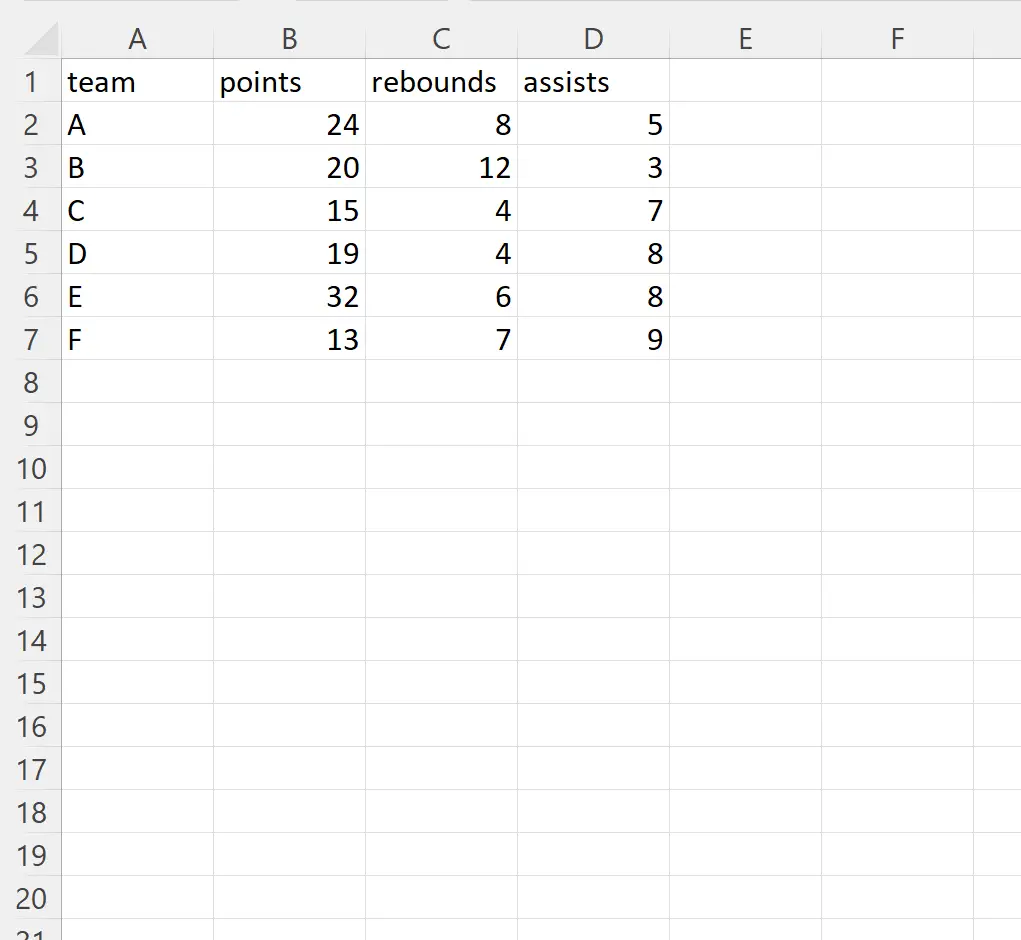
उदाहरण 1: किसी विशिष्ट पंक्ति को अनदेखा करें
हम एक्सेल फ़ाइल को आयात करने और सूचकांक स्थिति 2 पर पंक्ति को अनदेखा करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
import pandas as pd #import DataFrame and skip row in index position 2 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2 ]) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 D 19 4 8 3 E 32 6 8 4 F 13 7 9
ध्यान दें कि एक्सेल फ़ाइल को पांडा डेटाफ़्रेम में आयात करते समय इंडेक्स स्थिति 2 (टीम ‘बी’ के साथ) पर पंक्ति को अनदेखा कर दिया गया था।
नोट : एक्सेल फ़ाइल की पहली पंक्ति को पंक्ति 0 माना जाता है।
उदाहरण 2: अनेक विशिष्ट पंक्तियों को अनदेखा करना
हम एक्सेल फ़ाइल को आयात करने और सूचकांक स्थिति 2 और 4 में पंक्तियों को अनदेखा करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
import pandas as pd #import DataFrame and skip rows in index positions 2 and 4 df = pd. read_excel (' player_data.xlsx ', skiprows=[ 2,4 ] ) #view DataFrame print (df) team points rebound assists 0 to 24 8 5 1 C 15 4 7 2 E 32 6 8 3 F 13 7 9
ध्यान दें कि एक्सेल फ़ाइल को पांडा डेटाफ़्रेम में आयात करते समय इंडेक्स स्थिति 2 और 4 (टीम “बी” और “डी” के साथ) की पंक्तियों को अनदेखा कर दिया गया था।
उदाहरण 3: पहली N पंक्तियों को अनदेखा करें
हम एक्सेल फ़ाइल को आयात करने और पहली दो पंक्तियों को अनदेखा करने के लिए निम्नलिखित कोड का उपयोग कर सकते हैं:
import pandas as pd #import DataFrame and skip first 2 rows df = pd. read_excel (' player_data.xlsx ', skiprows= 2 ) #view DataFrame print (df) B 20 12 3 0 C 15 4 7 1 D 19 4 8 2 E 32 6 8 3 F 13 7 9
ध्यान दें कि एक्सेल फ़ाइल की पहली दो पंक्तियाँ छोड़ दी गई हैं और अगली उपलब्ध पंक्ति (टीम “बी” के साथ) डेटाफ़्रेम की हेडर पंक्ति बन गई है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पायथन में अन्य सामान्य कार्य कैसे करें:
पंडों के साथ एक्सेल फ़ाइलें कैसे पढ़ें
पांडा डेटाफ़्रेम को एक्सेल में कैसे निर्यात करें
NumPy सरणी को CSV फ़ाइल में कैसे निर्यात करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने