मानकीकरण या सामान्यीकरण: क्या अंतर है?
मानकीकरण और सामान्यीकरण डेटा का आकार बदलने के दो तरीके हैं।
सामान्यीकरण एक डेटा सेट को 0 के माध्य और 1 के मानक विचलन के रूप में मापता है। ऐसा करने के लिए, यह निम्नलिखित सूत्र का उपयोग करता है:
x नया = (x i – x ) / s
सोना:
- x i : डेटासेट का ith मान
- x : नमूना का मतलब है
- s : नमूने का मानक विचलन
सामान्यीकरण डेटा सेट का आकार बदल देता है ताकि प्रत्येक मान 0 और 1 के बीच हो। यह निम्न सूत्र का उपयोग करके ऐसा करता है:
x नया = (x i – x मिनट ) / (x अधिकतम – x मिनट )
सोना:
- x i : डेटासेट का ith मान
- x मिनट : डेटासेट में न्यूनतम मान
- x अधिकतम : डेटासेट में अधिकतम मान
निम्नलिखित उदाहरण दिखाते हैं कि व्यवहार में डेटा सेट को मानकीकृत और सामान्य कैसे किया जाए।
उदाहरण: डेटा का मानकीकरण कैसे करें
मान लीजिए हमारे पास निम्नलिखित डेटा सेट है:
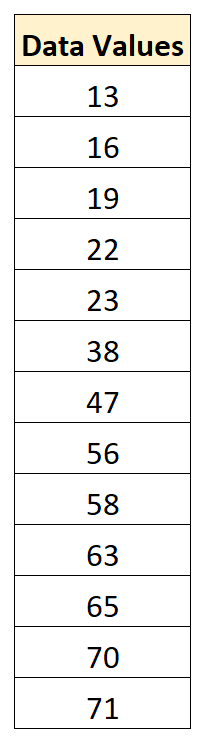
डेटासेट में औसत मान 43.15 है और मानक विचलन 22.13 है।
13 के पहले मान को सामान्य करने के लिए, हम पहले साझा किया गया फॉर्मूला लागू करेंगे:
- x नया = (x i – x ) / s = (13 – 43.15) / 22.13 = -1.36
16 के दूसरे मान को सामान्य करने के लिए, हम उसी सूत्र का उपयोग करेंगे:
- x नया = (x i – x ) / s = (16 – 43.15) / 22.13 = -1.23
19 के तीसरे मान को सामान्य करने के लिए, हम उसी सूत्र का उपयोग करेंगे:
- x नया = (x i – x ) / s = (19 – 43.15) / 22.13 = -1.09
हम मूल डेटासेट में प्रत्येक मान को मानकीकृत करने के लिए इसी सूत्र का उपयोग कर सकते हैं:
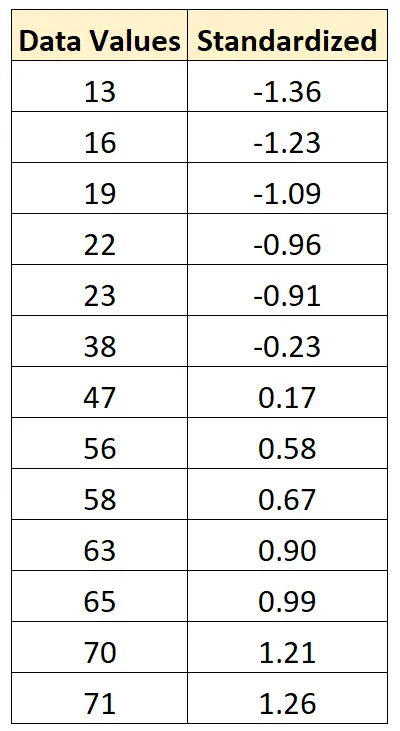
उदाहरण: डेटा को सामान्य कैसे करें
फिर, मान लीजिए कि हमारे पास निम्नलिखित डेटा सेट है:
डेटासेट में न्यूनतम मान 13 है और अधिकतम मान 71 है।
13 के पहले मान को सामान्य करने के लिए, हम पहले साझा किया गया फॉर्मूला लागू करेंगे:
- x नया = (x i – x मिनट ) / (x अधिकतम – x मिनट ) = (13 – 13) / (71 – 13) = 0
16 के दूसरे मान को सामान्य करने के लिए, हम उसी सूत्र का उपयोग करेंगे:
- x नया = (x i – x मिनट ) / (x अधिकतम – x मिनट ) = (16 – 13) / (71 – 13) = 0.0517
19 के तीसरे मान को सामान्य करने के लिए, हम उसी सूत्र का उपयोग करेंगे:
- x नया = (x i – x मिनट ) / (x अधिकतम – x मिनट ) = (19 – 13) / (71 – 13) = 0.1034
हम मूल डेटासेट में 0 और 1 के बीच प्रत्येक मान को सामान्य करने के लिए इसी सूत्र का उपयोग कर सकते हैं:
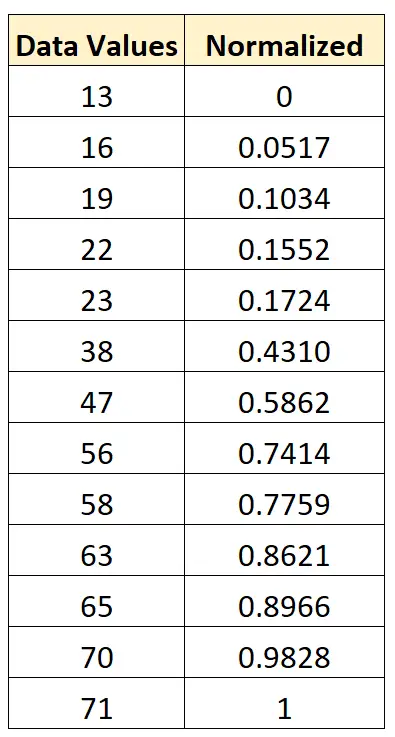
मानकीकरण या सामान्यीकरण: उनका उपयोग कब करें?
आमतौर पर, हम डेटा को सामान्यीकृत करते हैं जब हम किसी प्रकार का विश्लेषण कर रहे होते हैं जिसमें हमारे पास विभिन्न पैमानों पर मापे गए कई चर होते हैं और हम चाहते हैं कि प्रत्येक चर की सीमा समान हो।
यह एक चर को अनुचित प्रभाव डालने से रोकता है, खासकर यदि इसे विभिन्न इकाइयों में मापा जाता है (यानी यदि एक चर को इंच में और दूसरे को गज में मापा जाता है)।
दूसरी ओर, हम आम तौर पर डेटा को सामान्य करते हैं जब हम जानना चाहते हैं कि डेटा सेट में प्रत्येक मान माध्य से कितने मानक विचलन है।
उदाहरण के लिए, हमारे पास किसी विशेष स्कूल में 500 छात्रों के लिए परीक्षा अंकों की एक सूची हो सकती है और हम जानना चाहेंगे कि प्रत्येक परीक्षा स्कोर औसत स्कोर से कितने मानक विचलन है।
इस मामले में, हम इस जानकारी को जानने के लिए कच्चे डेटा को सामान्य कर सकते हैं। फिर, 1.26 का एक मानकीकृत स्कोर हमें बताएगा कि इस विशेष छात्र का परीक्षा स्कोर औसत परीक्षा स्कोर से 1.26 मानक विचलन अधिक है।
चाहे आप अपने डेटा को सामान्य या मानकीकृत करने का निर्णय लें, निम्नलिखित बातों को ध्यान में रखें:
- एक सामान्यीकृत डेटासेट का मान हमेशा 0 और 1 के बीच होगा।
- एक मानकीकृत डेटा सेट का माध्य 0 और मानक विचलन 1 होगा, लेकिन अधिकतम और न्यूनतम मूल्यों के लिए कोई विशिष्ट ऊपरी या निचली सीमा नहीं है।
आपके विशेष परिदृश्य के आधार पर, डेटा को सामान्य या मानकीकृत करना अधिक सार्थक हो सकता है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि विभिन्न सांख्यिकीय सॉफ़्टवेयर में डेटा को मानकीकृत और सामान्य कैसे किया जाए:
आर में डेटा को सामान्य कैसे करें
एक्सेल में डेटा को सामान्य कैसे करें
पायथन में डेटा को सामान्य कैसे करें
आर में डेटा का मानकीकरण कैसे करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने