पांडा में कॉलम मानों के वितरण को कैसे प्लॉट करें
आप पांडा डेटाफ़्रेम में कॉलम मानों के वितरण को प्लॉट करने के लिए निम्नलिखित विधियों का उपयोग कर सकते हैं:
विधि 1: मानों के वितरण को एक कॉलम में प्लॉट करें
df[' my_column ']. plot (kind=' kde ')
विधि 2: एक कॉलम में मानों के वितरण को दूसरे कॉलम द्वारा समूहीकृत करके प्लॉट करें
df. groupby (' group_column ')[' values_column ']. plot (kind=' kde ')
निम्नलिखित उदाहरण दिखाते हैं कि निम्नलिखित पांडा डेटाफ़्रेम के साथ व्यवहार में प्रत्येक विधि का उपयोग कैसे करें:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'A', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B', 'B'], ' points ': [3, 3, 4, 5, 4, 7, 7, 7, 10, 11, 8, 7, 8, 9, 12, 12, 12, 14, 15, 17]}) #view DataFrame print (df) team points 0 to 3 1 to 3 2 to 4 3 to 5 4 to 4 5 TO 7 6 to 7 7 to 7 8 to 10 9 to 11 10 B 8 11 B 7 12 B 8 13 B 9 14 B 12 15 B 12 16 B 12 17 B 14 18 B 15 19 B 17
उदाहरण 1: एक कॉलम में मानों के वितरण को प्लॉट करें
निम्नलिखित कोड दिखाता है कि अंक कॉलम में मूल्यों के वितरण को कैसे प्लॉट किया जाए:
#plot distribution of values in points column df[' points ']. plot (kind=' kde ')
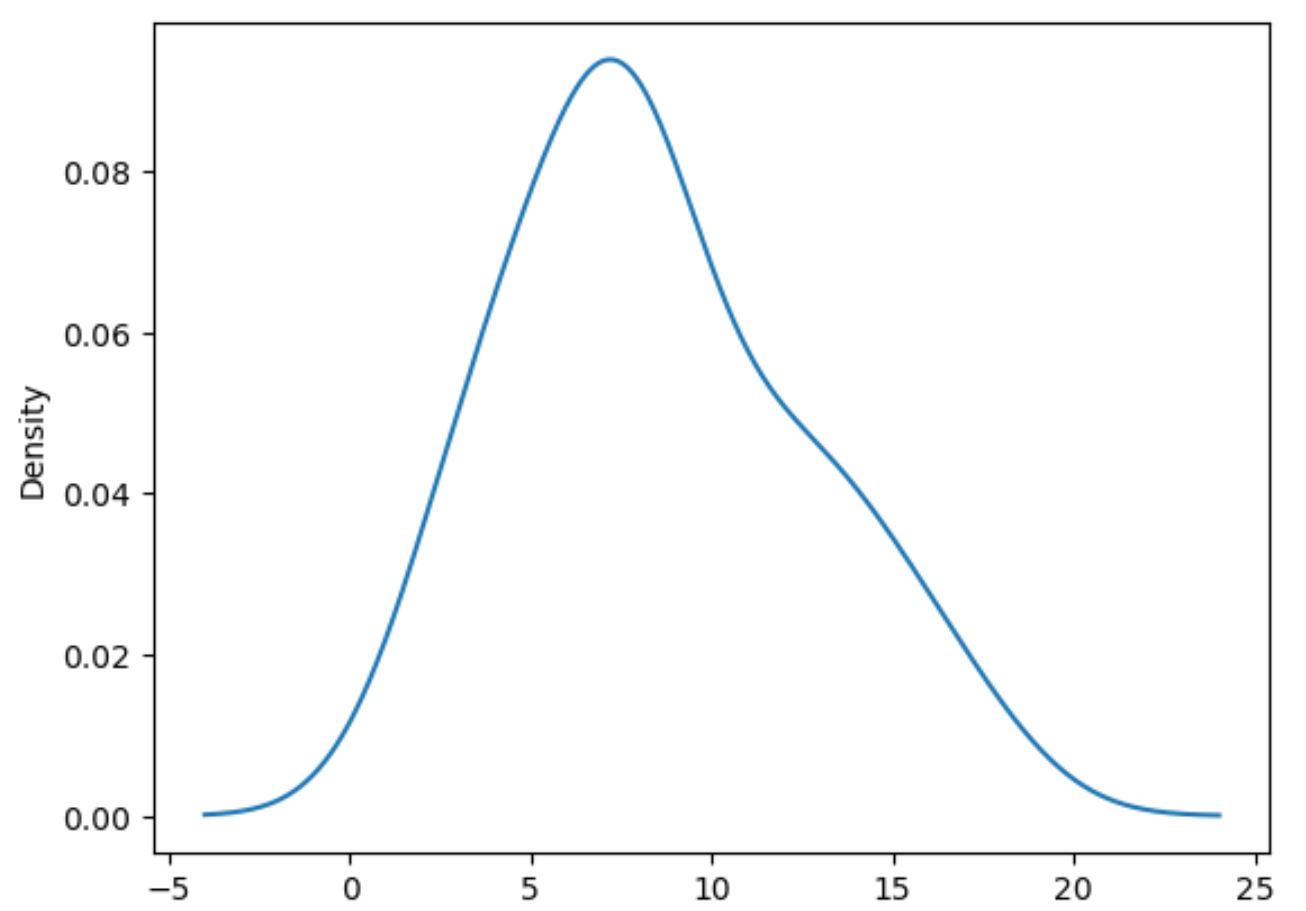
ध्यान दें कि type=’kde’ पांडा को कर्नेल घनत्व अनुमान का उपयोग करने के लिए कहता है, जो एक सहज वक्र उत्पन्न करता है जो एक चर के मूल्यों के वितरण को सारांशित करता है।
यदि आप इसके बजाय एक हिस्टोग्राम बनाना चाहते हैं, तो आप type=’hist’ को निम्नानुसार निर्दिष्ट कर सकते हैं:
#plot distribution of values in points column using histogram df[' points ']. plot (kind=' hist ', edgecolor=' black ')
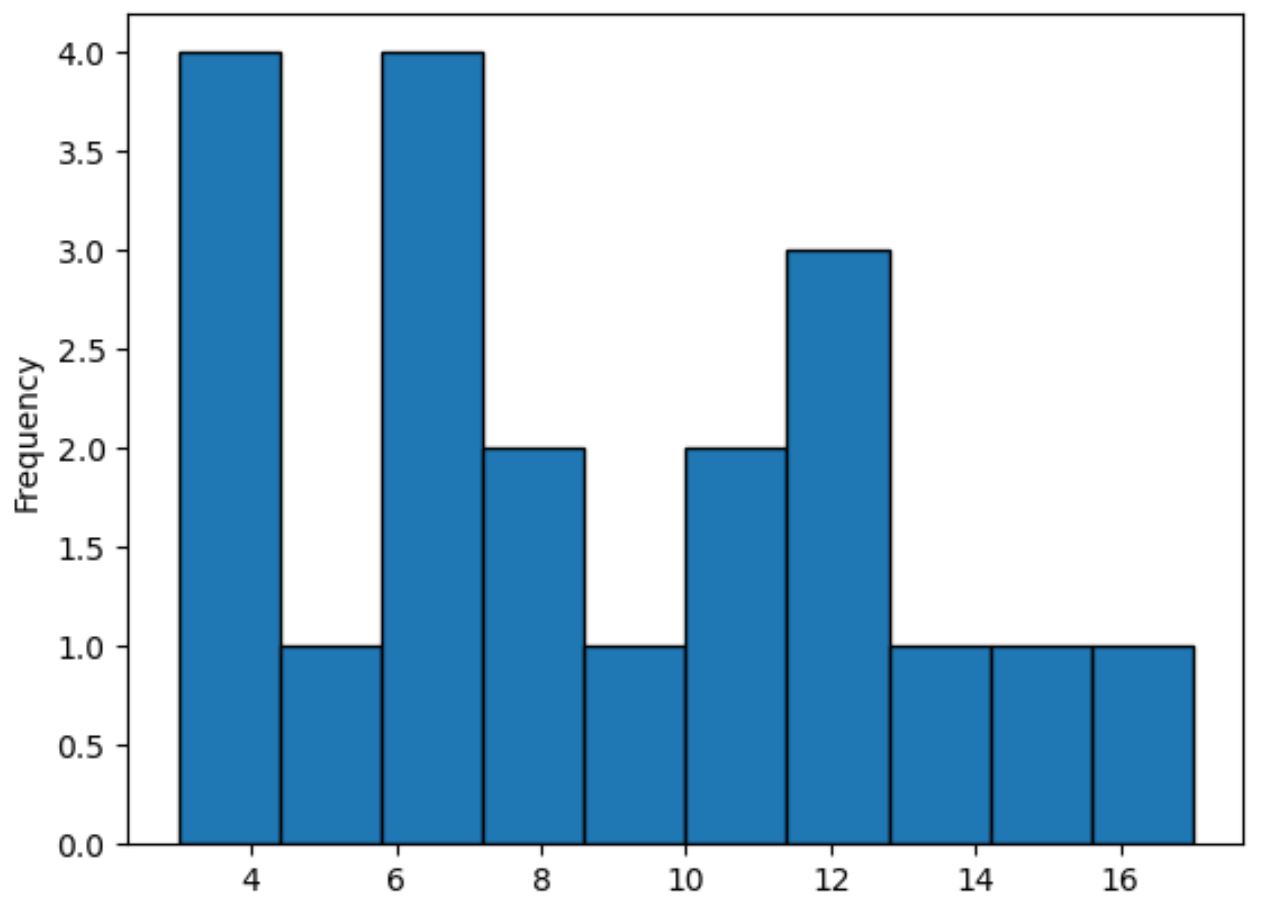
यह विधि बिंदुओं के कॉलम में मानों की आवृत्तियों को दर्शाने के लिए बार का उपयोग करती है, एक चिकनी रेखा के विपरीत जो वितरण के आकार को सारांशित करती है।
उदाहरण 2: एक कॉलम में मानों के वितरण को दूसरे कॉलम द्वारा समूहीकृत करके प्लॉट करें
निम्नलिखित कोड दिखाता है कि टीम कॉलम द्वारा समूहीकृत, अंक कॉलम में मूल्यों के वितरण को कैसे प्लॉट किया जाए:
import matplotlib.pyplot as plt #plot distribution of points by team df. groupby (' team ')[' points ']. plot (kind=' kde ') #add legend plt. legend ([' A ',' B '], title=' Team ') #add x-axis label plt. xlabel (' Points ')
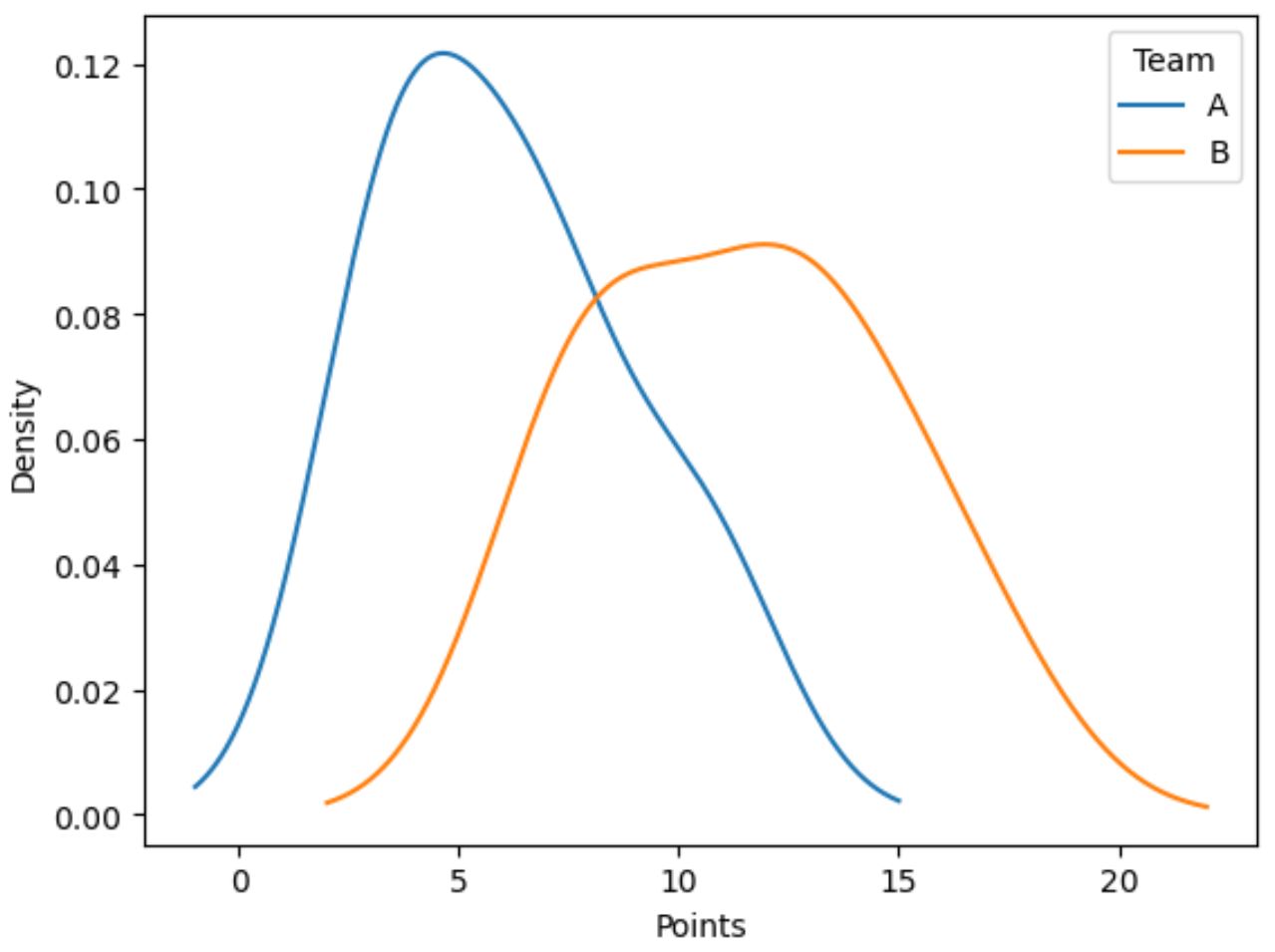
नीली रेखा टीम ए के खिलाड़ियों के अंक वितरण को दर्शाती है जबकि नारंगी रेखा टीम बी के खिलाड़ियों के अंक वितरण को दर्शाती है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि पांडा में अन्य सामान्य कार्य कैसे करें:
पांडा में प्लॉट में शीर्षक कैसे जोड़ें
पांडा प्लॉट के आकृति आकार को कैसे समायोजित करें
सबप्लॉट्स में एकाधिक पांडा डेटाफ़्रेम कैसे प्लॉट करें
पांडा में प्लॉट लेजेंड्स कैसे बनाएं और कस्टमाइज़ करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने