Uji kesesuaian
Artikel ini menjelaskan apa itu tes goodness-of-fit dan kegunaannya dalam statistik. Ini juga menunjukkan cara melakukan tes kesesuaian dan, sebagai tambahan, Anda akan dapat melihat latihan diselesaikan langkah demi langkah.
Apa itu tes kecocokan?
Uji goodness-of-fit adalah uji statistik yang memungkinkan kita menentukan cocok atau tidaknya suatu sampel data dengan distribusi probabilitas tertentu. Dengan kata lain uji kecukupan digunakan untuk memeriksa apakah data yang diamati sesuai dengan data yang diharapkan.
Seringkali kita mencoba membuat prediksi tentang suatu fenomena dan, sebagai hasilnya, kita mendapatkan nilai-nilai yang diharapkan dari fenomena tersebut yang kita yakini akan terjadi. Namun, kami kemudian harus mengumpulkan data dan memeriksa apakah data yang dikumpulkan sesuai dengan harapan kami. Oleh karena itu, uji kecukupan memungkinkan kita untuk memutuskan dengan menggunakan kriteria statistik apakah data yang diharapkan dan data yang diamati serupa atau tidak.
Dengan demikian uji goodness-of-fit merupakan uji hipotesis yang hipotesis nolnya adalah nilai yang diamati sama dengan nilai yang diharapkan, sebaliknya pengujian hipotesis alternatif menunjukkan bahwa nilai yang diamati berbeda secara statistik. dari nilai yang diharapkan.
![\begin{cases}H_0: f(x)=f_o(x)\\[2ex]H_1: f(x)\neq f_o(x)\end{cases}](https://statorials.org/wp-content/ql-cache/quicklatex.com-db79847cd8097a2baca298bf82594f4f_l3.png "Rendered by QuickLaTeX.com")
Dalam statistika, uji goodness-of-fit disebut juga uji chi-kuadrat , karena distribusi acuan pengujiannya adalah distribusi chi-kuadrat.
Rumus Uji Kesesuaian
Statistik uji goodness-of-fit sama dengan jumlah kuadrat selisih antara nilai yang diamati dan nilai yang diharapkan dibagi dengan nilai yang diharapkan.
Jadi rumus uji kecukupannya adalah sebagai berikut:

Emas:
-

adalah statistik uji kesesuaian, yang mengikuti distribusi chi-kuadrat dengan

derajat kebebasan.
-

adalah ukuran sampel data.
-

adalah nilai observasi untuk data i.
-

adalah nilai yang diharapkan untuk data i.
Jadi, mengingat tingkat signifikansinya

, statistik uji yang dihitung harus dibandingkan dengan nilai uji kritis untuk menentukan apakah akan menolak hipotesis nol atau hipotesis alternatif dari uji hipotesis:
- Jika statistik uji kurang dari nilai kritis

, hipotesis alternatif ditolak (dan hipotesis nol diterima).
- Jika statistik uji lebih besar dari nilai kritis
, hipotesis nol ditolak (dan hipotesis alternatif diterima).
![\begin{array}{l}\text{Si } \chi^2<\chi^2_{1-\alpha|k-1}\text{ se rechaza } H_1\\[3ex]\text{Si } \chi^2>\chi^2_{1-\alpha|k-1}\text{ se rechaza } H_0\end{array}” title=”Rendered by QuickLaTeX.com” height=”70″ width=”243″ style=”vertical-align: 0px;”></p>
</p>
<h2 class=](https://statorials.org/wp-content/ql-cache/quicklatex.com-6b48f7bb620dca865b7e652e81cc247a_l3.png) Bagaimana melakukan tes kecocokan
Bagaimana melakukan tes kecocokan
Untuk melakukan uji kesesuaian, langkah-langkah berikut harus diikuti:
- Kami pertama-tama menetapkan hipotesis nol dan hipotesis alternatif dari uji goodness-of-fit.
- Kedua, kita memilih tingkat keyakinan , dan juga tingkat signifikansi , dari uji kesesuaian.
- Selanjutnya, kita menghitung statistik uji kesesuaian, yang rumusnya dapat ditemukan pada bagian di atas.
- Kami menemukan nilai kritis uji goodness-of-fit menggunakan tabel distribusi chi-kuadrat.
- Kami membandingkan statistik pengujian dengan nilai kritis:
- Jika statistik uji kurang dari nilai kritis, maka hipotesis alternatif ditolak (dan hipotesis nol diterima).
- Jika statistik uji lebih besar dari nilai kritis, maka hipotesis nol ditolak (dan hipotesis alternatif diterima).
Contoh uji kecukupan
- Seorang pemilik toko mengatakan bahwa 50% dari penjualannya adalah untuk produk A, 35% dari penjualannya untuk produk B, dan 15% dari penjualannya untuk produk C. Namun, unit yang terjual dari setiap produk adalah yang ditunjukkan pada gambar. tabel berikut. Analisis apakah data teoritis pemilik berbeda secara statistik dari data aktual yang dikumpulkan.
| Produk | Penjualan yang diamati (HAI saya ) |
|---|---|
| Produk A | 453 |
| Produk B | 268 |
| Produk C | 79 |
| Total | 800 |
Untuk menentukan apakah nilai yang diamati setara dengan nilai yang diharapkan, kami akan melakukan uji goodness-of-fit. Hipotesis nol dan hipotesis alternatif pengujiannya adalah:
Dalam hal ini, kita akan menggunakan tingkat kepercayaan 95% untuk pengujiannya, sehingga tingkat signifikansinya adalah 5%.

Untuk mencari nilai penjualan yang diharapkan, kita perlu mengalikan persentase penjualan yang diharapkan dari setiap produk dengan jumlah total penjualan yang dilakukan:
![\begin{array}{c}E_A=800\cdot 0,50=400\\[2ex]E_B=800\cdot 0,35=280\\[2ex]E_A=800\cdot 0,15=120\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-9daef735efca126bba60ccde38423d7b_l3.png "Rendered by QuickLaTeX.com")
Oleh karena itu, tabel frekuensi permasalahannya adalah sebagai berikut:
| Produk | Penjualan yang diamati (HAI saya ) | Penjualan yang diharapkan (E i ) |
|---|---|---|
| Produk A | 453 | 400 |
| Produk B | 268 | 280 |
| Produk C | 79 | 120 |
| Total | 800 | 800 |
Sekarang kita telah menghitung semua nilai, kita menerapkan rumus uji chi-kuadrat untuk menghitung statistik uji:
![\begin{array}{c}\displaystyle\chi^2=\sum_{i=1}^k\frac{(O_i-E_i)^2}{E_i}\\[6ex]\chi^2=\cfrac{(453-400)^2}{400}+\cfrac{(268-280)^2}{280}+\cfrac{(79-120)^2}{120}\\[6ex]\chi^2=7,02+0,51+14,00\\[6ex]\chi^2=21,53\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-8c76621fbe8504217dfe8ac55b2d6e67_l3.png "Rendered by QuickLaTeX.com")
Setelah nilai statistik uji dihitung, kami menggunakan tabel distribusi chi-kuadrat untuk mencari nilai kritis pengujian. Distribusi chi-kuadrat mempunyai

derajat kebebasan dan tingkat signifikansinya
,Belum:
![\begin{array}{c}\chi^2_{1-\alpha|k-1}=\ \color{orange}\bm{?}\color{black}\\[4ex]\chi^2_{0,95|2}=5,991\end{array}](https://statorials.org/wp-content/ql-cache/quicklatex.com-1850e764fc71b1e7b49b0c4d8133ab89_l3.png "Rendered by QuickLaTeX.com")
Dengan demikian statistik uji (21,53) lebih besar dari nilai uji kritis (5,991), sehingga hipotesis nol ditolak dan hipotesis alternatif diterima. Artinya datanya sangat berbeda dan oleh karena itu pemilik toko mengharapkan penjualan yang berbeda dari penjualan sebenarnya.
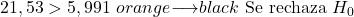
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya