सीबॉर्न में वितरण कैसे प्लॉट करें: उदाहरणों के साथ
आप सीबॉर्न डेटा विज़ुअलाइज़ेशन लाइब्रेरी का उपयोग करके पायथन में मूल्यों के वितरण को प्लॉट करने के लिए निम्नलिखित विधियों का उपयोग कर सकते हैं:
विधि 1: हिस्टोग्राम का उपयोग करके वितरण को प्लॉट करें
sns. displot (data)
विधि 2: घनत्व वक्र का उपयोग करके वितरण को प्लॉट करें
sns. displot (data, kind=' kde ')
विधि 3: हिस्टोग्राम और घनत्व वक्र का उपयोग करके वितरण को प्लॉट करें
sns. displot (data, kde= True )
निम्नलिखित उदाहरण दिखाते हैं कि व्यवहार में प्रत्येक विधि का उपयोग कैसे करें।
उदाहरण 1: हिस्टोग्राम का उपयोग करके वितरण को प्लॉट करना
निम्नलिखित कोड दिखाता है कि सीबॉर्न में displot() फ़ंक्शन का उपयोग करके NumPy सरणी में मानों के वितरण को कैसे प्लॉट किया जाए:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create histogram to visualize distribution of values
sns. displot (data)
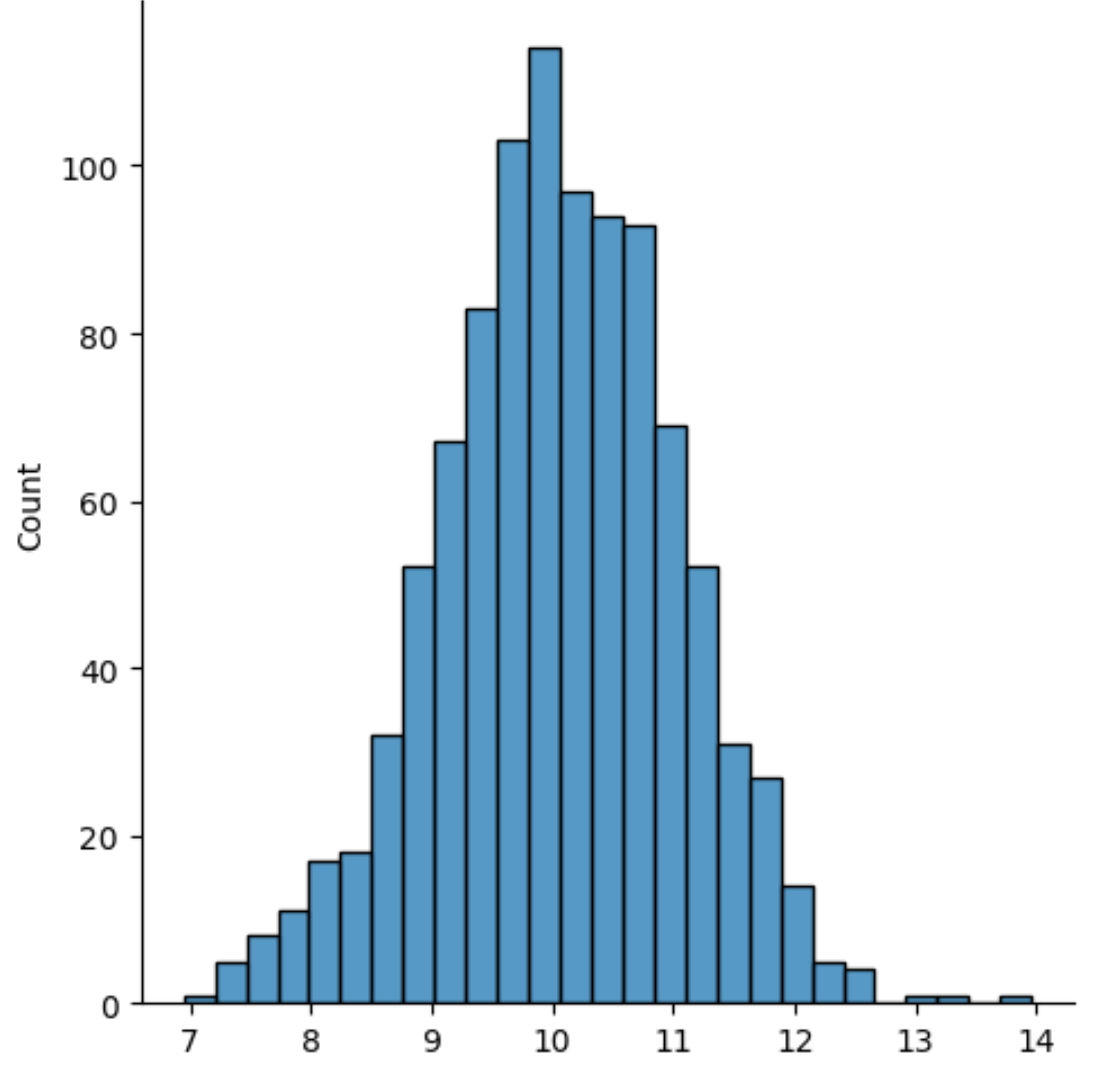
एक्स अक्ष वितरण के मान प्रदर्शित करता है और वाई अक्ष प्रत्येक मान की गिनती प्रदर्शित करता है।
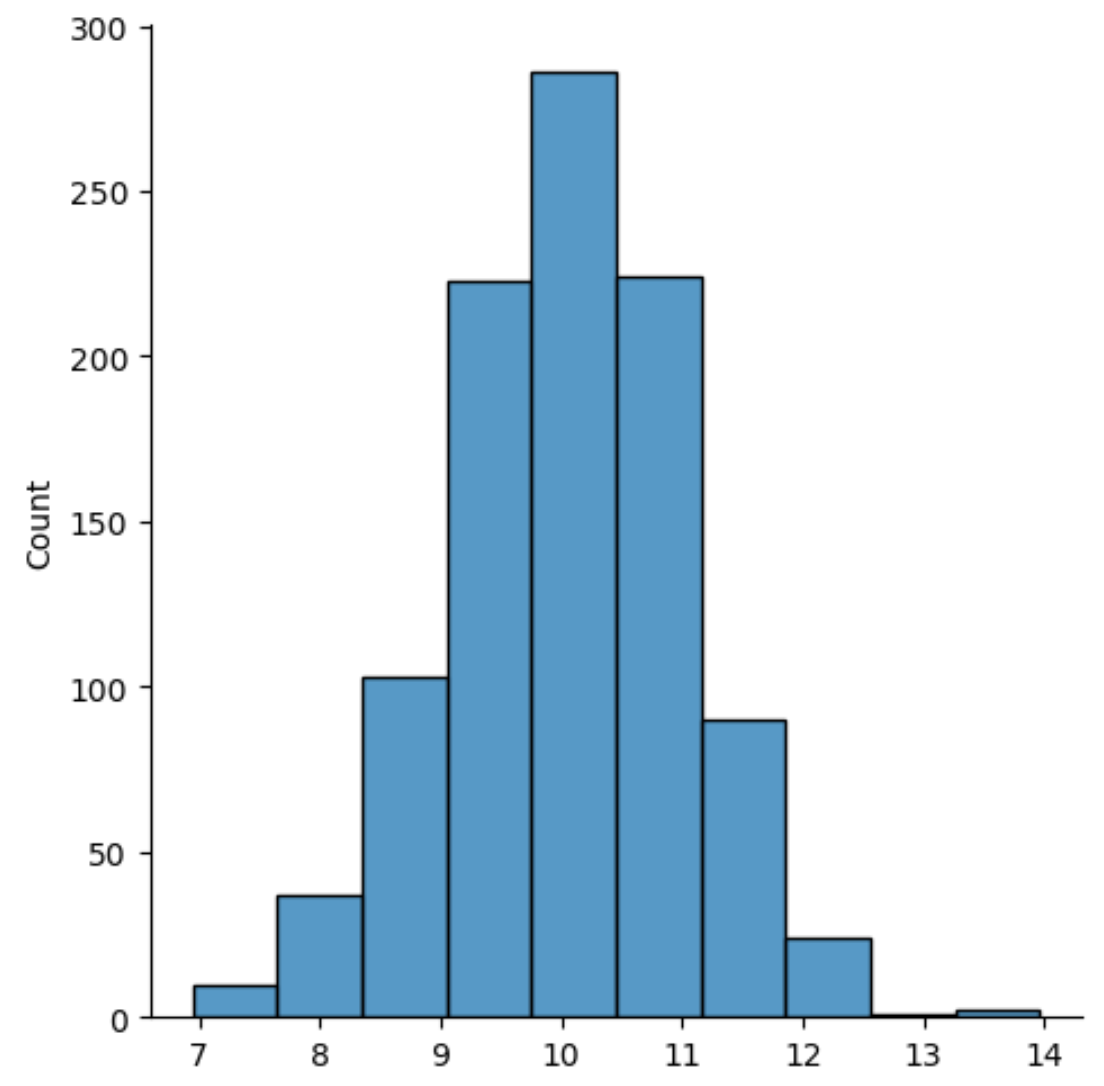
हिस्टोग्राम में उपयोग किए गए डिब्बे की संख्या को बदलने के लिए, आप डिब्बे तर्क का उपयोग करके एक संख्या निर्दिष्ट कर सकते हैं:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create histogram using 10 bins
sns. displot (data, bins= 10 )
उदाहरण 2: घनत्व वक्र का उपयोग करके वितरण को आलेखित करना
निम्नलिखित कोड दिखाता है कि घनत्व वक्र का उपयोग करके NumPy सरणी में मानों के वितरण को कैसे प्लॉट किया जाए:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create density curve to visualize distribution of values
sns. displot (data, kind=' kde ')
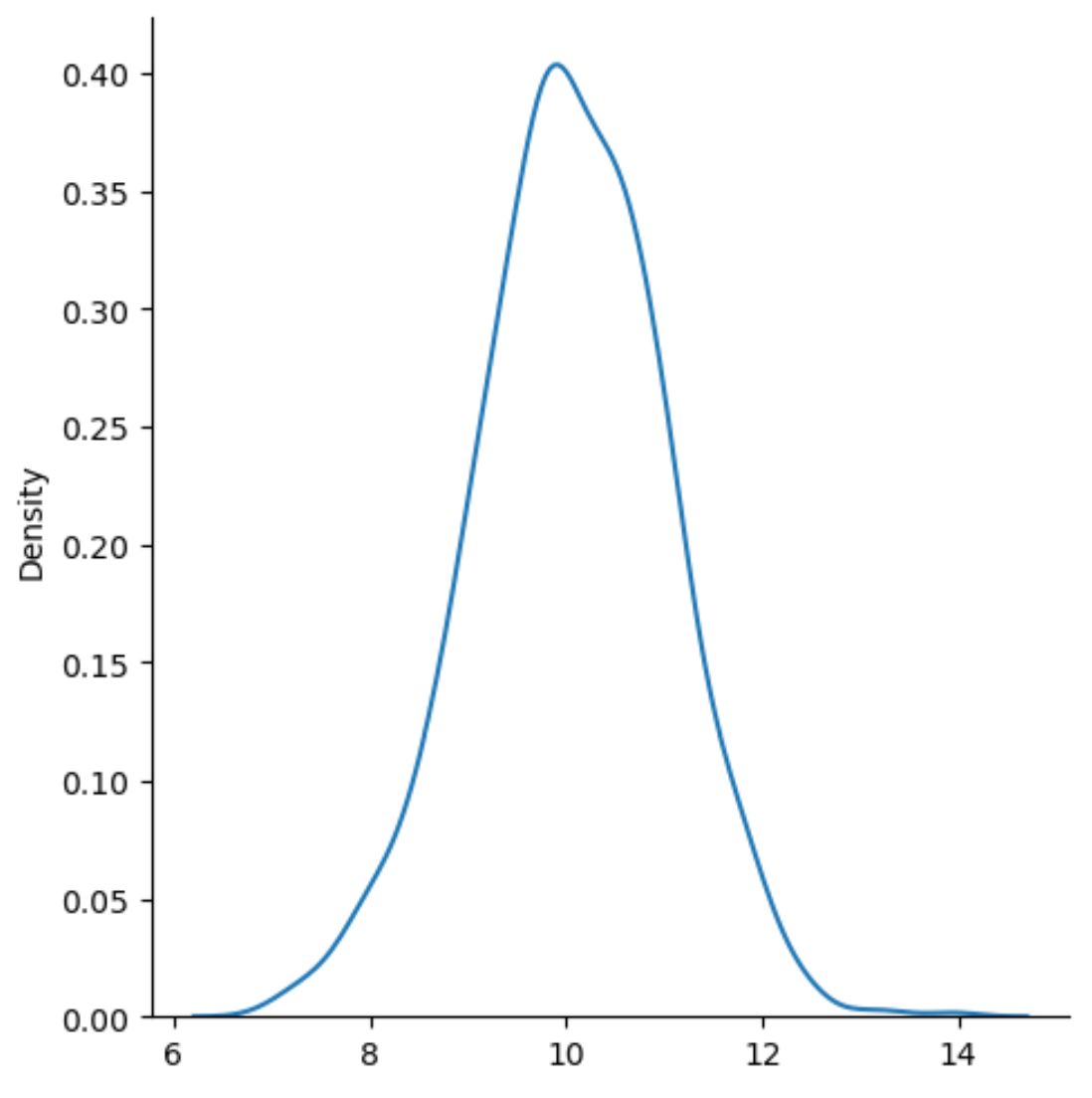
x-अक्ष वितरण के मान प्रदर्शित करता है और y-अक्ष प्रत्येक मान की सापेक्ष आवृत्ति प्रदर्शित करता है।
ध्यान दें कि type=’kde’ सीबॉर्न को कर्नेल घनत्व अनुमान का उपयोग करने के लिए कहता है, जो एक सहज वक्र उत्पन्न करता है जो एक चर के मूल्यों के वितरण को सारांशित करता है।
उदाहरण 3: हिस्टोग्राम और घनत्व वक्र का उपयोग करके वितरण को प्लॉट करना
निम्नलिखित कोड दिखाता है कि घनत्व वक्र के साथ हिस्टोग्राम का उपयोग करके NumPy सरणी में मानों के वितरण को कैसे प्लॉट किया जाए:
import seaborn as sns
import numpy as np
#make this example reproducible
n.p. random . seed ( 1 )
#create array of 1000 values that follows a normal distribution with mean of 10
data = np. random . normal (size= 1000 , loc= 10 )
#create histogram with density curve overlaid to visualize distribution of values
sns. displot (data, kde= True )
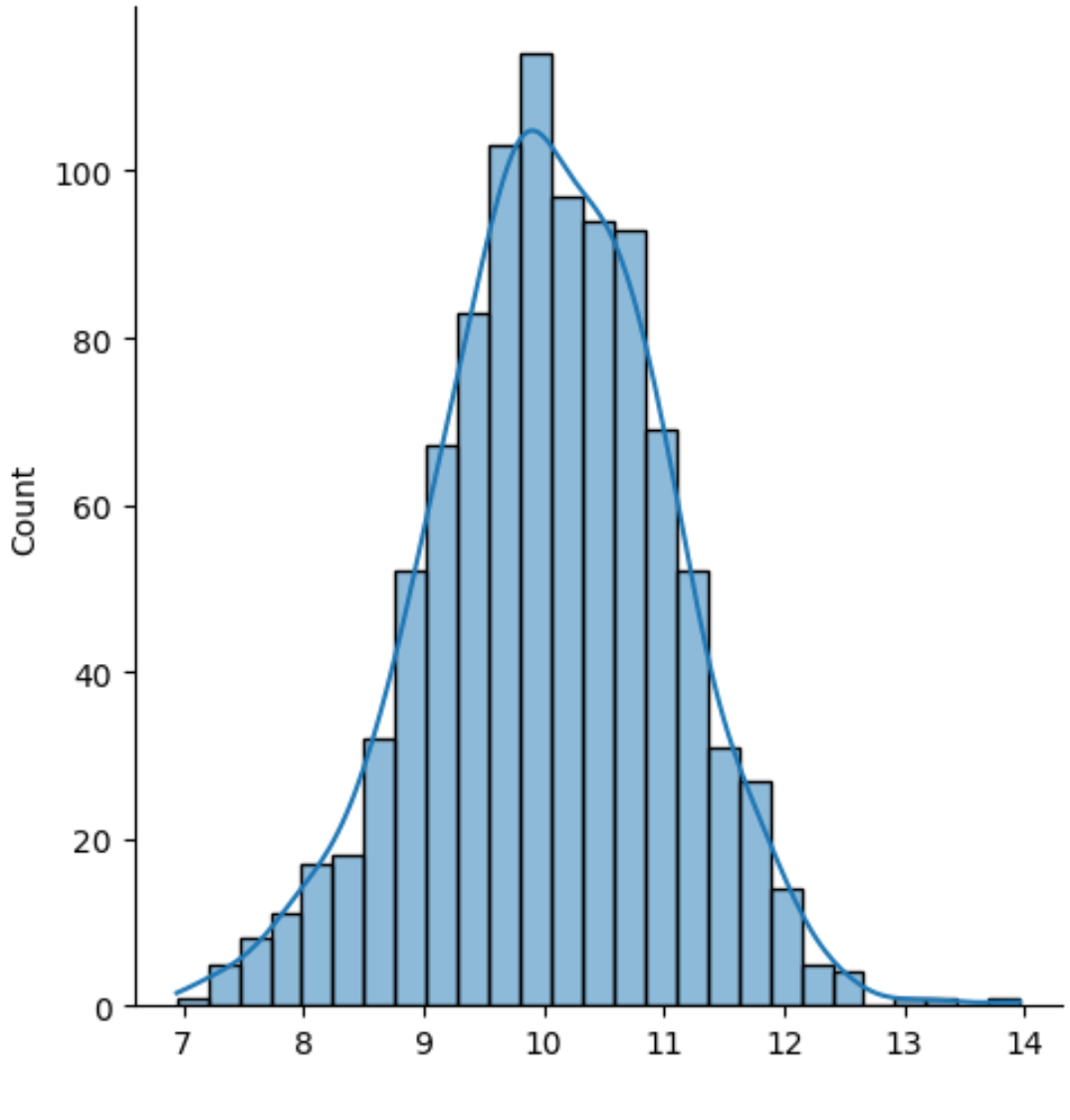
परिणाम एक हिस्टोग्राम है जिस पर घनत्व वक्र आरोपित है।
नोट : आप सीबॉर्न डिस्प्लॉट() फ़ंक्शन के लिए संपूर्ण दस्तावेज़ यहां पा सकते हैं।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि सीबॉर्न का उपयोग करके अन्य सामान्य कार्य कैसे करें:
सीबॉर्न प्लॉट्स में शीर्षक कैसे जोड़ें
सीबॉर्न प्लॉट्स में फ़ॉन्ट आकार कैसे बदलें
सीबॉर्न प्लॉट्स में टिकों की संख्या को कैसे समायोजित करें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने