समूहीकृत डेटा का भिन्नता कैसे खोजें (उदाहरण के साथ)
हम अक्सर समूहीकृत आवृत्ति वितरण के विचरण की गणना करना चाहते हैं।
उदाहरण के लिए, मान लीजिए कि हमारे पास निम्नलिखित समूहीकृत आवृत्ति वितरण है:
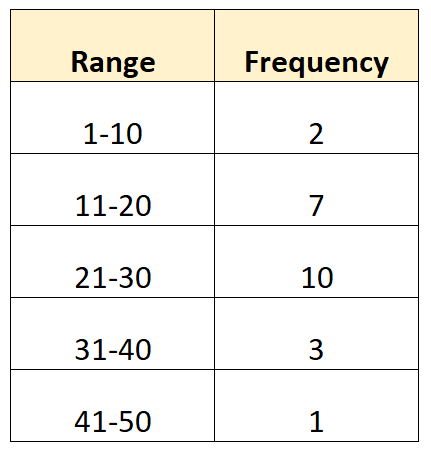
यद्यपि सटीक विचरण की गणना करना संभव नहीं है क्योंकि हम कच्चे डेटा मानों को नहीं जानते हैं, निम्नलिखित सूत्र का उपयोग करके विचरण का अनुमान लगाना संभव है:
प्रसरण: Σn i (m i -μ) 2 / (N-1)
सोना:
- n i : i वें समूह की आवृत्ति
- मील : i वें समूह का मध्य
- μ : औसत
- एन: कुल नमूना आकार
नोट: प्रत्येक समूह का मध्यबिंदु श्रेणी के निचले और ऊपरी मानों का औसत लेकर पाया जा सकता है। उदाहरण के लिए, पहले समूह के मध्यबिंदु की गणना इस प्रकार की जाती है: (1+10) / 2 = 5.5।
निम्नलिखित उदाहरण दिखाता है कि व्यवहार में इस सूत्र का उपयोग कैसे करें।
उदाहरण: समूहीकृत डेटा के विचरण की गणना करें
मान लीजिए हमारे पास निम्नलिखित समूहीकृत डेटा है:
यहां बताया गया है कि हम इस समूहीकृत डेटा के विचरण की गणना करने के लिए पहले बताए गए सूत्र का उपयोग कैसे करेंगे:
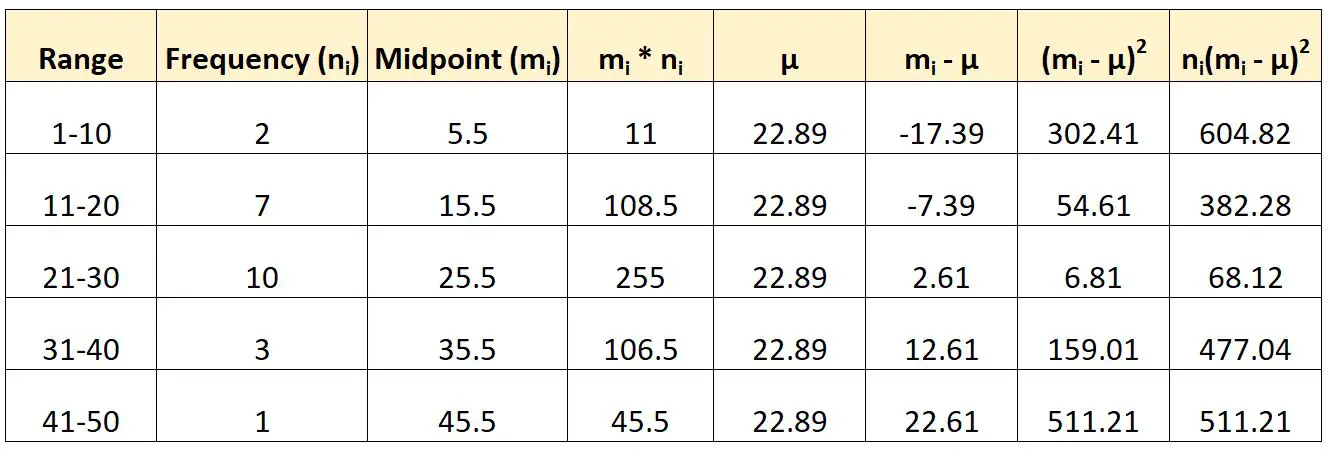
फिर हम विचरण की गणना इस प्रकार करेंगे:
- प्रसरण: Σn i (m i -μ) 2 / (N-1)
- अंतर : (604.82 + 382.28 + 68.12 + 477.04 + 511.21) / (23-1)
- अंतर : 92.885
डेटासेट का विचरण 92.885 निकला।
अतिरिक्त संसाधन
निम्नलिखित ट्यूटोरियल बताते हैं कि समूहीकृत डेटा के लिए अन्य मैट्रिक्स की गणना कैसे करें:
समूहीकृत डेटा का माध्य और मानक विचलन कैसे ज्ञात करें
समूहीकृत डेटा के लिए प्रतिशतक रैंकिंग की गणना कैसे करें
समूहीकृत डेटा का माध्यिका कैसे ज्ञात करें
समूहीकृत डेटा मोड कैसे खोजें
लेखक के बारे में
डॉ. बेंजामिन एंडरसन
नमस्ते, मैं बेंजामिन हूं, एक सेवानिवृत्त सांख्यिकी प्रोफेसर जो अब समर्पित Statorials शिक्षक बन गया है। सांख्यिकी के क्षेत्र में व्यापक अनुभव और विशेषज्ञता के साथ, मैं Statorials के माध्यम से छात्रों को सशक्त बनाने के लिए अपना ज्ञान साझा करने के लिए उत्सुक हूं। अधिक जाने