पायथन में वन-हॉट एन्कोडिंग कैसे करें
वन-हॉट एन्कोडिंग का उपयोग श्रेणीबद्ध चर को एक प्रारूप में परिवर्तित करने के लिए किया जाता है जिसे मशीन लर्निंग एल्गोरिदम द्वारा आसानी से उपयोग किया जा सकता है।
वन-हॉट कोडिंग का मूल विचार नए वेरिएबल्स बनाना है जो मूल श्रेणीबद्ध मूल्यों का प्रतिनिधित्व करने के लिए 0 और 1 मान लेते हैं।
उदाहरण के लिए, निम्नलिखित छवि दिखाती है कि हम टीम नामों वाले एक श्रेणीबद्ध चर को केवल 0 और 1 मान वाले नए चर में परिवर्तित करने के लिए एक-हॉट एनकोड कैसे करेंगे:
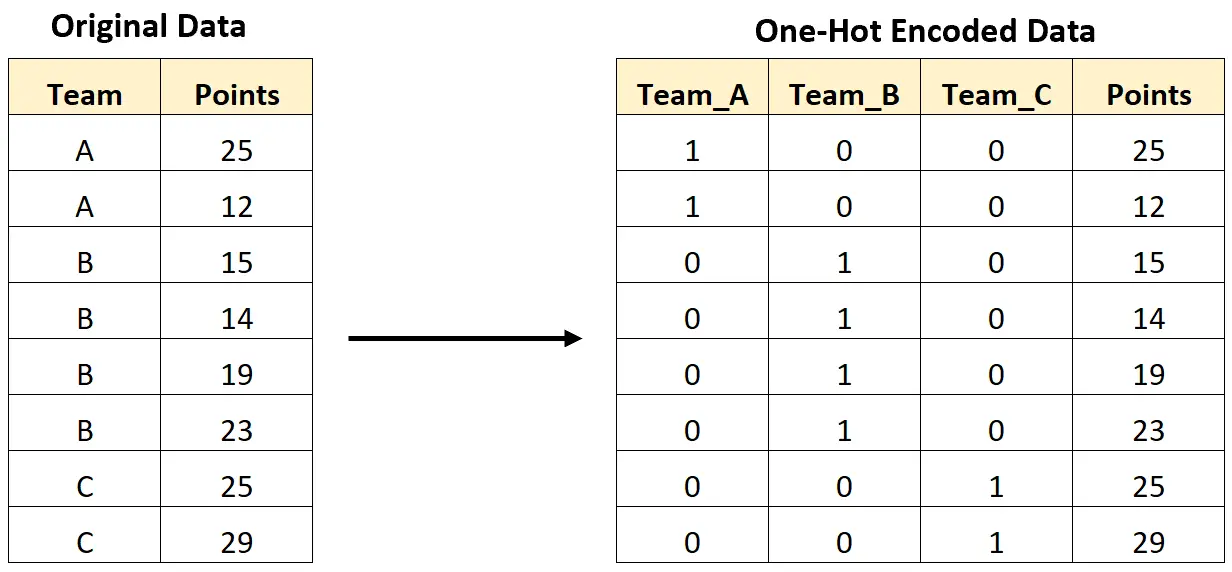
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि पायथन में इस सटीक डेटासेट के लिए एक-हॉट एन्कोडिंग कैसे करें।
चरण 1: डेटा बनाएं
सबसे पहले, आइए निम्नलिखित पांडा डेटाफ़्रेम बनाएं:
import pandas as pd #createDataFrame df = pd. DataFrame ({' team ': ['A', 'A', 'B', 'B', 'B', 'B', 'C', 'C'], ' points ': [25, 12, 15, 14, 19, 23, 25, 29]}) #view DataFrame print (df) team points 0 to 25 1 to 12 2 B 15 3 B 14 4 B 19 5 B 23 6 C 25 7 C 29
चरण 2: वन-हॉट एन्कोडिंग करें
इसके बाद, आइए स्केलेर लाइब्रेरी से OneHotEncoder() फ़ंक्शन को आयात करें और इसका उपयोग पांडा डेटाफ़्रेम में ‘टीम’ वेरिएबल पर हॉट एन्कोडिंग करने के लिए करें:
from sklearn. preprocessing import OneHotEncoder #creating instance of one-hot-encoder encoder = OneHotEncoder(handle_unknown=' ignore ') #perform one-hot encoding on 'team' column encoder_df = pd. DataFrame ( encoder.fit_transform (df[[' team ']]). toarray ()) #merge one-hot encoded columns back with original DataFrame final_df = df. join (encoder_df) #view final df print (final_df) team points 0 1 2 0 to 25 1.0 0.0 0.0 1 to 12 1.0 0.0 0.0 2 B 15 0.0 1.0 0.0 3 B 14 0.0 1.0 0.0 4 B 19 0.0 1.0 0.0 5 B 23 0.0 1.0 0.0 6 C 25 0.0 0.0 1.0 7 C 29 0.0 0.0 1.0
ध्यान दें कि डेटाफ़्रेम में तीन नए कॉलम जोड़े गए हैं क्योंकि मूल “टीम” कॉलम में तीन अद्वितीय मान थे।
नोट : आप OneHotEncoder() फ़ंक्शन के लिए संपूर्ण दस्तावेज़ यहां पा सकते हैं।
चरण 3: मूल श्रेणीगत चर हटाएँ
अंत में, हम डेटाफ़्रेम से मूल ‘टीम’ वेरिएबल को हटा सकते हैं क्योंकि अब हमें इसकी आवश्यकता नहीं है:
#drop 'team' column final_df. drop (' team ', axis= 1 , inplace= True ) #view final df print (final_df) points 0 1 2 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
संबंधित: पांडा में कॉलम कैसे हटाएं (4 तरीके)
हम अंतिम डेटाफ़्रेम के कॉलमों का नाम भी बदल सकते हैं ताकि उन्हें पढ़ना आसान हो सके:
#rename columns final_df. columns = ['points', 'teamA', 'teamB', 'teamC'] #view final df print (final_df) points teamA teamB teamC 0 25 1.0 0.0 0.0 1 12 1.0 0.0 0.0 2 15 0.0 1.0 0.0 3 14 0.0 1.0 0.0 4 19 0.0 1.0 0.0 5 23 0.0 1.0 0.0 6 25 0.0 0.0 1.0 7 29 0.0 0.0 1.0
वन-हॉट एन्कोडिंग पूरी हो गई है और अब हम इस पांडा डेटाफ़्रेम को अपनी इच्छानुसार किसी भी मशीन लर्निंग एल्गोरिदम में सम्मिलित कर सकते हैं।
अतिरिक्त संसाधन
पायथन में ट्रिम किए गए माध्य की गणना कैसे करें
पायथन में लीनियर रिग्रेशन कैसे करें
पायथन में लॉजिस्टिक रिग्रेशन कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने