Set validasi dan set pengujian: apa bedanya?
Setiap kali kami mengadaptasi algoritme pembelajaran mesin ke kumpulan data, kami biasanya membagi kumpulan data menjadi tiga bagian:
1. Training set : digunakan untuk melatih model.
2. Set validasi : digunakan untuk mengoptimalkan parameter model.
3. Set pengujian : digunakan untuk memperoleh estimasi kinerja model akhir yang tidak bias.
Diagram berikut memberikan penjelasan visual tentang ketiga tipe kumpulan data yang berbeda ini:
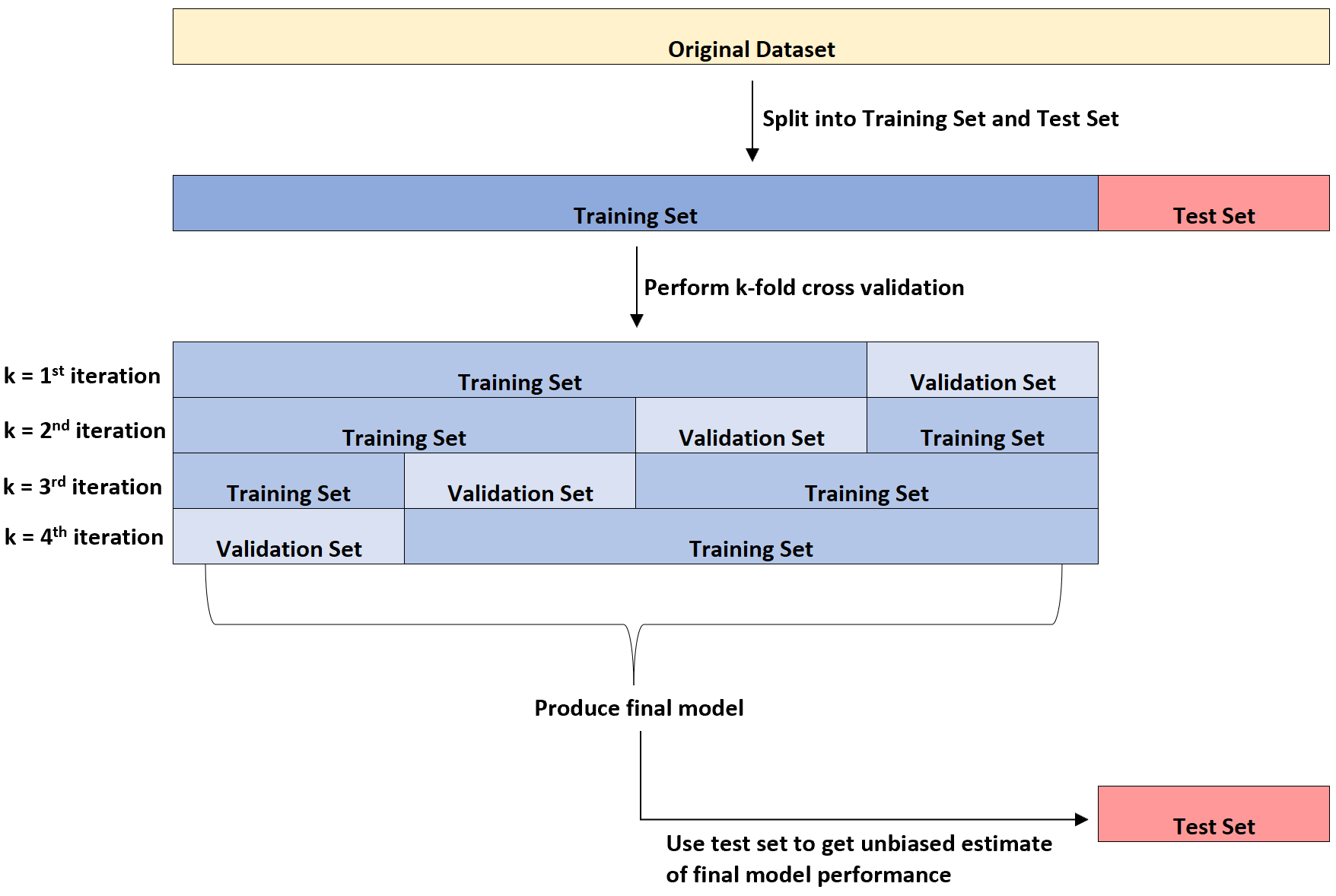
Salah satu hal yang membingungkan siswa adalah perbedaan antara set validasi dan set tes.
Sederhananya, set validasi digunakan untuk mengoptimalkan parameter model, sedangkan set pengujian digunakan untuk memberikan estimasi model akhir yang tidak bias.
Dapat ditunjukkan bahwa tingkat kesalahan yang diukur dengan validasi silang k-fold cenderung meremehkan tingkat kesalahan sebenarnya setelah model diterapkan pada kumpulan data yang tidak terlihat.
Oleh karena itu, kami menyesuaikan model akhir ke set pengujian untuk mendapatkan perkiraan yang tidak bias tentang tingkat kesalahan sebenarnya di dunia nyata.
Contoh berikut mengilustrasikan perbedaan antara set validasi dan set pengujian dalam praktiknya.
Contoh: Memahami perbedaan antara set validasi dan set pengujian
Katakanlah seorang investor real estate ingin menggunakan (1) jumlah kamar tidur, (2) jumlah total kaki persegi, dan (3) jumlah kamar mandi untuk memprediksi harga jual suatu rumah.
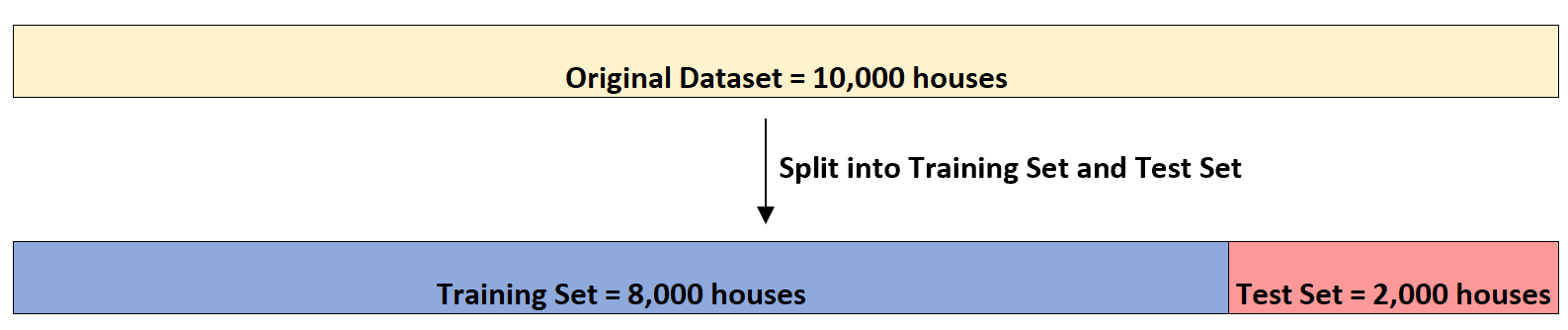
Katakanlah dia memiliki kumpulan data dengan informasi tentang 10.000 rumah. Pertama, dataset akan dibagi menjadi set pelatihan yang terdiri dari 8.000 rumah dan set pengujian yang terdiri dari 2.000 rumah:
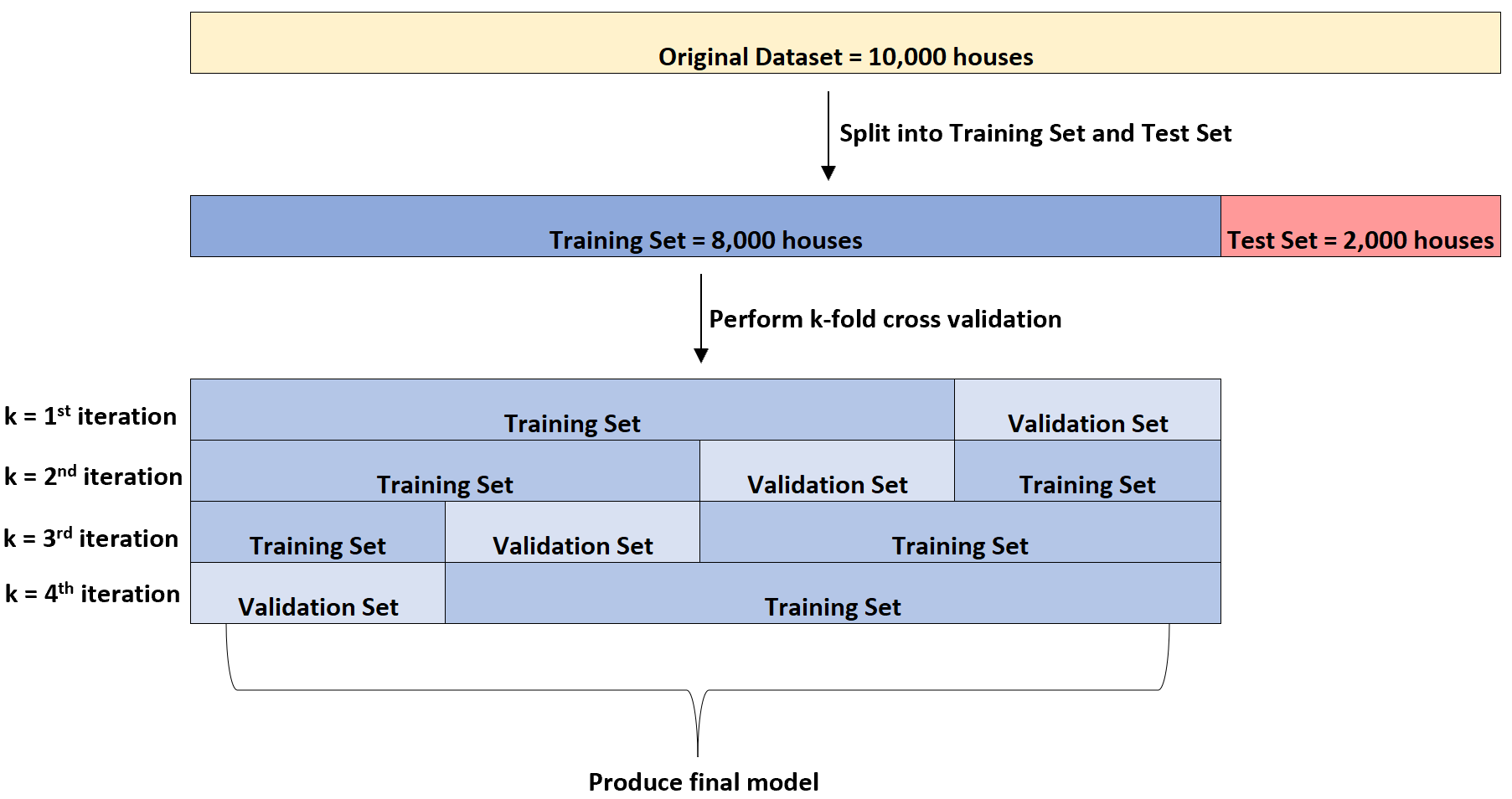
Kemudian model regresi linier berganda akan disesuaikan dengan kumpulan data sebanyak empat kali. Ini akan menggunakan 6.000 rumah untuk set pelatihan dan 2.000 rumah untuk set validasi setiap kali.
Ini disebut validasi k-fold cross.
Set pelatihan digunakan untuk melatih model dan set validasi digunakan untuk mengevaluasi performa model. Ini akan menggunakan kelompok berbeda yang terdiri dari 2.000 rumah setiap kali untuk set validasi.
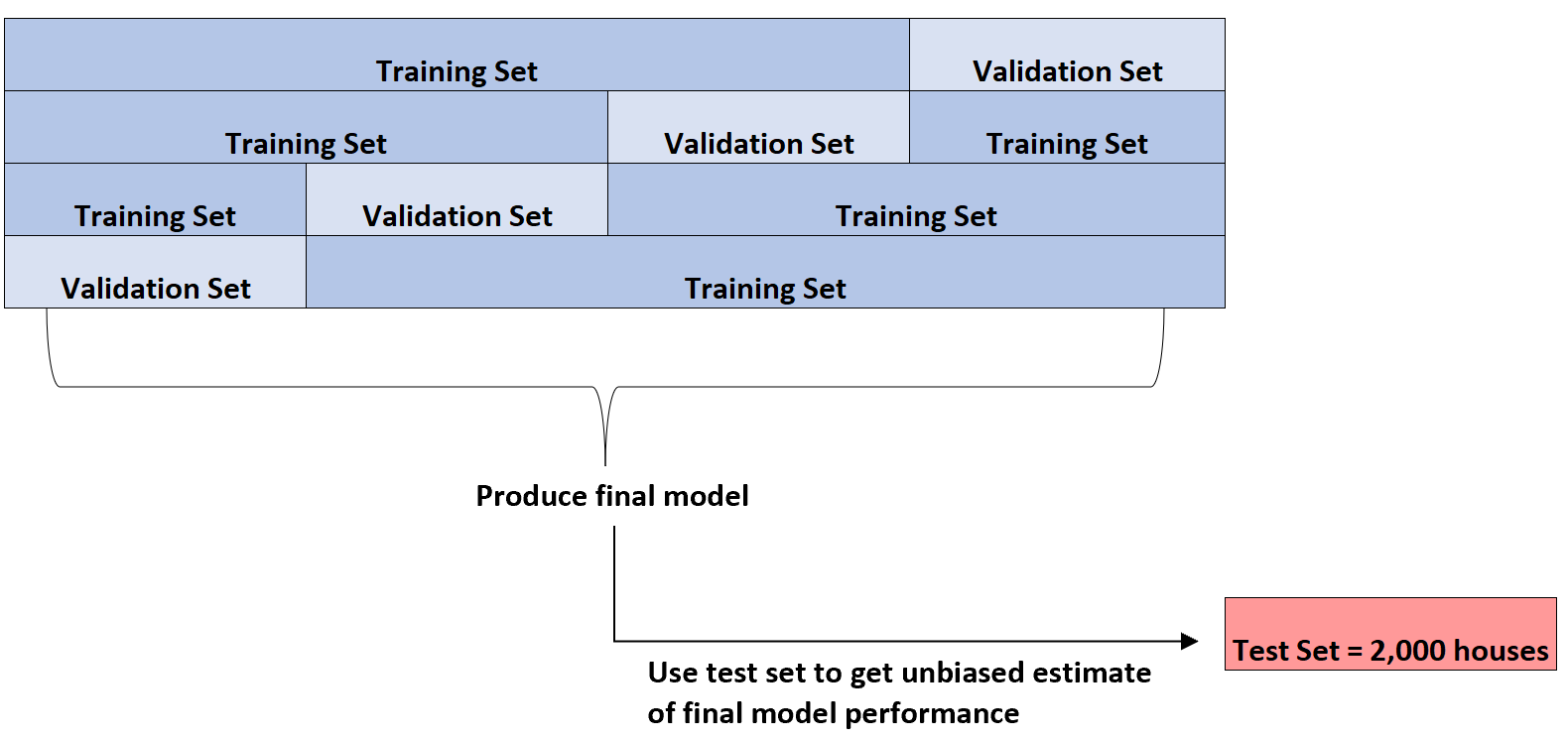
Ia dapat melakukan validasi silang k-fold pada beberapa jenis model regresi yang berbeda untuk mengidentifikasi model yang memiliki kesalahan terendah (yaitu mengidentifikasi model yang paling sesuai dengan kumpulan data).
Hanya setelah mereka mengidentifikasi model terbaik, mereka akan menggunakan set pengujian 2.000 rumah yang disajikan di awal untuk mendapatkan perkiraan kinerja akhir model yang tidak bias.
Misalnya, hal ini dapat mengidentifikasi jenis model regresi tertentu yang rata-rata kesalahan absolutnya adalah 8,345 . Artinya, perbedaan absolut rata-rata antara perkiraan harga rumah dan harga rumah sebenarnya adalah $8,345.
Dia kemudian dapat menyesuaikan model regresi yang tepat ini dengan pengujian terhadap 2.000 rumah yang belum digunakan dan menemukan bahwa rata-rata kesalahan absolut model tersebut adalah 8,847 .
Jadi, estimasi tidak bias dari kesalahan absolut rata-rata sebenarnya dari model adalah $8,847.
Sumber daya tambahan
Panduan Sederhana untuk Validasi Silang K-Fold
Cara melakukan validasi silang K-Fold dengan Python
Cara melakukan validasi silang K-Fold di R
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya