Cara menggunakan pernyataan proc glmselect di sas
Anda dapat menggunakan pernyataan PROC GLMSELECT di SAS untuk memilih model regresi terbaik berdasarkan daftar variabel prediktor potensial.
Contoh berikut menunjukkan bagaimana menggunakan pernyataan ini dalam praktik.
Contoh: Cara menggunakan PROC GLMSELECT di SAS untuk pemilihan model
Misalkan kita ingin menyesuaikan model regresi linier berganda yang menggunakan (1) jumlah jam yang dihabiskan untuk belajar, (2) jumlah persiapan ujian yang diambil, dan (3) jenis kelamin untuk memprediksi nilai akhir ujian siswa.
Pertama, kita akan menggunakan kode berikut untuk membuat kumpulan data yang berisi informasi ini untuk 20 siswa:
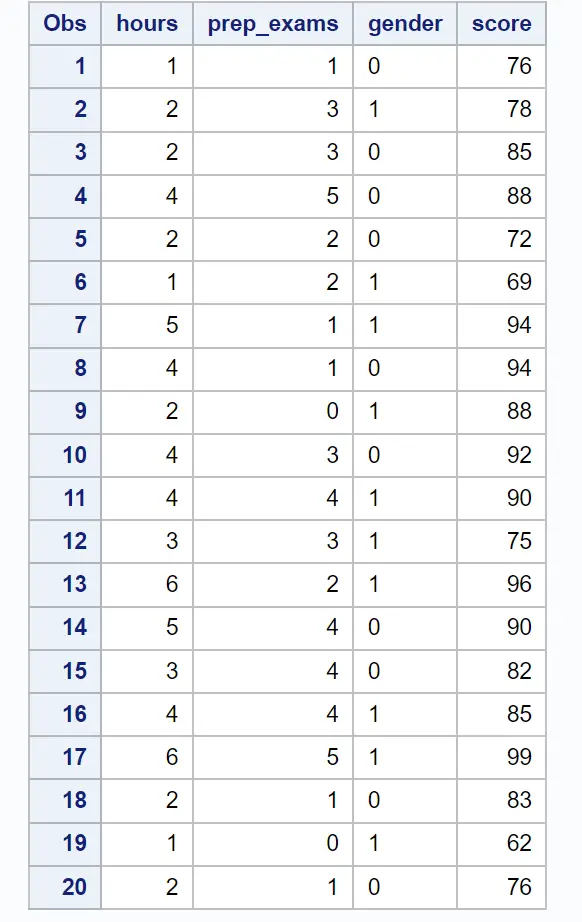
/*create dataset*/ data exam_data; input hours prep_exams gender $score; datalines ; 1 1 0 76 2 3 1 78 2 3 0 85 4 5 0 88 2 2 0 72 1 2 1 69 5 1 1 94 4 1 0 94 2 0 1 88 4 3 0 92 4 4 1 90 3 3 1 75 6 2 1 96 5 4 0 90 3 4 0 82 4 4 1 85 6 5 1 99 2 1 0 83 1 0 1 62 2 1 0 76 ; run ; /*view dataset*/ proc print data =exam_data;
Selanjutnya, kita akan menggunakan pernyataan PROC GLMSELECT untuk mengidentifikasi subset variabel prediktor yang menghasilkan model regresi terbaik:
/*perform model selection*/
proc glmselect data =exam_data;
classgender ;
model score = hours prep_exams gender;
run ;
Catatan : Kami menyertakan gender dalam pernyataan kelas karena merupakan variabel kategori.
Kelompok tabel pertama pada keluaran menunjukkan gambaran umum prosedur GLMSELECT:
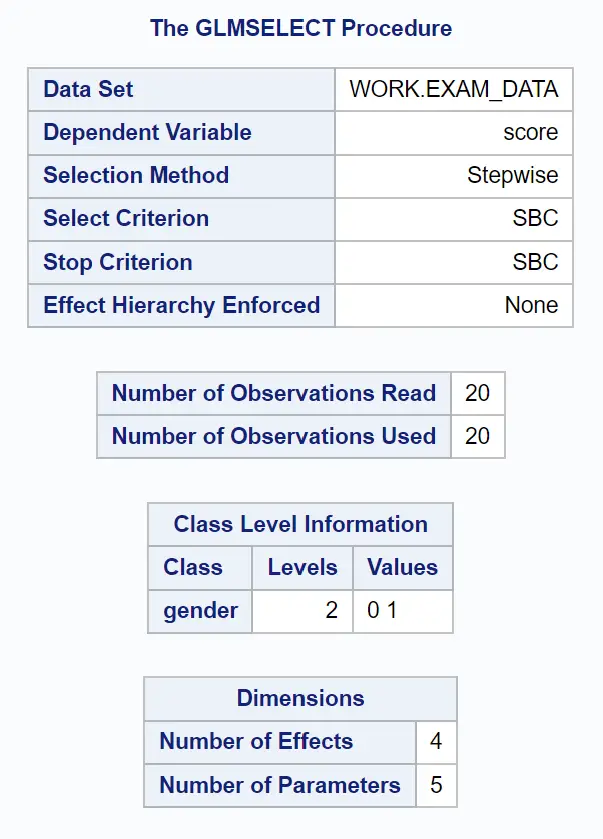
Kita dapat melihat bahwa kriteria yang digunakan untuk menghentikan penambahan atau penghapusan variabel dari model adalah SBC , yang merupakan kriteria informasi Schwarz , kadang-kadang disebut kriteria informasi Bayesian .
Intinya, pernyataan PROC GLMSELECT terus menambahkan atau menghapus variabel dari model hingga menemukan model dengan nilai SBC terendah, yang dianggap sebagai model “terbaik”.
Kelompok tabel berikut memperlihatkan bagaimana pemilihan langkah demi langkah berakhir:
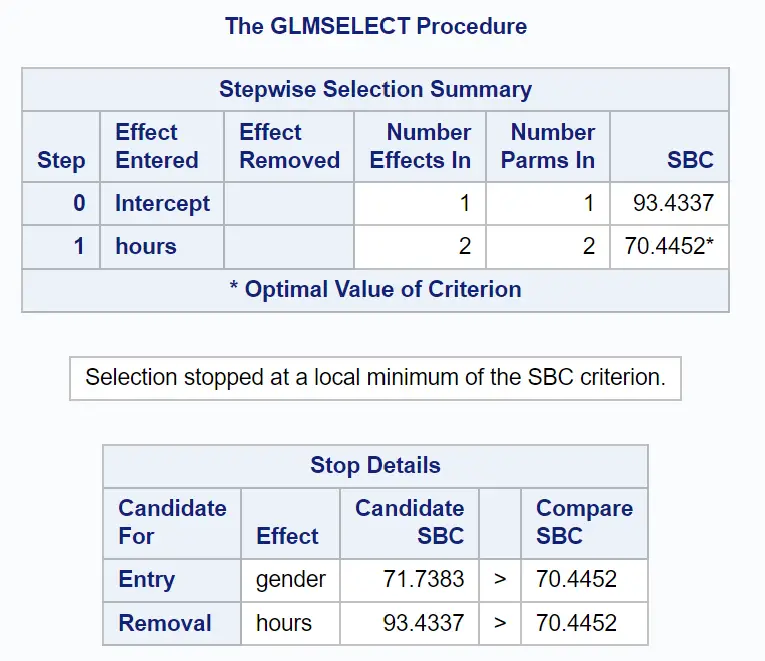
Kita dapat melihat bahwa model yang hanya memiliki suku asli memiliki nilai SBC sebesar 93.4337 .
Dengan menambahkan jam sebagai variabel prediktor dalam model, nilai SBC turun menjadi 70.4452 .
Cara terbaik untuk menyempurnakan model adalah dengan menambahkan gender sebagai variabel prediktor, namun hal ini justru meningkatkan nilai SBC menjadi 71,7383.
Dengan demikian, model akhir hanya mencakup suku intersep dan waktu yang dipelajari.
Bagian terakhir dari hasil menunjukkan ringkasan model regresi yang sesuai ini:
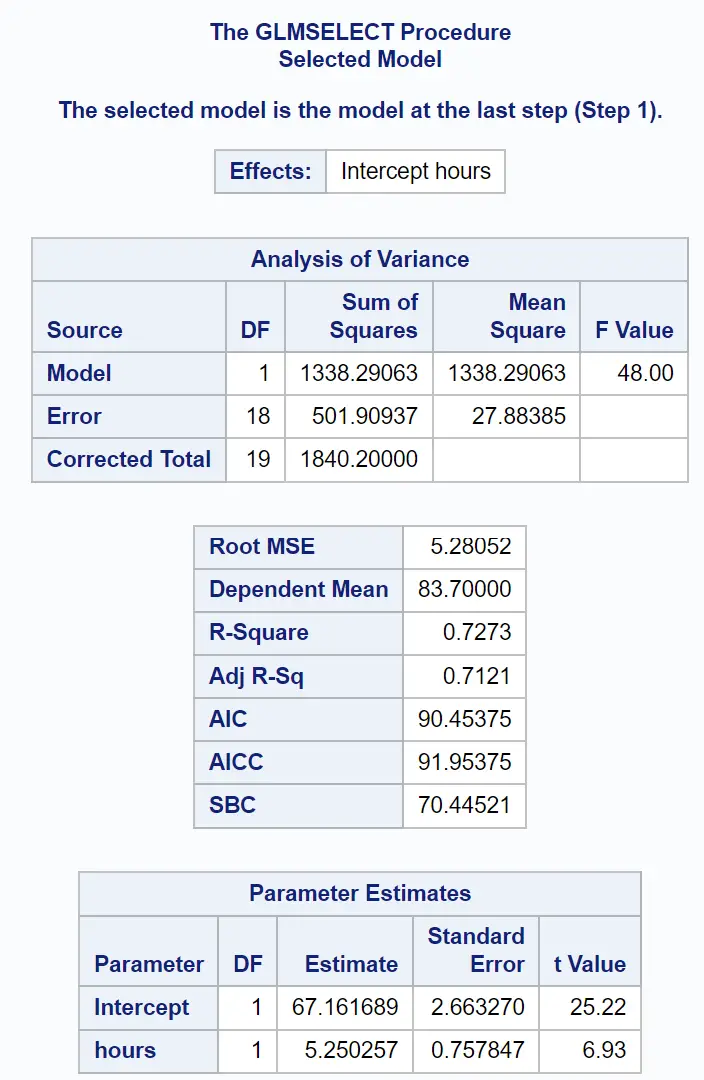
Kita dapat menggunakan nilai dalam tabel Estimasi Parameter untuk menulis model regresi yang sesuai:
Nilai ujian = 67.161689 + 5.250257 (jam belajar)
Kami juga dapat melihat berbagai metrik yang memberi tahu kami seberapa cocok model ini dengan data:
Nilai R-Square menunjukkan persentase variasi nilai ujian yang dapat dijelaskan oleh jumlah jam belajar dan jumlah persiapan ujian yang diambil.
Dalam hal ini, 72,73% variasi nilai ujian dapat dijelaskan oleh jumlah jam belajar dan jumlah persiapan ujian yang diambil.
Nilai Root MSE juga berguna untuk diketahui. Ini mewakili jarak rata-rata antara nilai yang diamati dan garis regresi.
Dalam model regresi ini, nilai yang diamati rata-rata menyimpang sebesar 5,28052 satuan dari garis regresi.
Catatan : Lihat dokumentasi SAS untuk daftar lengkap argumen potensial yang dapat Anda gunakan dengan PROC GLMSELECT .
Sumber daya tambahan
Tutorial berikut menjelaskan cara melakukan tugas umum lainnya di SAS:
Cara melakukan regresi linier sederhana di SAS
Cara melakukan regresi linier berganda di SAS
Cara melakukan regresi polinomial di SAS
Cara melakukan regresi logistik di SAS
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya