एक्सेल में आरओसी कर्व कैसे बनाएं (चरण दर चरण)
लॉजिस्टिक रिग्रेशन एक सांख्यिकीय पद्धति है जिसका उपयोग हम रिग्रेशन मॉडल को फिट करने के लिए करते हैं जब प्रतिक्रिया चर द्विआधारी होता है। यह मूल्यांकन करने के लिए कि लॉजिस्टिक रिग्रेशन मॉडल डेटा सेट में कितनी अच्छी तरह फिट बैठता है, हम निम्नलिखित दो मैट्रिक्स देख सकते हैं:
- संवेदनशीलता: संभावना है कि मॉडल किसी अवलोकन के लिए सकारात्मक परिणाम की भविष्यवाणी करता है जब परिणाम वास्तव में सकारात्मक होता है। इसे “सच्ची सकारात्मक दर” भी कहा जाता है।
- विशिष्टता: संभावना है कि मॉडल किसी अवलोकन के लिए नकारात्मक परिणाम की भविष्यवाणी करता है जब परिणाम वास्तव में नकारात्मक होता है। इसे “सच्ची नकारात्मक दर” भी कहा जाता है।
इन दो मापों को देखने का एक तरीका एक आरओसी वक्र बनाना है, जो “रिसीवर ऑपरेटिंग विशेषता” वक्र के लिए है। यह एक ग्राफ़ है जो लॉजिस्टिक रिग्रेशन मॉडल की संवेदनशीलता और विशिष्टता को प्रदर्शित करता है।
निम्नलिखित चरण-दर-चरण उदाहरण दिखाता है कि एक्सेल में आरओसी वक्र कैसे बनाया और व्याख्या किया जाए।
चरण 1: डेटा दर्ज करें
आइए कुछ कच्चा डेटा दर्ज करके शुरुआत करें:
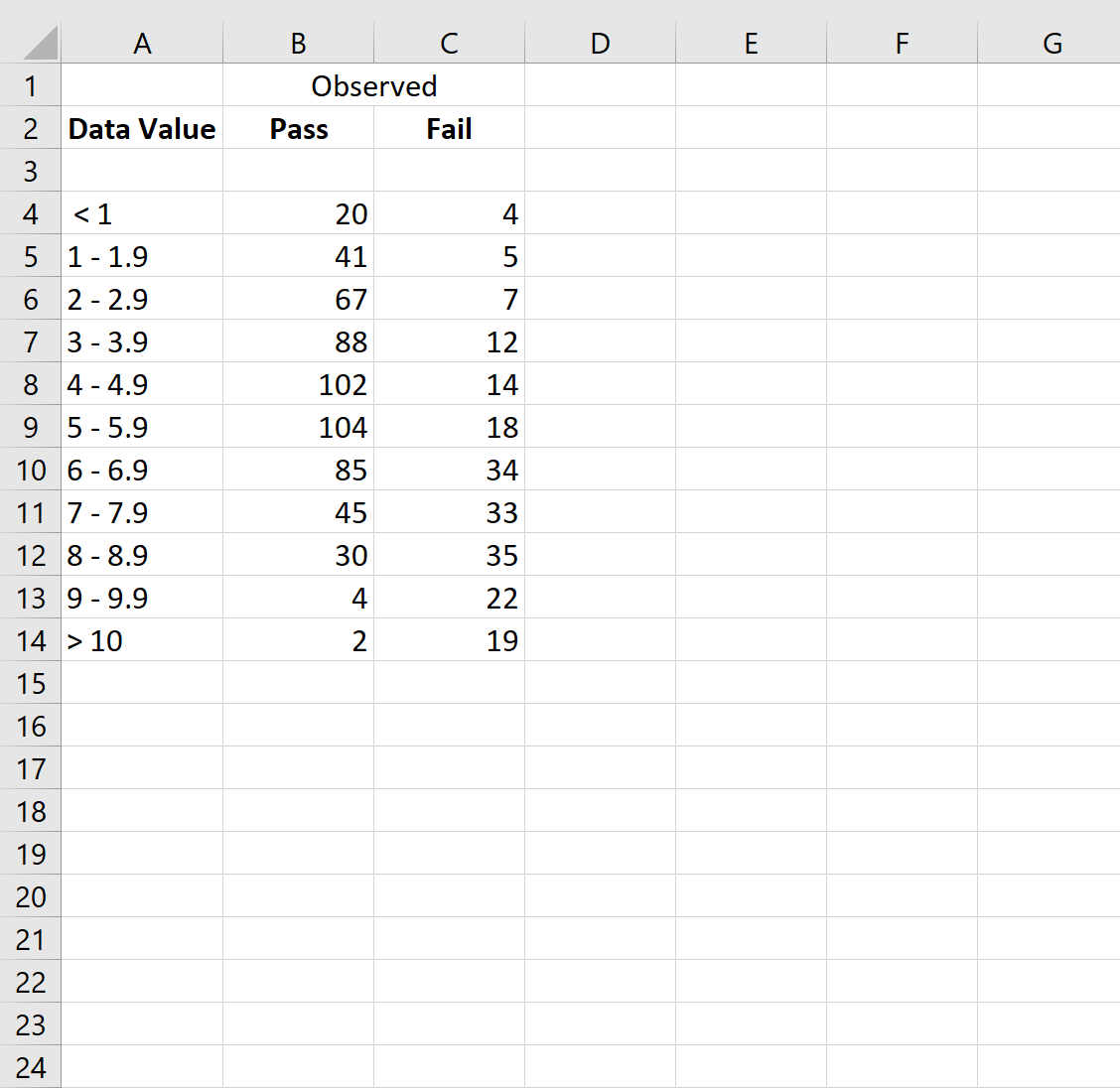
चरण 2: संचयी डेटा की गणना करें
तो आइए पास और फेल श्रेणियों के लिए संचयी मानों की गणना करने के लिए निम्नलिखित सूत्र का उपयोग करें:
- संचयी सफलता मान: =SUM($B$3:B3)
- संचयी विफलता मान: =SUM($C$3:C3)
फिर हम इन सूत्रों को कॉलम डी और कॉलम ई में प्रत्येक सेल में कॉपी और पेस्ट करेंगे:
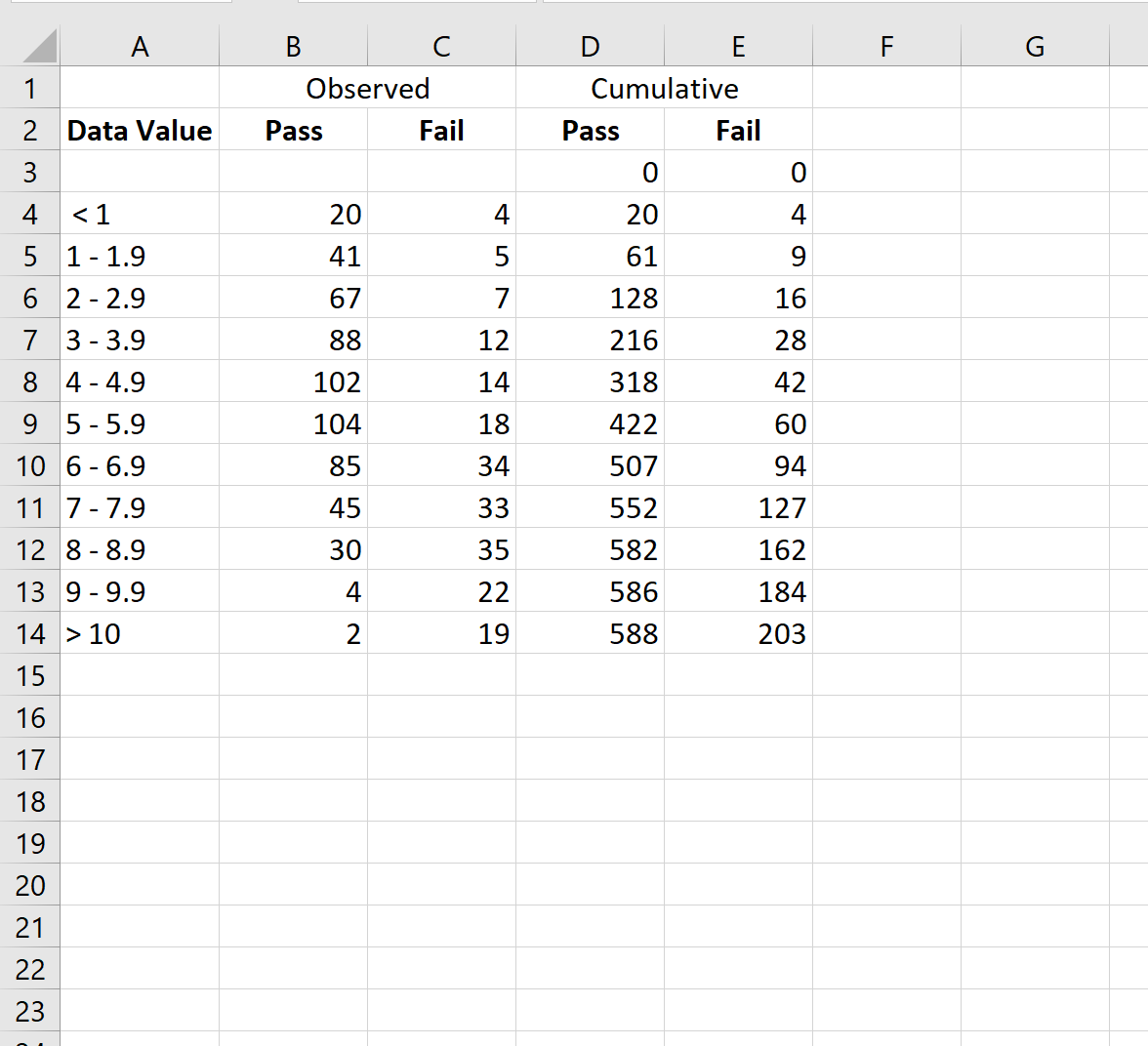
चरण 3: झूठी सकारात्मक दर और सच्ची सकारात्मक दर की गणना करें
इसके बाद, हम निम्नलिखित सूत्रों का उपयोग करके झूठी सकारात्मक दर (एफपीआर), सच्ची सकारात्मक दर (टीपीआर), और वक्र के नीचे के क्षेत्र (एयूसी) की गणना करेंगे:
- एफपीआर: =1-डी3/$डी$14
- टीपीआर: =1-ई3/$ई$14
- एएससी: =(F3-F4)*G3
फिर हम इन सूत्रों को कॉलम एफ, जी और एच में प्रत्येक सेल में कॉपी और पेस्ट करेंगे:
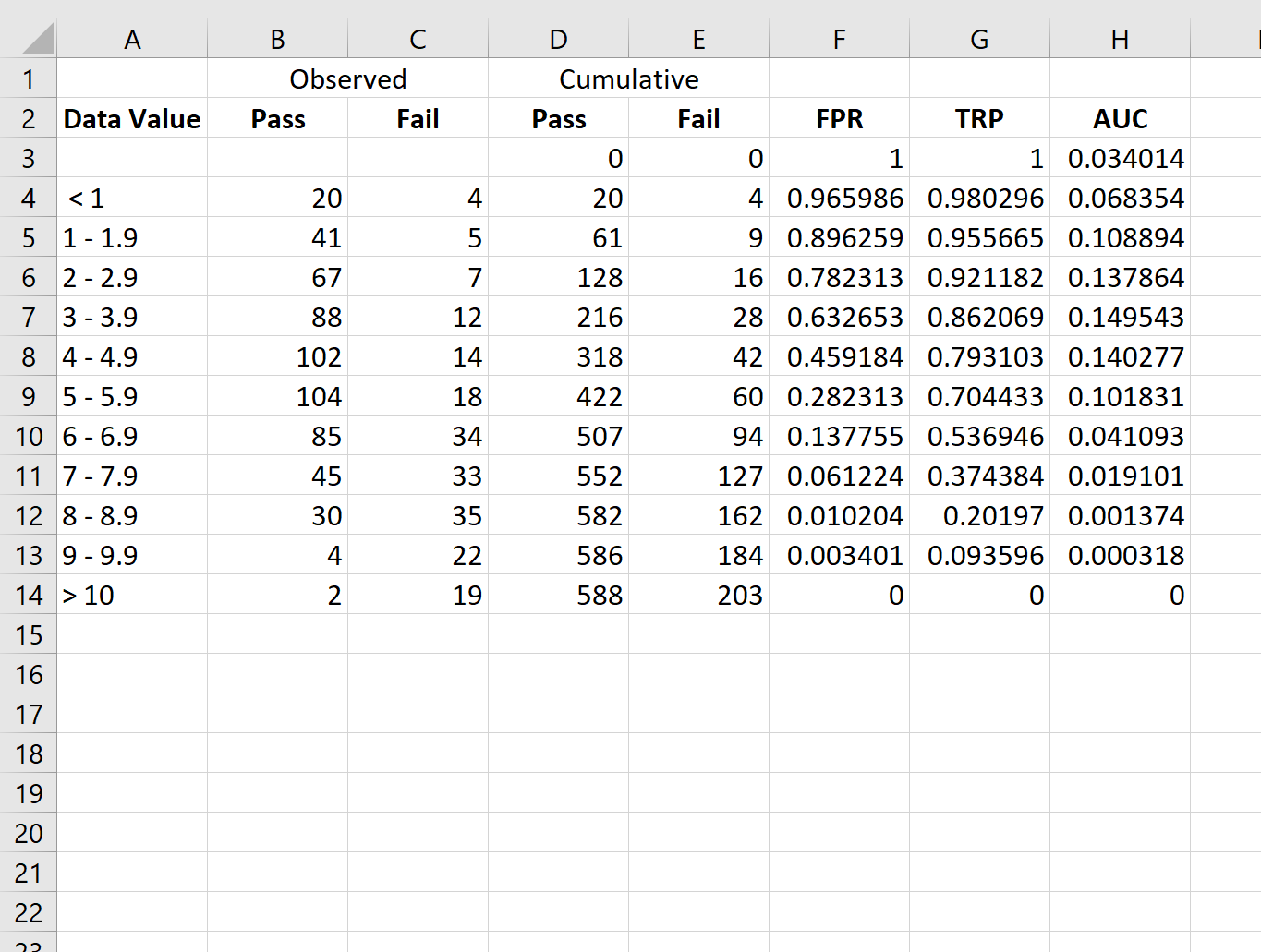
चरण 4: आरओसी वक्र बनाएं
आरओसी वक्र बनाने के लिए, हम F3:G14 श्रेणी में प्रत्येक मान को हाइलाइट करेंगे।
इसके बाद, हम शीर्ष रिबन के साथ सम्मिलित करें टैब पर क्लिक करेंगे, फिर निम्नलिखित पथ बनाने के लिए सम्मिलित स्कैटर (X, Y) पर क्लिक करेंगे:
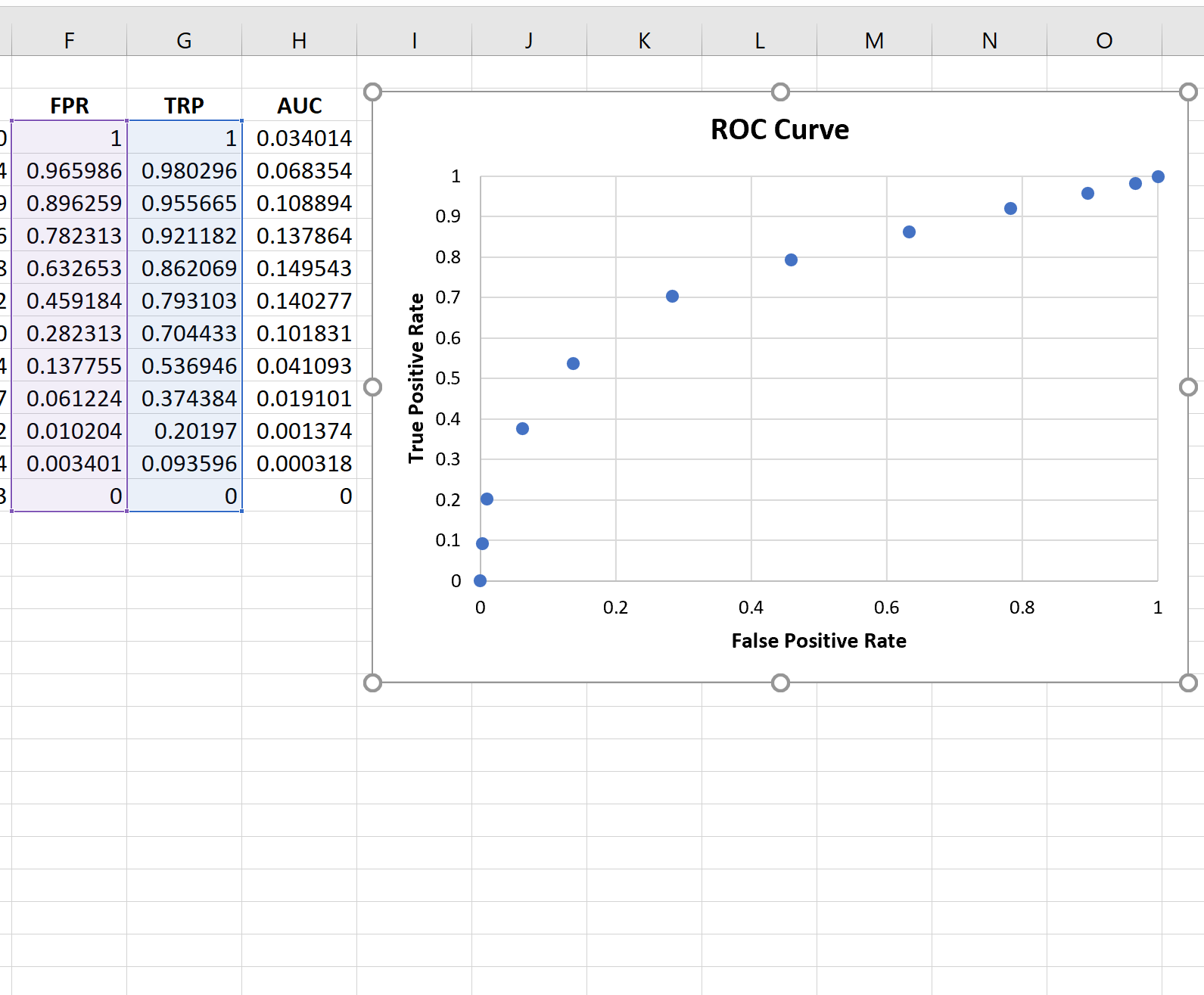
चरण 5: एयूसी की गणना करें
वक्र प्लॉट के ऊपरी बाएँ कोने के जितना करीब फिट होगा, मॉडल उतना ही बेहतर ढंग से डेटा को श्रेणियों में वर्गीकृत करने में सक्षम होगा।
जैसा कि हम ऊपर दिए गए ग्राफ़ से देख सकते हैं, यह लॉजिस्टिक रिग्रेशन मॉडल डेटा को श्रेणियों में वर्गीकृत करने का बहुत अच्छा काम करता है।
इसे मापने के लिए, हम एयूसी (वक्र के नीचे का क्षेत्र) की गणना कर सकते हैं जो हमें बताता है कि प्लॉट का कितना हिस्सा वक्र के नीचे है।
AUC 1 के जितना करीब होगा, मॉडल उतना ही बेहतर होगा। 0.5 के बराबर एयूसी वाला मॉडल यादृच्छिक वर्गीकरण करने वाले मॉडल से बेहतर नहीं है।
वक्र के AUC की गणना करने के लिए, हम कॉलम H में सभी मानों को आसानी से जोड़ सकते हैं:
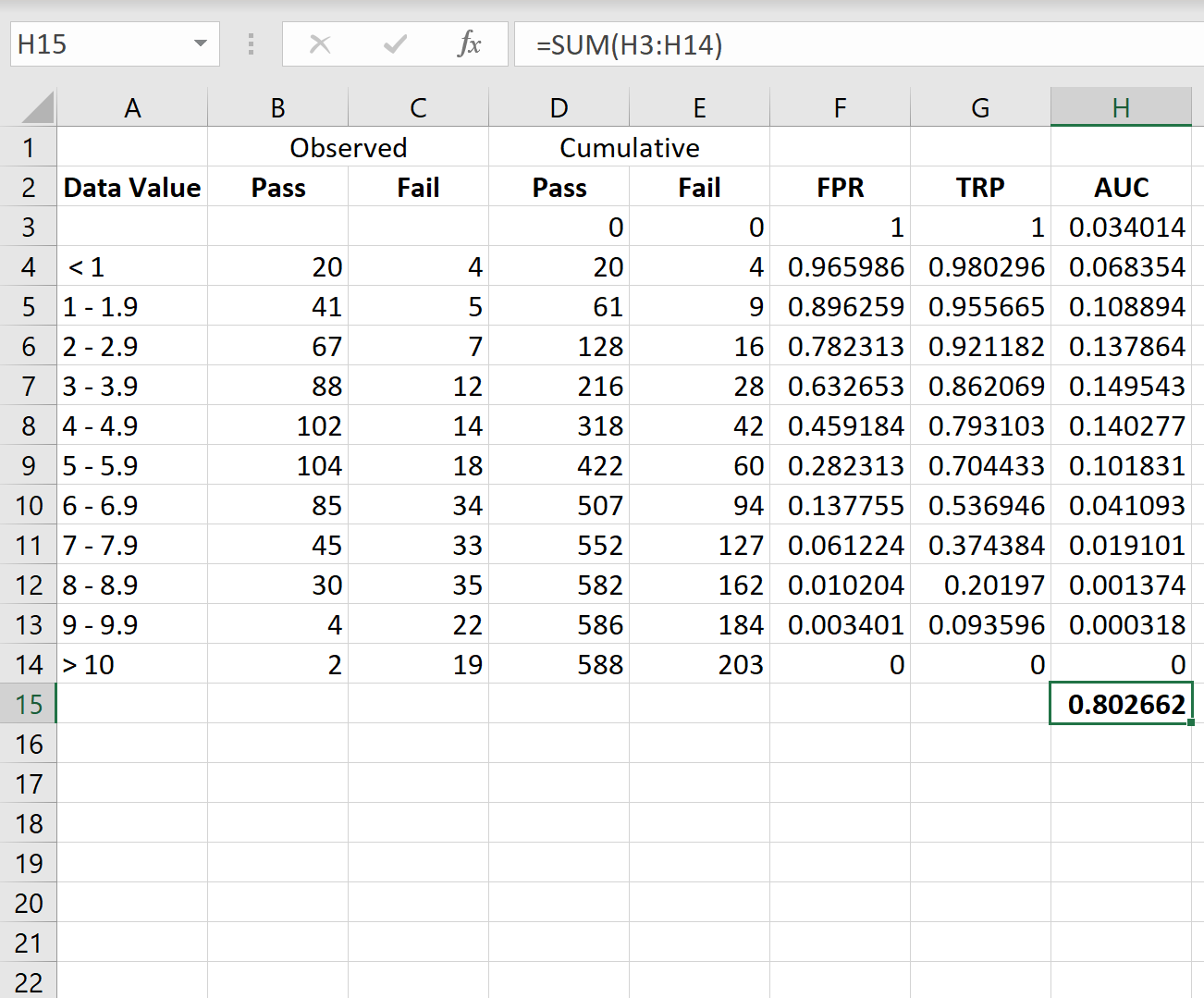
AUC 0.802662 निकला। यह मान काफी अधिक है, जो दर्शाता है कि मॉडल डेटा को “पास” और “फेल” श्रेणियों में वर्गीकृत करने का अच्छा काम करता है।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि एक्सेल में अन्य सामान्य प्लॉट कैसे बनाएं:
एक्सेल में सीडीएफ कैसे प्लॉट करें
एक्सेल में सर्वाइवल कर्व कैसे बनाएं
एक्सेल में सांख्यिकीय प्रक्रिया नियंत्रण चार्ट कैसे बनाएं
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने