Cara melakukan penskalaan multidimensi di r (dengan contoh)
Dalam statistik, penskalaan multidimensi adalah cara untuk memvisualisasikan kesamaan observasi dalam kumpulan data dalam ruang Cartesian abstrak (biasanya ruang 2D).
Cara termudah untuk melakukan penskalaan multidimensi di R adalah dengan menggunakan fungsi cmdscale() bawaan, yang menggunakan sintaks dasar berikut:
cmdscale(d, eig = SALAH, k = 2, …)
Emas:
- d : Matriks jarak umumnya dihitung dengan fungsi dist() .
- eig : apakah akan mengembalikan nilai eigen atau tidak.
- k : Jumlah dimensi untuk melihat data. Standarnya adalah 2 .
Contoh berikut menunjukkan cara menggunakan fungsi ini dalam praktiknya.
Contoh: Penskalaan Multidimensi di R
Misalkan kita memiliki kerangka data berikut di R yang berisi informasi tentang berbagai pemain bola basket:
#create data frame df <- data. frame (points=c(4, 4, 6, 7, 8, 14, 16, 19, 25, 25, 28), assists=c(3, 2, 2, 5, 4, 8, 7, 6, 8, 10, 11), blocks=c(7, 3, 6, 7, 5, 8, 8, 4, 2, 2, 1), rebounds=c(4, 5, 5, 6, 5, 8, 10, 4, 3, 2, 2)) #add row names row. names (df) <- LETTERS[1:11] #view data frame df points assists blocks rebounds A 4 3 7 4 B 4 2 3 5 C 6 2 6 5 D 7 5 7 6 E 8 4 5 5 F 14 8 8 8 G 16 7 8 10 H 19 6 4 4 I 25 8 2 3 D 25 10 2 2 K 28 11 1 2
Kita dapat menggunakan kode berikut untuk melakukan penskalaan multidimensi dengan fungsi cmdscale() dan memvisualisasikan hasilnya dalam ruang 2D:
#calculate distance matrix
d <- dist(df)
#perform multidimensional scaling
fit <- cmdscale(d, eig= TRUE , k= 2 )
#extract (x, y) coordinates of multidimensional scaling
x <- fit$points[,1]
y <- fit$points[,2]
#create scatterplot
plot(x, y, xlab=" Coordinate 1 ", ylab=" Coordinate 2 ",
main=" Multidimensional Scaling Results ", type=" n ")
#add row names of data frame as labels
text(x, y, labels=row. names (df))
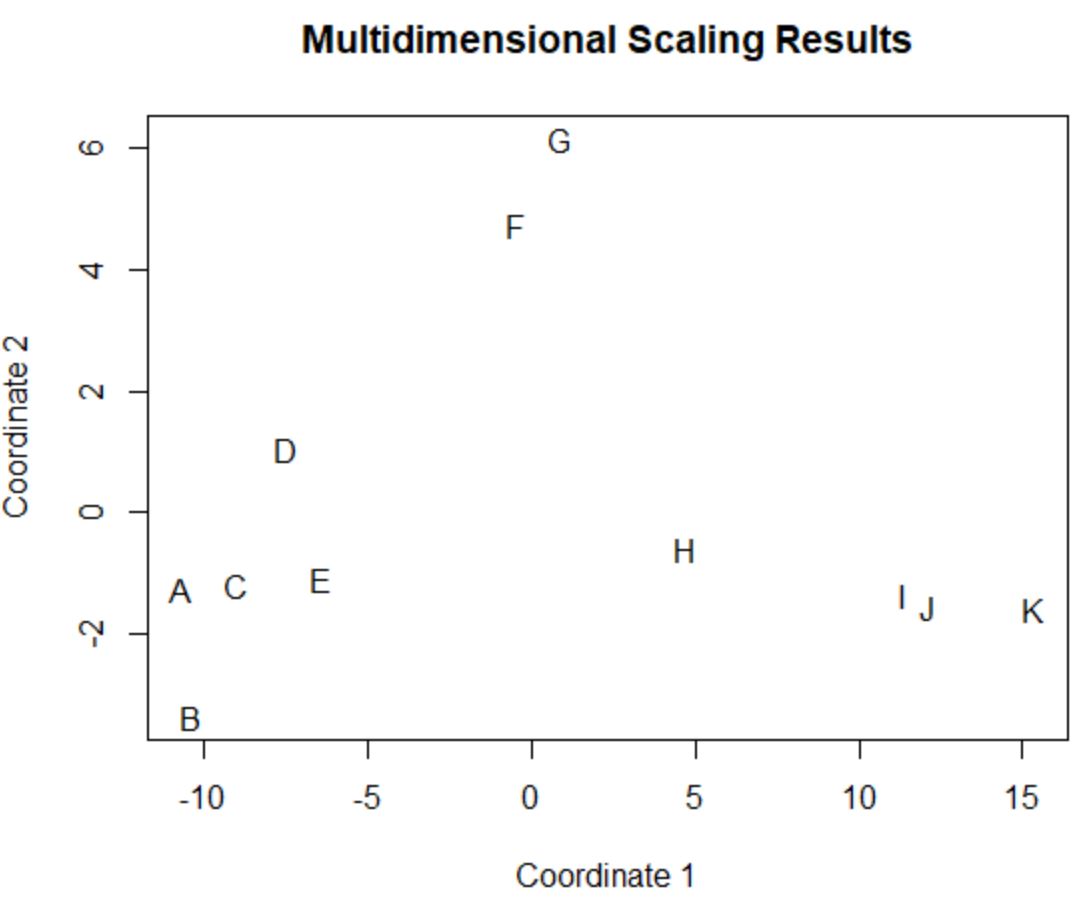
Pemain dalam bingkai data asli yang memiliki nilai serupa di empat kolom asli (poin, assist, blok, dan rebound) berada berdekatan satu sama lain dalam plot.
Misal pemain A dan C saling tertutup. Berikut nilainya dari bingkai data asli:
#view data frame values for players A and C df[rownames(df) %in% c(' A ', ' C '), ] points assists blocks rebounds A 4 3 7 4 C 6 2 6 5
Nilai poin, assist, blok, dan reboundnya sangat mirip, itulah sebabnya keduanya begitu dekat satu sama lain dalam plot 2D.
Sebaliknya, pertimbangkan pemain B dan K yang berjauhan dalam plot.
Jika kita mengacu pada nilainya pada data asli, kita dapat melihat bahwa keduanya sangat berbeda:
#view data frame values for players B and K df[rownames(df) %in% c(' B ', ' K '), ] points assists blocks rebounds B 4 2 3 5 K 28 11 1 2
Jadi plot 2D adalah cara yang baik untuk memvisualisasikan seberapa mirip setiap pemain di semua variabel dalam bingkai data.
Pemain dengan statistik serupa dikelompokkan berdekatan sementara pemain dengan statistik sangat berbeda ditempatkan lebih jauh satu sama lain dalam plot.
Perhatikan bahwa Anda juga dapat mengekstrak koordinat yang tepat (x, y) dari masing-masing pemain dalam plot dengan mengetikkan fit , yang merupakan nama variabel tempat kita menyimpan hasil fungsi cmdscale() :
#view (x, y) coordinates of points in the plot
fit
[,1] [,2]
A -10.6617577 -1.2511291
B -10.3858237 -3.3450473
C -9.0330408 -1.1968116
D -7.4905743 1.0578445
E -6.4021114 -1.0743669
F -0.4618426 4.7392534
G 0.8850934 6.1460850
H 4.7352436 -0.6004609
I 11.3793381 -1.3563398
J 12.0844168 -1.5494108
K 15.3510585 -1.5696166
Sumber daya tambahan
Tutorial berikut menjelaskan cara melakukan tugas umum lainnya di R:
Cara menormalkan data di R
Cara pusat data di R
Cara menghilangkan outlier di R
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya