Distribusi pengambilan sampel
Artikel ini menjelaskan apa itu distribusi sampling dalam statistik dan kegunaannya. Jadi, Anda akan menemukan pengertian distribusi sampling, contoh konkrit dari distribusi sampling, dan selain itu juga rumus-rumus jenis distribusi sampling yang paling umum.
Bagaimana distribusi samplingnya?
Distribusi sampling , atau distribusi sampling , adalah distribusi yang dihasilkan dari mempertimbangkan semua kemungkinan sampel dari suatu populasi. Dengan kata lain, distribusi sampling adalah distribusi yang diperoleh dengan menghitung parameter sampling dari seluruh kemungkinan sampel dari suatu populasi.
Misalnya, jika kita mengekstrak semua sampel yang mungkin dari suatu populasi statistik dan menghitung rata-rata setiap sampel, himpunan rata-rata sampel membentuk distribusi pengambilan sampel. Lebih tepatnya, karena parameter yang dihitung adalah mean aritmatika, maka ini adalah distribusi sampling dari mean.
Dalam statistik, distribusi sampling digunakan untuk menghitung probabilitas mendekati nilai parameter populasi ketika mempelajari suatu sampel. Demikian pula, distribusi pengambilan sampel memungkinkan kita memperkirakan kesalahan pengambilan sampel untuk ukuran sampel tertentu.
Contoh Distribusi Sampling
Sekarang setelah kita mengetahui definisi distribusi sampling, mari kita lihat contoh sederhana untuk memahami konsep tersebut sepenuhnya.
- Dalam sebuah kotak kita masukkan tiga bola dan masing-masing bola dituliskan angka satu sampai tiga, sehingga bola yang satu bernomor 1, bola yang lain bernomor 2, dan bola terakhir bernomor 3. Untuk sampel berukuran n = 2, menghitung probabilitas distribusi sampling dari mean jika sampel dengan penggantian dipilih.
Sampel dipilih dengan penggantian, yaitu bola yang diambil untuk memilih elemen pertama sampel dikembalikan ke kotak dan dapat dipilih kembali pada ekstraksi kedua. Oleh karena itu, semua sampel yang mungkin dari populasi adalah:
1.1 1.2 1.3
2.1 2.2 2.3
3.1 3.2 3.3
Jadi, kami menghitung mean aritmatika dari setiap sampel yang mungkin:









Oleh karena itu, peluang diperolehnya setiap nilai mean sampel ketika memilih sampel acak dari populasi adalah sebagai berikut:
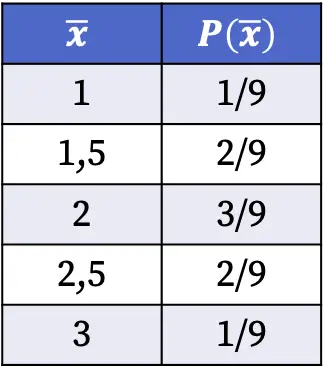
Probabilitas distribusi pengambilan sampel yang ditunjukkan pada tabel di atas dihitung dengan membagi jumlah sampel yang memiliki nilai rata-rata tersebut dengan jumlah total kemungkinan kasus. Misalnya: mean sampel adalah 1,5 dalam dua kasus dari sembilan kemungkinan, oleh karena itu P(1,5)=2/9.
Jenis distribusi pengambilan sampel
Distribusi pengambilan sampel (atau distribusi pengambilan sampel) dapat diklasifikasikan berdasarkan parameter pengambilan sampel dari mana distribusi tersebut diperoleh. Jadi, jenis distribusi yang paling umum adalah sebagai berikut:
- Distribusi rata-rata pengambilan sampel : Ini adalah distribusi pengambilan sampel yang dihasilkan dari penghitungan rata-rata aritmatika setiap sampel.
- Distribusi Proporsi Sampling : Merupakan distribusi sampling yang diperoleh dengan menghitung proporsi seluruh sampel.
- Distribusi varians sampling : Ini adalah distribusi sampling yang membentuk himpunan semua varians dalam sampel.
- Perbedaan distribusi mean sampling : adalah distribusi sampling yang dihasilkan dari penghitungan selisih mean seluruh sampel yang mungkin dari dua populasi yang berbeda.
- Perbedaan Distribusi Proporsi Sampling : adalah distribusi sampling yang diperoleh dengan mengurangkan semua kemungkinan proporsi sampling dari dua populasi.
Setiap jenis distribusi sampling dijelaskan lebih rinci di bawah ini.
Distribusi pengambilan sampel mean
Diberikan populasi yang mengikuti distribusi probabilitas normal dengan mean

dan deviasi standar

dan ukuran sampel diekstraksi

, distribusi sampling mean juga akan ditentukan oleh distribusi normal yang memiliki ciri-ciri sebagai berikut:
![\begin{array}{c}\mu_{\overline{x}}=\mu \qquad \sigma_{\overline{x}}=\cfrac{\sigma}{\sqrt{n}}\\[4ex]\displaystyle N_{\overline{x}}\left(\mu, \frac{\sigma}{\sqrt{n}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-44571aa7337b095ab9c9fa1f746e93a5_l3.png "Rendered by QuickLaTeX.com")
Emas

adalah mean dari distribusi sampling dari mean dan

adalah deviasi standarnya. Lebih-lebih lagi,

adalah kesalahan standar distribusi sampling.
Catatan: Jika populasi tidak mengikuti distribusi normal tetapi ukuran sampelnya besar (n>30), distribusi sampling dari mean juga dapat didekati dengan distribusi normal di atas dengan batas teorema pusat.
Oleh karena itu, karena distribusi sampling dari mean mengikuti distribusi normal, rumus untuk menghitung probabilitas apa pun yang terkait dengan mean sampel adalah:

Emas:
-

adalah sarana sampel.
-
Ini adalah rata-rata populasi.
-

adalah simpangan baku populasi.
-
adalah ukuran sampel.
-

adalah variabel yang ditentukan oleh distribusi normal standar N(0,1).
Distribusi proporsi sampel
Faktanya, ketika kami mempelajari suatu proporsi sampel, kami menganalisis kasus-kasus keberhasilan. Oleh karena itu, variabel acak dalam penelitian mengikuti distribusi probabilitas binomial.
Menurut teorema limit pusat, untuk ukuran besar (n>30) kita dapat mendekatkan distribusi binomial ke distribusi normal. Oleh karena itu, distribusi sampling proporsinya mendekati distribusi normal dengan parameter berikut:
![\begin{array}{c}\displaystyle\mu_{p}=p \qquad \sigma_{p}=\sqrt{\frac{pq}{n}}\\[4ex]\displaystyle N_{p}\left(p, \sqrt{\frac{pq}{n}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-f3408076893f390bb65baecfe38e6eff_l3.png "Rendered by QuickLaTeX.com")
Emas

adalah kemungkinan sukses dan

adalah kemungkinan kegagalan

.
Catatan: Distribusi binomial hanya dapat didekati dengan distribusi normal jika


Dan

.
Oleh karena itu, karena distribusi sampling dari suatu proporsi dapat didekati dengan distribusi normal, maka rumus untuk menghitung probabilitas apa pun yang berkaitan dengan proporsi suatu sampel adalah:

Emas:
-

adalah proporsi sampel.
-
adalah proporsi penduduk.
-
adalah probabilitas kegagalan populasi,
.
-
adalah ukuran sampel.
-
adalah variabel yang ditentukan oleh distribusi normal standar N(0,1).
Distribusi Varians Pengambilan Sampel
Distribusi varians pengambilan sampel ditentukan oleh distribusi probabilitas chi-kuadrat. Oleh karena itu, rumus statistik distribusi varians sampling adalah:

Emas:
-

adalah statistik dari distribusi varians sampling, yang mengikuti distribusi chi-kuadrat.
-
adalah ukuran sampel.
-

adalah varians sampel.
-

adalah varians populasi.
Distribusi pengambilan sampel perbedaan rata-rata
Jika ukuran sampel cukup besar (n 1 ≥30 dan n 2 ≥30), distribusi sampling dari perbedaan rata-rata mengikuti distribusi normal. Lebih tepatnya parameter distribusi tersebut dihitung sebagai berikut:
![\begin{array}{c}\displaystyle \mu_{\overline{x_1}-\overline{x_2}}=\mu_1-\mu_2 \qquad \sigma_{\overline{x_1}-\overline{x_2}}=\sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\\[6ex]\displaystyle N_{\overline{x_1}-\overline{x_2}}\left(\mu_1-\mu_2, \sqrt{\frac{\sigma_1^2}{n_1}+\frac{\sigma_2^2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-90c67b74b4e9326b7869d641a59725d9_l3.png "Rendered by QuickLaTeX.com")
Catatan: Jika kedua populasi berdistribusi normal, maka distribusi sampling dari selisih rata-rata mengikuti distribusi normal tanpa memandang ukuran sampel.
Oleh karena itu, karena distribusi sampling selisih mean ditentukan oleh distribusi normal, maka rumus untuk menghitung statistik distribusi sampling selisih mean adalah:

Emas:
-

adalah rata-rata sampel i.
-

adalah rata-rata populasi i.
-

adalah simpangan baku populasi i.
-

adalah ukuran sampel i.
-
adalah variabel yang ditentukan oleh distribusi normal standar N(0,1).
Perhatikan bahwa sampel dari populasi yang berbeda mungkin memiliki ukuran sampel yang berbeda.
Distribusi sampling perbedaan proporsi
Sampel yang dipilih berdasarkan perbedaan proporsi distribusi pengambilan sampel ditentukan oleh distribusi binomial, karena untuk tujuan praktis proporsi adalah rasio kasus yang berhasil terhadap jumlah total observasi.
Namun, karena teorema limit pusat, distribusi binomial dapat didekati dengan distribusi probabilitas normal. Oleh karena itu, distribusi sampling selisih proporsinya dapat didekati dengan distribusi normal dengan ciri-ciri sebagai berikut:
![\begin{array}{c}\displaystyle\mu_{\widehat{p_1}-\widehat{p_2}}=p_1-p_2 \qquad \sigma_{\widehat{p_1}-\widehat{p_2}}=\sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\\[6ex]\displaystyle N_{p}\left(p_1-p_2, \sqrt{\frac{p_1q_1}{n_1}+\frac{p_2q_2}{n_2}}\right) \end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-a1ce359b5dd6d80f8d27b0b9a1034bed_l3.png "Rendered by QuickLaTeX.com")
Catatan: Distribusi sampling dari perbedaan proporsi hanya dapat didekati dengan distribusi normal jika

,

,

,

,

Dan

.
Oleh karena itu, karena distribusi sampling selisih proporsi dapat didekati dengan distribusi normal, maka rumus menghitung statistik distribusi sampling selisih proporsi adalah sebagai berikut:

Emas:
-

adalah proporsi sampel i.
-

adalah proporsi penduduk i.
-

adalah probabilitas kegagalan populasi i,

.
-
adalah ukuran sampel i.
-
adalah variabel yang ditentukan oleh distribusi normal standar N(0,1).
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya