Apa itu data berdimensi tinggi? (definisi & contoh)
Data berdimensi tinggi mengacu pada kumpulan data yang jumlah fitur p lebih besar daripada jumlah observasi N , sering ditulis sebagai p >> N.
Misalnya, kumpulan data dengan p = 6 fitur dan hanya N = 3 observasi akan dianggap data berdimensi tinggi karena jumlah fitur lebih banyak daripada jumlah observasi.
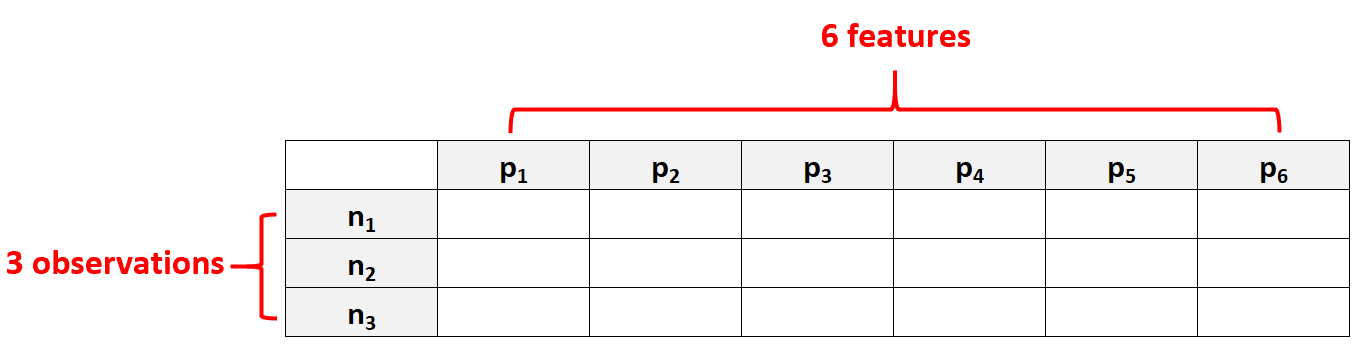
Kesalahan umum yang dilakukan orang adalah berasumsi bahwa “data berdimensi tinggi” berarti kumpulan data dengan banyak fitur. Namun, hal ini tidak benar. Sebuah kumpulan data mungkin berisi 10.000 fitur, tetapi jika berisi 100.000 observasi, maka data tersebut tidak berdimensi tinggi.
Catatan: Lihat Bab 18 Elemen Pembelajaran Statistik untuk diskusi mendalam tentang matematika di balik data berdimensi tinggi.
Mengapa data berdimensi tinggi menjadi masalah?
Ketika jumlah fitur dalam kumpulan data melebihi jumlah observasi, kita tidak akan pernah memiliki jawaban deterministik.
Dengan kata lain, menjadi tidak mungkin menemukan model yang dapat menggambarkan hubungan antara variabel prediktor dan variabel respon , karena kita tidak memiliki cukup observasi untuk melatih model tersebut.
Contoh data berdimensi tinggi
Contoh berikut mengilustrasikan kumpulan data berdimensi tinggi di domain berbeda.
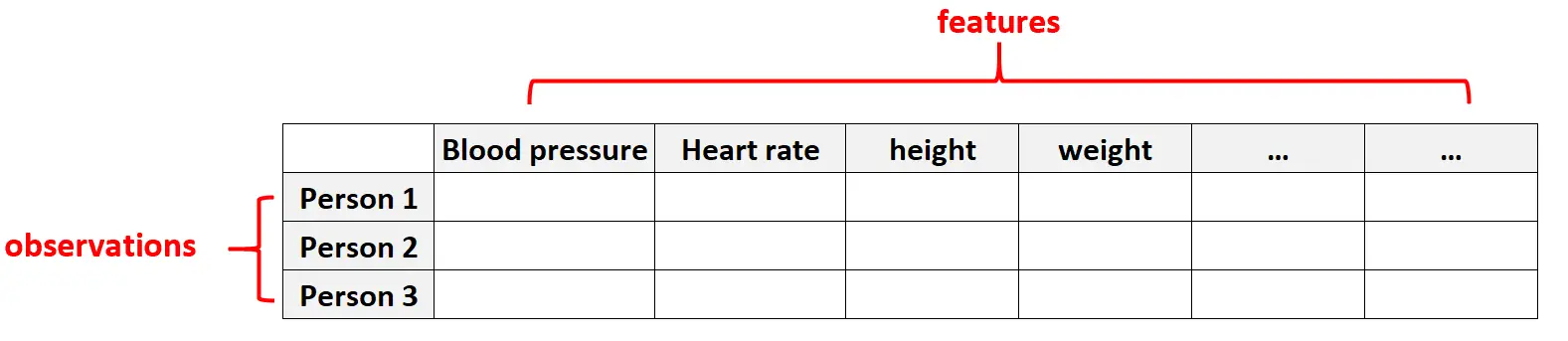
Contoh 1: Data kesehatan
Data berdimensi tinggi adalah hal yang umum dalam kumpulan data layanan kesehatan yang jumlah fiturnya untuk individu tertentu bisa sangat banyak (yaitu tekanan darah, detak jantung saat istirahat, status sistem kekebalan, riwayat bedah, tinggi badan, berat badan, kondisi yang ada, dll.).
Dalam kumpulan data ini, biasanya jumlah fitur lebih banyak daripada jumlah observasi.
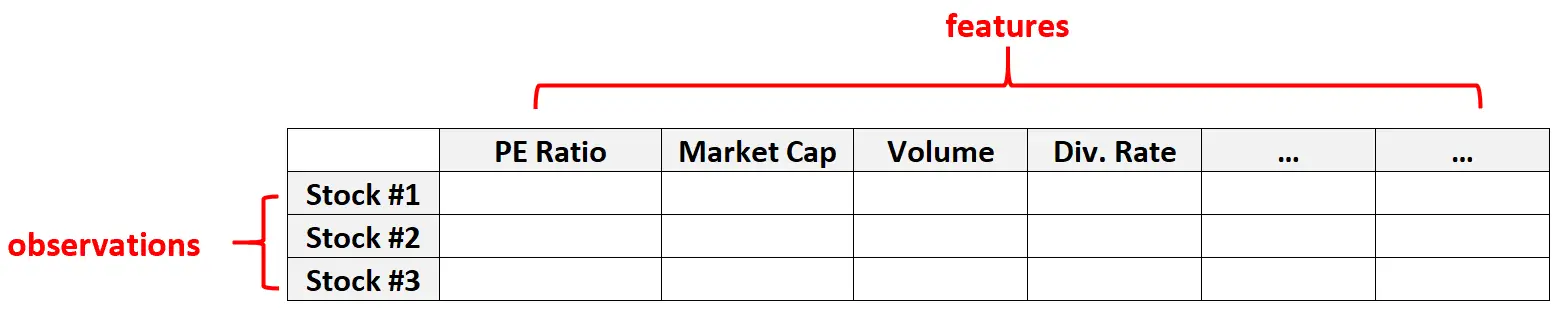
Contoh 2: data keuangan
Data berdimensi tinggi juga umum terjadi pada kumpulan data keuangan yang jumlah fiturnya untuk suatu saham tertentu bisa sangat besar (yaitu rasio PE, kapitalisasi pasar, volume perdagangan, tingkat dividen, dll.)
Dalam jenis kumpulan data ini, biasanya jumlah entitas jauh lebih besar dibandingkan jumlah tindakan individual.
Contoh 3: Genomik
Data berdimensi tinggi juga umum terjadi di bidang genomik, di mana jumlah karakteristik genetik suatu individu bisa sangat banyak.

Cara menangani data berukuran besar
Ada dua cara umum untuk memproses data berdimensi tinggi:
1. Pilih untuk menyertakan lebih sedikit fitur.
Cara paling jelas untuk menghindari berurusan dengan data berdimensi tinggi adalah dengan menyertakan lebih sedikit fitur dalam kumpulan data.
Ada beberapa cara untuk memutuskan fitur mana yang akan dihapus dari kumpulan data, antara lain:
- Hapus fitur dengan banyak nilai yang hilang: Jika kolom tertentu dalam kumpulan data memiliki banyak nilai yang hilang, Anda mungkin dapat menghapusnya sepenuhnya tanpa kehilangan banyak informasi.
- Hapus fitur varian rendah: Jika kolom tertentu dalam kumpulan data memiliki nilai yang sangat sedikit berubah, Anda mungkin dapat menghapusnya karena kolom tersebut kemungkinan tidak memberikan informasi berguna tentang variabel respons sebanyak fitur lainnya.
- Hapus fitur dengan korelasi rendah dengan variabel respons: Jika fitur tertentu tidak berkorelasi tinggi dengan variabel respons yang Anda minati, Anda mungkin dapat menghapusnya dari kumpulan data, karena kemungkinan besar fitur tersebut tidak berguna dalam model.
2. Gunakan metode regularisasi.
Cara lain untuk menangani data berdimensi tinggi tanpa menghapus fitur dari kumpulan data adalah dengan menggunakan teknik regularisasi seperti:
Masing-masing teknik ini dapat digunakan untuk memproses data berdimensi tinggi secara efisien.
Anda dapat menemukan daftar lengkap semua tutorial pembelajaran mesin statistik di halaman ini .
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya