Cara menyesuaikan pohon klasifikasi dan regresi di r
Jika hubungan antara sekumpulan variabel prediktor dan variabel respons bersifat linier, metode seperti regresi linier berganda dapat menghasilkan model prediksi yang akurat.
Namun, ketika hubungan antara sekumpulan prediktor dan respons lebih kompleks, metode nonlinier seringkali dapat menghasilkan model yang lebih akurat.
Salah satu metode tersebut adalah pohon klasifikasi dan regresi (CART), yang menggunakan sekumpulan variabel prediktor untuk membuat pohon keputusan yang memprediksi nilai variabel respons.
Jika variabel responnya kontinu kita dapat membuat pohon regresi dan jika variabel responnya bersifat kategoris kita dapat membuat pohon klasifikasi.
Tutorial ini menjelaskan cara membuat pohon regresi dan klasifikasi di R.
Contoh 1: Membangun Pohon Regresi di R
Untuk contoh ini, kami akan menggunakan dataset Hitters dari paket ISLR , yang berisi berbagai informasi tentang 263 pemain baseball profesional.
Kami akan menggunakan kumpulan data ini untuk membuat pohon regresi yang menggunakan variabel prediktor home run dan tahun bermain untuk memprediksi gaji pemain tertentu.
Gunakan langkah-langkah berikut untuk membuat pohon regresi ini.
Langkah 1: Muat paket yang diperlukan.
Pertama, kami akan memuat paket yang diperlukan untuk contoh ini:
library (ISLR) #contains Hitters dataset library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
Langkah 2: Bangun pohon regresi awal.
Pertama, kita akan membuat pohon regresi awal yang besar. Kami dapat menjamin bahwa pohonnya besar dengan menggunakan nilai cp yang kecil, yang merupakan singkatan dari “parameter kompleksitas”.
Artinya kita akan melakukan pemisahan lebih lanjut pada pohon regresi selama keseluruhan R-kuadrat model meningkat setidaknya sebesar nilai yang ditentukan oleh cp.
Kami kemudian akan menggunakan fungsi printcp() untuk mencetak hasil model:
#build the initial tree
tree <- rpart(Salary ~ Years + HmRun, data=Hitters, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] HmRun Years
Root node error: 53319113/263 = 202734
n=263 (59 observations deleted due to missingness)
CP nsplit rel error xerror xstd
1 0.24674996 0 1.00000 1.00756 0.13890
2 0.10806932 1 0.75325 0.76438 0.12828
3 0.01865610 2 0.64518 0.70295 0.12769
4 0.01761100 3 0.62652 0.70339 0.12337
5 0.01747617 4 0.60891 0.70339 0.12337
6 0.01038188 5 0.59144 0.66629 0.11817
7 0.01038065 6 0.58106 0.65697 0.11687
8 0.00731045 8 0.56029 0.67177 0.11913
9 0.00714883 9 0.55298 0.67881 0.11960
10 0.00708618 10 0.54583 0.68034 0.11988
11 0.00516285 12 0.53166 0.68427 0.11997
12 0.00445345 13 0.52650 0.68994 0.11996
13 0.00406069 14 0.52205 0.68988 0.11940
14 0.00264728 15 0.51799 0.68874 0.11916
15 0.00196586 16 0.51534 0.68638 0.12043
16 0.00016686 17 0.51337 0.67577 0.11635
17 0.00010000 18 0.51321 0.67576 0.11615
n=263 (59 observations deleted due to missingness)
Langkah 3: Pangkas pohonnya.
Selanjutnya, kita akan memangkas pohon regresi untuk menemukan nilai optimal yang digunakan untuk cp (parameter kompleksitas) yang menghasilkan kesalahan pengujian terendah.
Perhatikan bahwa nilai optimal untuk cp adalah nilai yang mengarah ke kesalahan x terendah pada keluaran sebelumnya, yang mewakili kesalahan observasi dari data validasi silang.
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output

Kita dapat melihat bahwa pohon terakhir yang dipangkas memiliki enam simpul terminal. Setiap node daun menampilkan prediksi gaji pemain di node tersebut serta jumlah observasi dari kumpulan data asli milik kelas tersebut.
Misalnya, kita dapat melihat bahwa dalam kumpulan data asli, terdapat 90 pemain dengan pengalaman kurang dari 4,5 tahun dan gaji rata-rata mereka adalah $225,83K.
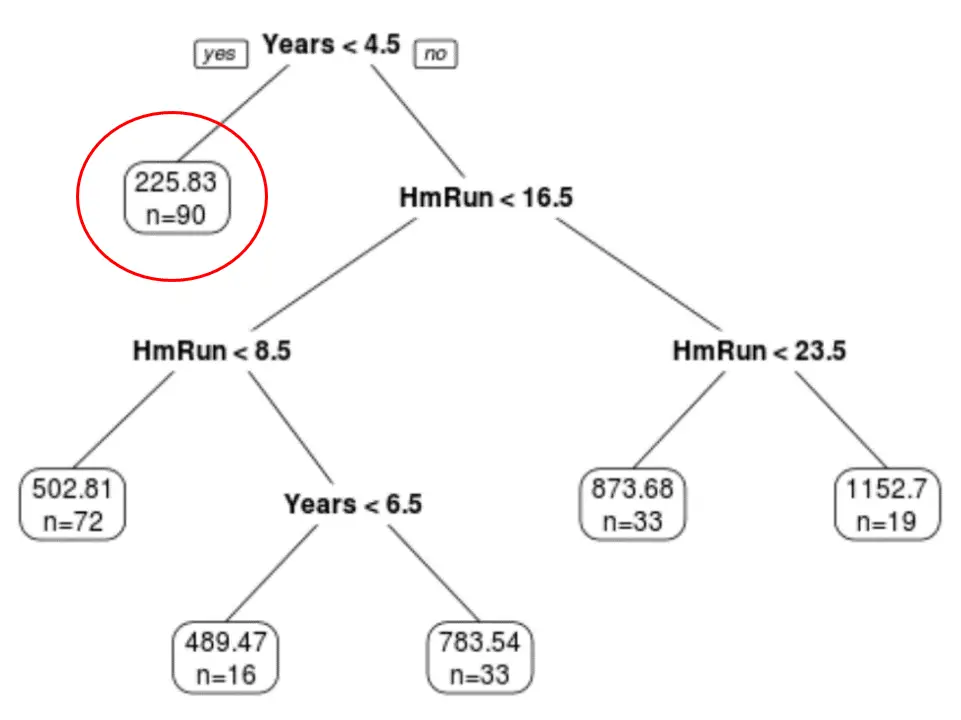
Langkah 4: Gunakan pohon untuk membuat prediksi.
Kita dapat menggunakan pohon yang dipangkas terakhir untuk memprediksi gaji pemain tertentu berdasarkan pengalamannya selama bertahun-tahun dan rata-rata home run.
Misalnya, seorang pemain yang memiliki pengalaman 7 tahun dan rata-rata 4 home run memiliki gaji yang diharapkan sebesar $502,81k .
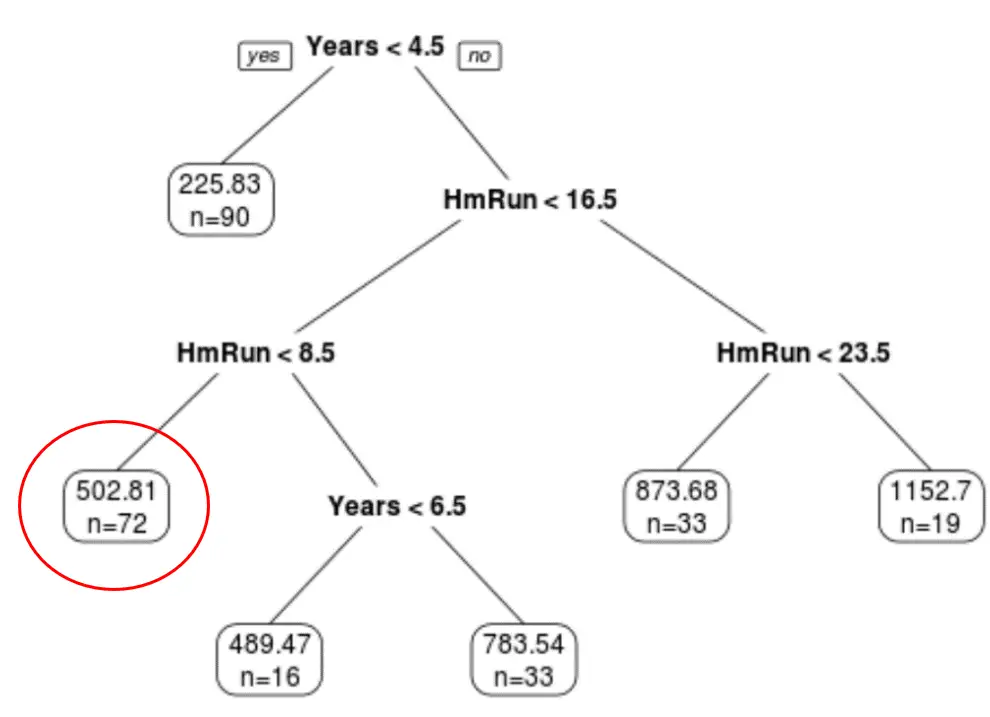
Kita dapat menggunakan fungsi prediksi() di R untuk mengonfirmasi hal ini:
#define new player
new <- data.frame(Years=7, HmRun=4)
#use pruned tree to predict salary of this player
predict(pruned_tree, newdata=new)
502.8079
Contoh 2: Membangun pohon klasifikasi di R
Untuk contoh ini, kami akan menggunakan dataset ptitanic dari paket rpart.plot , yang berisi berbagai informasi tentang penumpang kapal Titanic.
Kami akan menggunakan kumpulan data ini untuk membuat pohon klasifikasi yang menggunakan variabel prediktor kelas , jenis kelamin , dan usia untuk memprediksi apakah penumpang tertentu selamat atau tidak.
Gunakan langkah-langkah berikut untuk membuat pohon klasifikasi ini.
Langkah 1: Muat paket yang diperlukan.
Pertama, kami akan memuat paket yang diperlukan untuk contoh ini:
library (rpart) #for fitting decision trees library (rpart.plot) #for plotting decision trees
Langkah 2: Bangun pohon klasifikasi awal.
Pertama, kita akan membangun pohon klasifikasi awal yang besar. Kami dapat menjamin bahwa pohonnya besar dengan menggunakan nilai cp yang kecil, yang merupakan singkatan dari “parameter kompleksitas”.
Artinya kita akan melakukan pemisahan lebih lanjut pada pohon klasifikasi selama kecocokan model secara keseluruhan meningkat setidaknya sebesar nilai yang ditentukan oleh cp.
Kami kemudian akan menggunakan fungsi printcp() untuk mencetak hasil model:
#build the initial tree
tree <- rpart(survived~pclass+sex+age, data=ptitanic, control=rpart. control (cp= .0001 ))
#view results
printcp(tree)
Variables actually used in tree construction:
[1] age pclass sex
Root node error: 500/1309 = 0.38197
n=1309
CP nsplit rel error xerror xstd
1 0.4240 0 1.000 1.000 0.035158
2 0.0140 1 0.576 0.576 0.029976
3 0.0095 3 0.548 0.578 0.030013
4 0.0070 7 0.510 0.552 0.029517
5 0.0050 9 0.496 0.528 0.029035
6 0.0025 11 0.486 0.532 0.029117
7 0.0020 19 0.464 0.536 0.029198
8 0.0001 22 0.458 0.528 0.029035
Langkah 3: Pangkas pohonnya.
Selanjutnya, kita akan memangkas pohon regresi untuk menemukan nilai optimal yang digunakan untuk cp (parameter kompleksitas) yang menghasilkan kesalahan pengujian terendah.
Perhatikan bahwa nilai optimal untuk cp adalah nilai yang mengarah ke kesalahan x terendah pada keluaran sebelumnya, yang mewakili kesalahan observasi dari data validasi silang.
#identify best cp value to use
best <- tree$cptable[which. min (tree$cptable[," xerror "])," CP "]
#produce a pruned tree based on the best cp value
pruned_tree <- prune (tree, cp=best)
#plot the pruned tree
prp(pruned_tree,
faclen= 0 , #use full names for factor labels
extra= 1 , #display number of obs. for each terminal node
roundint= F , #don't round to integers in output
digits= 5 ) #display 5 decimal places in output
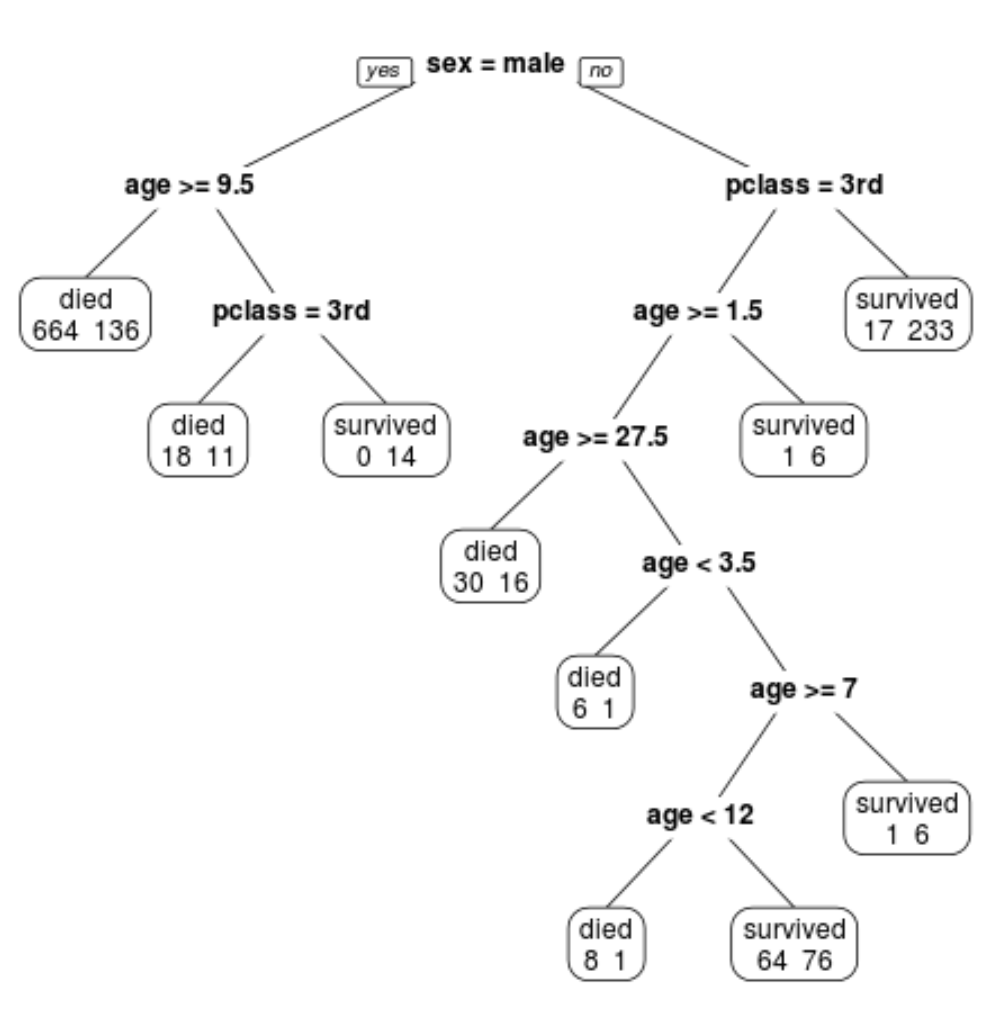
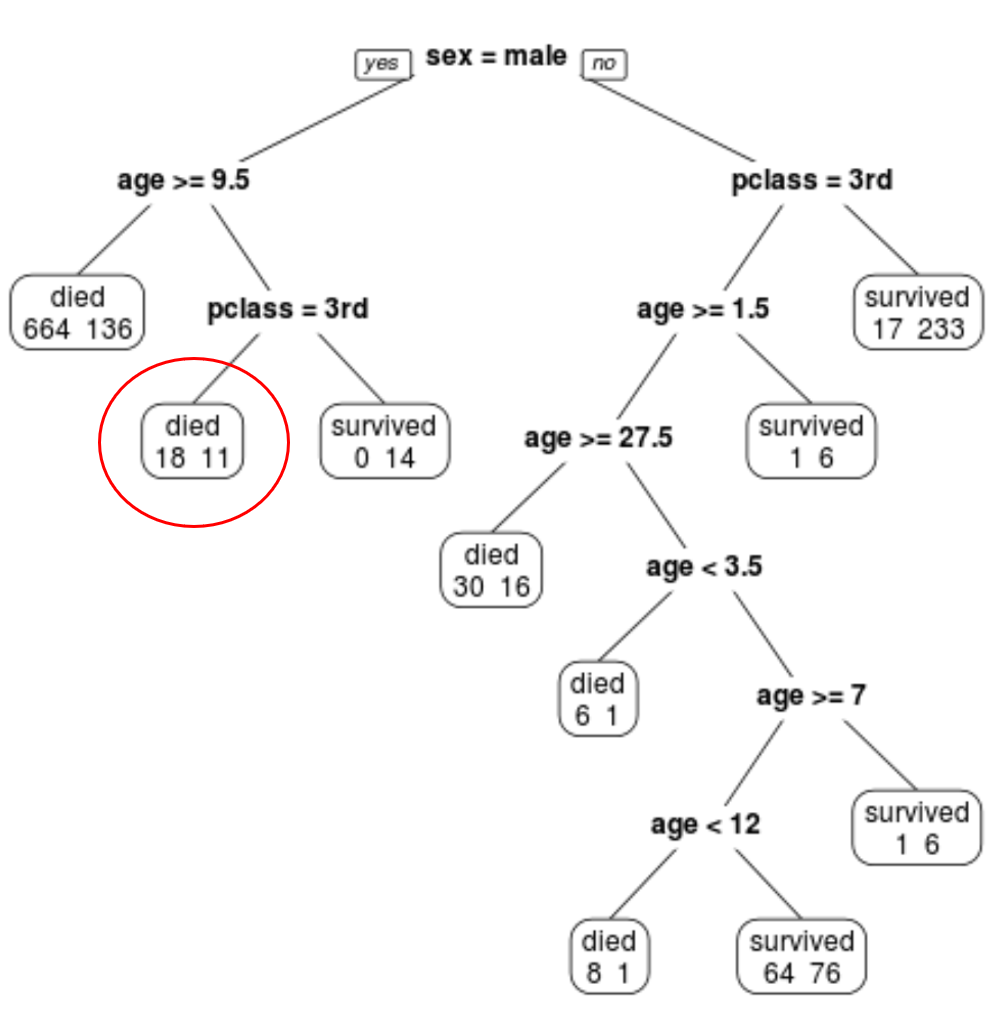
Kita dapat melihat bahwa pohon terakhir yang dipangkas memiliki 10 simpul terminal. Setiap simpul terminal menunjukkan jumlah penumpang yang meninggal serta jumlah yang selamat.
Misalnya, pada node paling kiri kita melihat 664 penumpang meninggal dan 136 selamat.
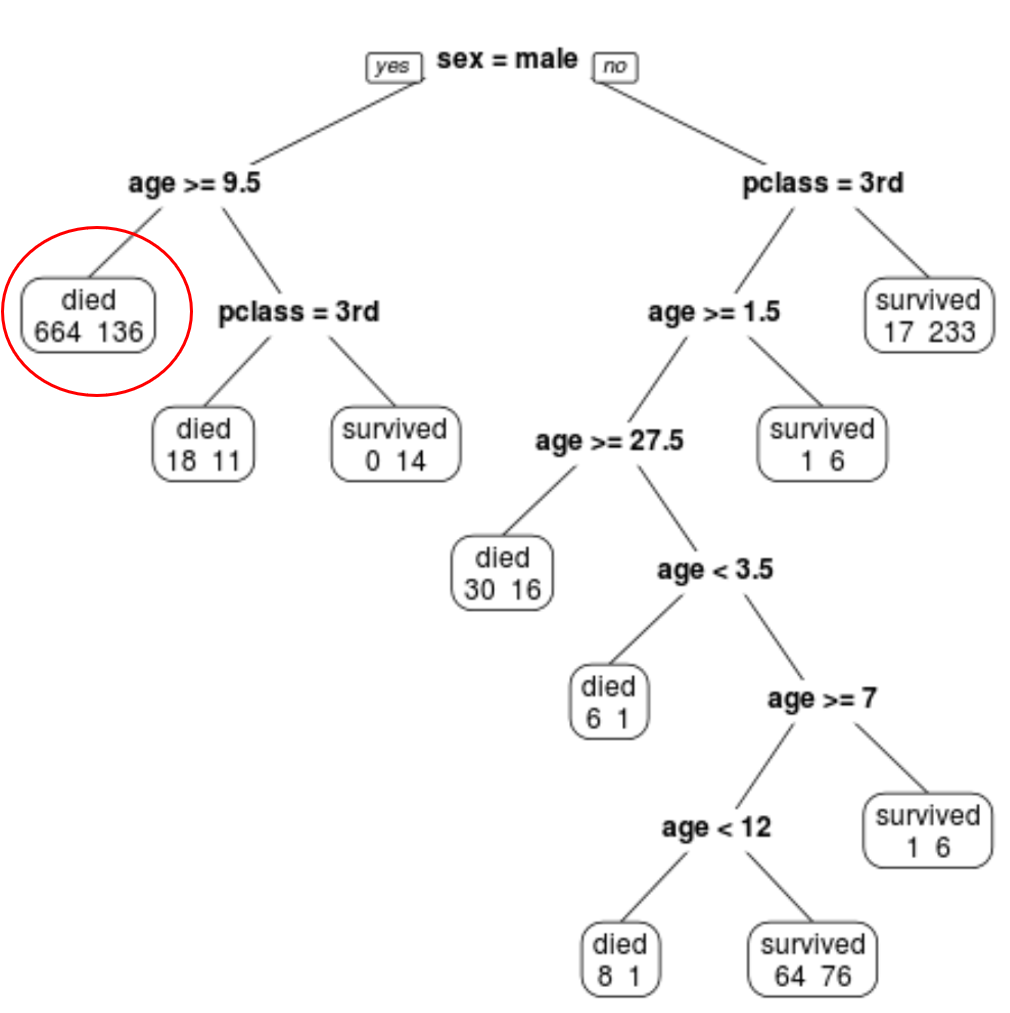
Langkah 4: Gunakan pohon untuk membuat prediksi.
Kita dapat menggunakan pohon terakhir yang dipangkas untuk memprediksi kemungkinan penumpang tertentu bertahan hidup berdasarkan kelas, usia, dan jenis kelamin mereka.
Misalnya, seorang penumpang laki-laki berusia 8 tahun dan duduk di kelas 1 memiliki probabilitas bertahan hidup 11/29 = 37,9%.
Anda dapat menemukan kode R lengkap yang digunakan dalam contoh ini di sini .
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya