पायथन में बॉक्स-कॉक्स परिवर्तन कैसे करें
बॉक्स-कॉक्स ट्रांसफ़ॉर्मेशन एक गैर-सामान्य रूप से वितरित डेटा सेट को अधिक सामान्य रूप से वितरित सेट में बदलने के लिए आमतौर पर इस्तेमाल की जाने वाली विधि है।
इस पद्धति के पीछे मूल विचार निम्न सूत्र का उपयोग करके λ के लिए एक मान ज्ञात करना है, ताकि रूपांतरित डेटा यथासंभव सामान्य वितरण के करीब हो:
- y(λ) = (y λ – 1) / λ यदि y ≠ 0
- y(λ) = लॉग(y) यदि y = 0
हम scipy.stats.boxcox() फ़ंक्शन का उपयोग करके पायथन में बॉक्स-कॉक्स परिवर्तन कर सकते हैं।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस फ़ंक्शन का उपयोग कैसे करें।
उदाहरण: पायथन में बॉक्स-कॉक्स परिवर्तन
मान लीजिए कि हम एक घातीय वितरण से 1000 मानों का एक यादृच्छिक सेट उत्पन्न करते हैं:
#load necessary packages import numpy as np from scipy. stats import boxcox import seaborn as sns #make this example reproducible n.p. random . seeds (0) #generate dataset data = np. random . exponential (size= 1000 ) #plot the distribution of data values sns. distplot (data, hist= False , kde= True )
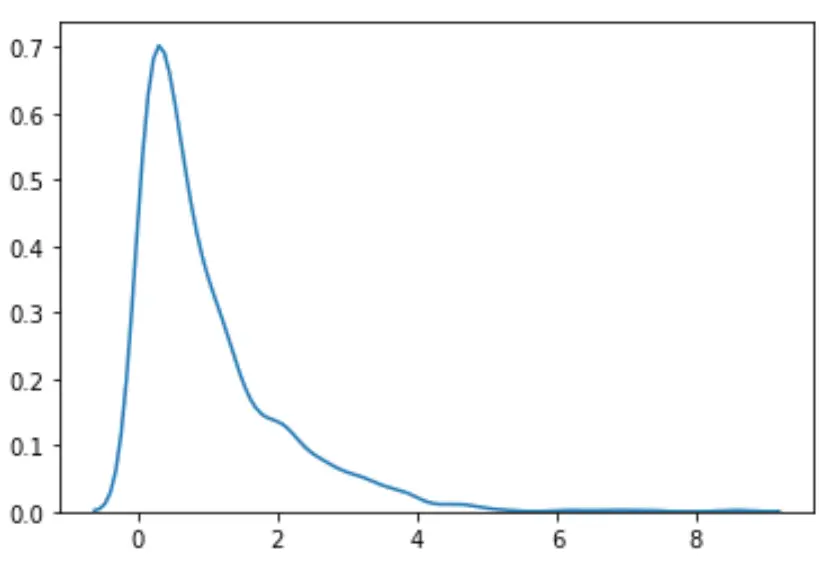
हम देख सकते हैं कि वितरण सामान्य नहीं लग रहा है।
हम लैम्ब्डा का इष्टतम मान खोजने के लिए बॉक्सकॉक्स() फ़ंक्शन का उपयोग कर सकते हैं जो अधिक सामान्य वितरण उत्पन्न करता है:
#perform Box-Cox transformation on original data transformed_data, best_lambda = boxcox(data) #plot the distribution of the transformed data values sns. distplot (transformed_data, hist= False , kde= True )
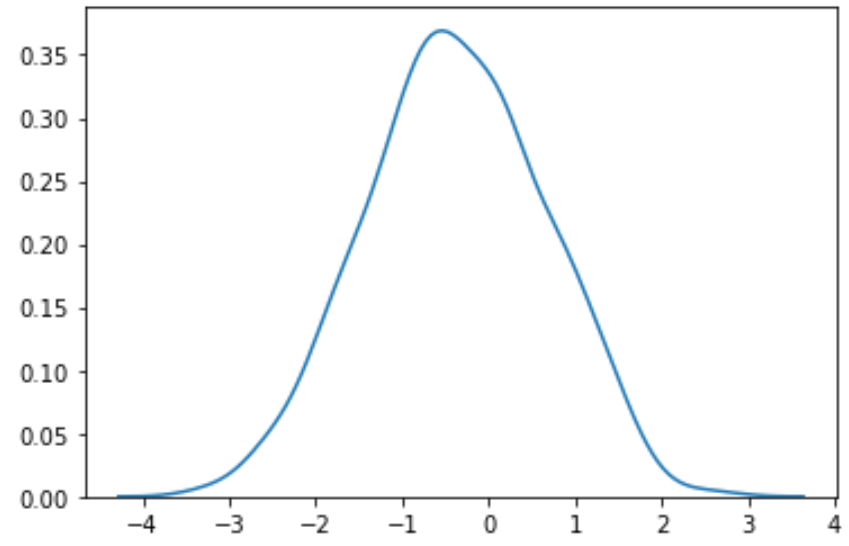
हम देख सकते हैं कि रूपांतरित डेटा कहीं अधिक सामान्य वितरण का अनुसरण करता है।
हम बॉक्स-कॉक्स परिवर्तन करने के लिए उपयोग किया जाने वाला सटीक लैम्ब्डा मान भी पा सकते हैं:
#display optimal lambda value print (best_lambda) 0.2420131978174143
इष्टतम लैम्ब्डा लगभग 0.242 पाया गया।
इस प्रकार, प्रत्येक डेटा मान को निम्नलिखित समीकरण का उपयोग करके रूपांतरित किया गया:
नया = (पुराना 0.242 – 1) / 0.242
हम मूल डेटा बनाम परिवर्तित डेटा के मूल्यों को देखकर इसकी पुष्टि कर सकते हैं:
#view first five values of original dataset data[0:5] array([0.79587451, 1.25593076, 0.92322315, 0.78720115, 0.55104849]) #view first five values of transformed dataset transformed_data[0:5] array([-0.22212062, 0.23427768, -0.07911706, -0.23247555, -0.55495228])
मूल डेटासेट में पहला मान 0.79587 था। इसलिए, हमने इस मान को बदलने के लिए निम्नलिखित सूत्र लागू किया:
नया = (.79587 0.242 – 1) / 0.242 = -0.222
हम पुष्टि कर सकते हैं कि रूपांतरित डेटासेट में पहला मान वास्तव में -0.222 है।
अतिरिक्त संसाधन
पायथन में QQ प्लॉट कैसे बनाएं और व्याख्या करें
पायथन में शापिरो-विल्क नॉर्मलिटी टेस्ट कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने