Kode Python lengkap yang digunakan dalam tutorial ini dapat ditemukan di sini .
Cara melakukan regresi logistik dengan python (langkah demi langkah)
Regresi logistik adalah metode yang dapat kita gunakan untuk menyesuaikan model regresi ketika variabel responnya adalah biner.
Regresi logistik menggunakan metode yang disebut estimasi kemungkinan maksimum untuk mencari persamaan dalam bentuk berikut:
log[p(X) / ( 1 -p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Emas:
- X j : variabel prediktif ke -j
- β j : estimasi koefisien variabel prediktif ke- j
Rumus di sisi kanan persamaan memprediksi log odds bahwa variabel respons bernilai 1.
Jadi, ketika kita menyesuaikan model regresi logistik, kita dapat menggunakan persamaan berikut untuk menghitung probabilitas bahwa observasi tertentu bernilai 1:
p(X) = e β 0 + β 1 X 1 + β 2 X 2 + … + β p
Kami kemudian menggunakan ambang probabilitas tertentu untuk mengklasifikasikan observasi sebagai 1 atau 0.
Misalnya, kita dapat mengatakan bahwa observasi dengan probabilitas lebih besar atau sama dengan 0,5 akan diklasifikasikan sebagai “1” dan semua observasi lainnya akan diklasifikasikan sebagai “0”.
Tutorial ini memberikan contoh langkah demi langkah tentang cara melakukan regresi logistik di R.
Langkah 1: Impor paket yang diperlukan
Pertama, kita akan mengimpor paket yang diperlukan untuk melakukan regresi logistik dengan Python:
import pandas as pd import numpy as np from sklearn. model_selection import train_test_split from sklearn. linear_model import LogisticRegression from sklearn import metrics import matplotlib. pyplot as plt
Langkah 2: Muat data
Untuk contoh ini, kita akan menggunakan dataset default dari buku Pengantar Pembelajaran Statistik . Kita dapat menggunakan kode berikut untuk memuat dan menampilkan ringkasan kumpulan data:
#import dataset from CSV file on Github url = "https://raw.githubusercontent.com/Statorials/Python-Guides/main/default.csv" data = pd. read_csv (url) #view first six rows of dataset data[0:6] default student balance income 0 0 0 729.526495 44361.625074 1 0 1 817.180407 12106.134700 2 0 0 1073.549164 31767.138947 3 0 0 529.250605 35704.493935 4 0 0 785.655883 38463.495879 5 0 1 919.588530 7491.558572 #find total observations in dataset len( data.index ) 10000
Kumpulan data ini berisi informasi berikut tentang 10.000 individu:
- default: menunjukkan apakah seseorang mengalami default atau tidak.
- pelajar: menunjukkan apakah seseorang adalah pelajar atau bukan.
- saldo: Saldo rata-rata yang dibawa oleh seorang individu.
- pendapatan: Pendapatan individu.
Kami akan menggunakan status pelajar, saldo bank, dan pendapatan untuk membangun model regresi logistik yang memprediksi kemungkinan seseorang mengalami gagal bayar.
Langkah 3: Buat sampel pelatihan dan pengujian
Selanjutnya, kita akan membagi kumpulan data menjadi kumpulan pelatihan untuk melatih model dan kumpulan pengujian untuk menguji model.
#define the predictor variables and the response variable X = data[[' student ',' balance ',' income ']] y = data[' default '] #split the dataset into training (70%) and testing (30%) sets X_train,X_test,y_train,y_test = train_test_split (X,y,test_size=0.3,random_state=0)
Langkah 4: Sesuaikan model regresi logistik
Selanjutnya, kita akan menggunakan fungsi LogisticRegression() untuk menyesuaikan model regresi logistik dengan kumpulan data:
#instantiate the model log_regression = LogisticRegression() #fit the model using the training data log_regression. fit (X_train,y_train) #use model to make predictions on test data y_pred = log_regression. predict (X_test)
Langkah 5: Diagnostik Model
Setelah kami memasang model regresi, kami kemudian dapat menganalisis performa model kami pada kumpulan data pengujian.
Pertama, kita akan membuat matriks konfusi untuk model tersebut:
cnf_matrix = metrics. confusion_matrix (y_test, y_pred)
cnf_matrix
array([[2886, 1],
[113,0]])
Dari matriks konfusi kita dapat melihat bahwa:
- #Prediksi positif yang benar: 2886
- #Prediksi negatif yang benar: 0
- #Prediksi positif palsu: 113
- #Prediksi negatif palsu: 1
Kita juga bisa mendapatkan model akurasi, yang memberi tahu kita persentase prediksi koreksi yang dibuat oleh model tersebut:
print(" Accuracy: ", metrics.accuracy_score (y_test, y_pred))l
Accuracy: 0.962
Hal ini menunjukkan bahwa model tersebut membuat prediksi yang benar mengenai apakah seseorang akan gagal bayar sebanyak 96,2% atau tidak.
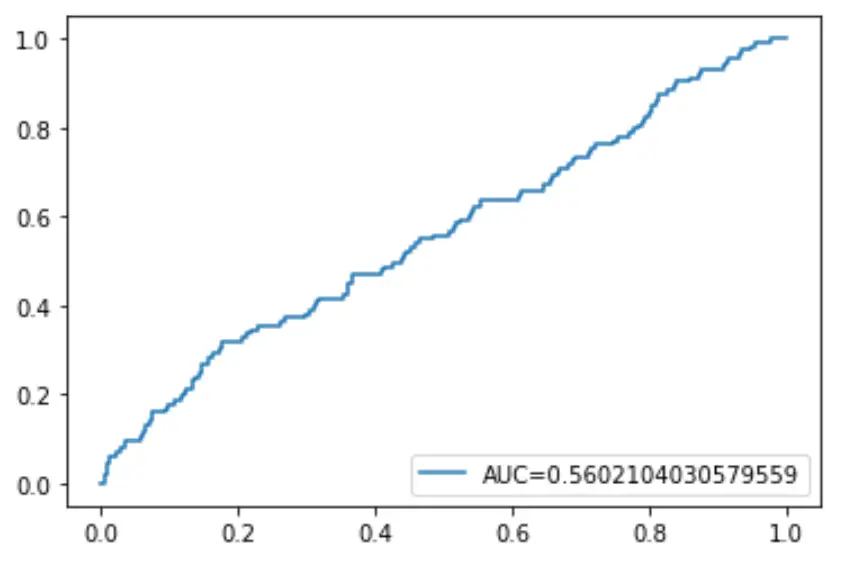
Terakhir, kita dapat memplot kurva Karakteristik Operasi Penerima (ROC) yang menampilkan persentase positif sebenarnya yang diprediksi oleh model ketika ambang batas probabilitas prediksi diturunkan dari 1 menjadi 0.
Semakin tinggi AUC (area di bawah kurva), semakin akurat model kami dalam memprediksi hasil:
#define metrics
y_pred_proba = log_regression. predict_proba (X_test)[::,1]
fpr, tpr, _ = metrics. roc_curve (y_test, y_pred_proba)
auc = metrics. roc_auc_score (y_test, y_pred_proba)
#create ROC curve
plt. plot (fpr,tpr,label=" AUC= "+str(auc))
plt. legend (loc=4)
plt. show ()
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya