Cara menggunakan proc cluster di sas (dengan contoh)
Clustering adalah teknik pembelajaran mesin yang mencoba menemukan kelompok observasi dalam kumpulan data.
Tujuannya adalah untuk menemukan klaster sedemikian rupa sehingga pengamatan dalam setiap klaster cukup mirip satu sama lain, sedangkan observasi dalam klaster yang berbeda sangat berbeda satu sama lain.
Cara termudah untuk melakukan clustering di SAS adalah dengan menggunakan PROC CLUSTER .
Contoh berikut menunjukkan cara menggunakan PROC CLUSTER dalam praktiknya.
Contoh: Cara menggunakan PROC CLUSTER di SAS
Katakanlah kita memiliki kumpulan data berikut yang berisi informasi tentang poin, assist, dan rebound untuk 20 pemain bola basket yang berbeda:
/*create dataset*/
data my_data;
input points assists rebounds;
datalines ;
18 3 15
20 3 14
19 4 14
14 5 10
14 4 8
15 7 14
20 8 13
28 7 9
30 6 5
31 9 4
35 12 11
33 14 6
29 9 5
25 9 5
25 4 3
27 3 8
29 4 12
30 12 7
19 5 6
23 11 5
;
run ;
/*view dataset*/
proc print data =my_data;
Katakanlah kita ingin melakukan pengelompokan untuk mencoba mengidentifikasi “kelompok” pemain dengan statistik serupa satu sama lain.
Kode berikut menunjukkan cara menggunakan PROC CLUSTER di SAS untuk melakukan clustering:
/*perform clustering using points, assists and rebounds variables*/
proc cluster data =my_data method =average;
var points assists rebounds;
run ;
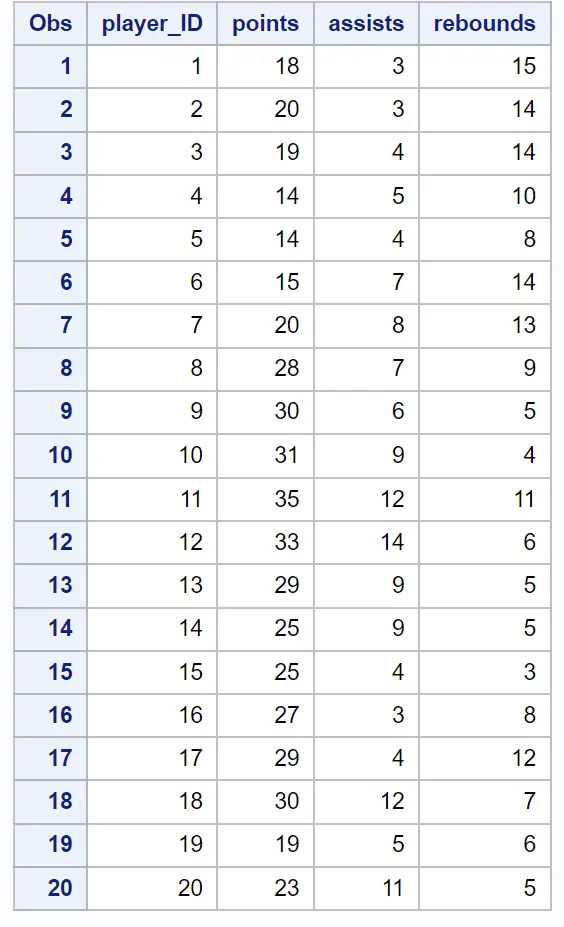
Tabel pertama hasil memberikan informasi tentang bagaimana pengelompokan dilakukan:
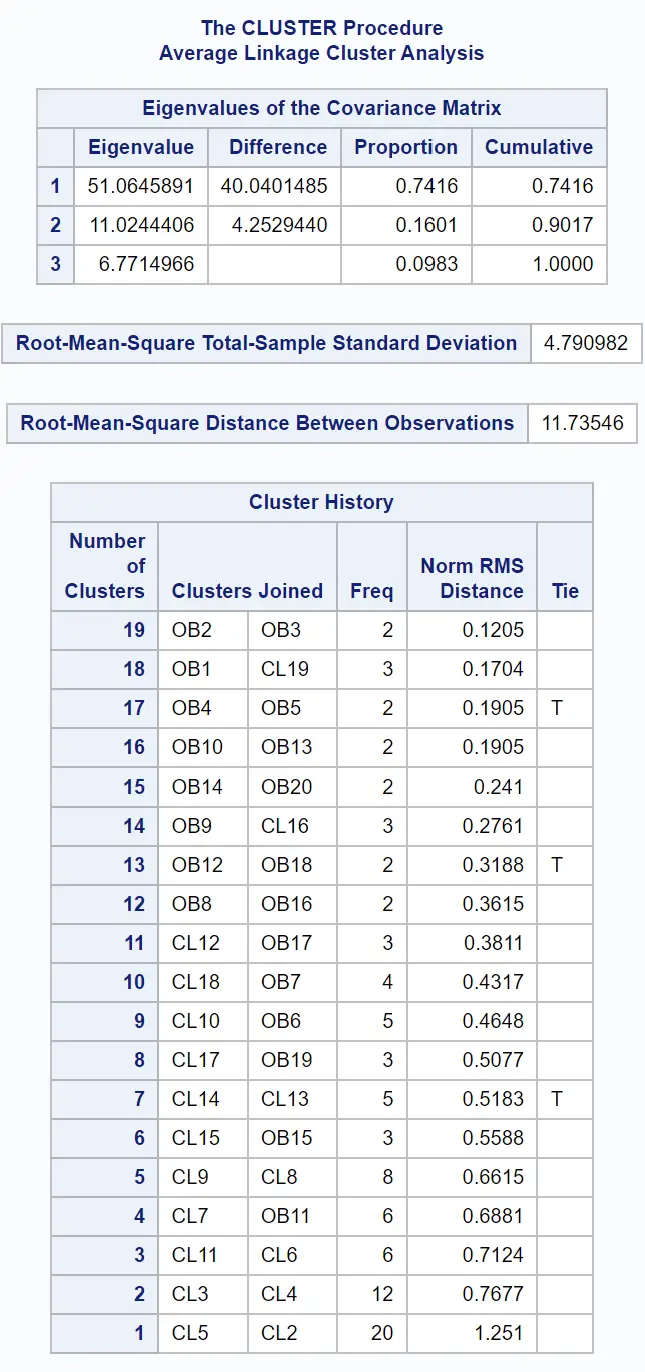
Dendrogram juga dibuat sehingga kita dapat memeriksa secara visual kemiripan antar observasi dalam kumpulan data:
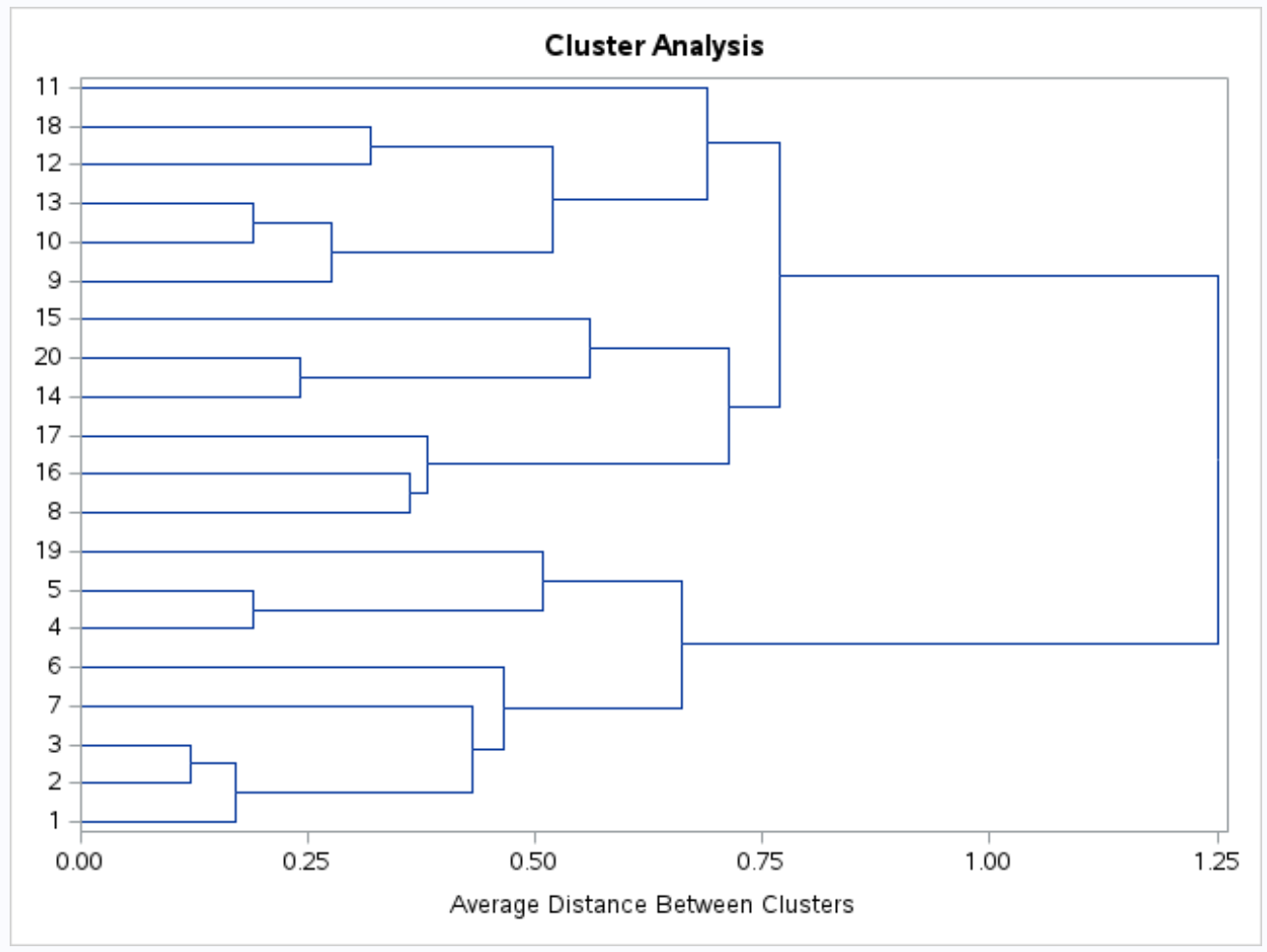
Sumbu y menunjukkan pengamatan individu dan sumbu x menunjukkan jarak rata-rata antar cluster.
Melihat dendrogram ini, tampak bahwa observasi secara alami terbagi dalam tiga kelompok:
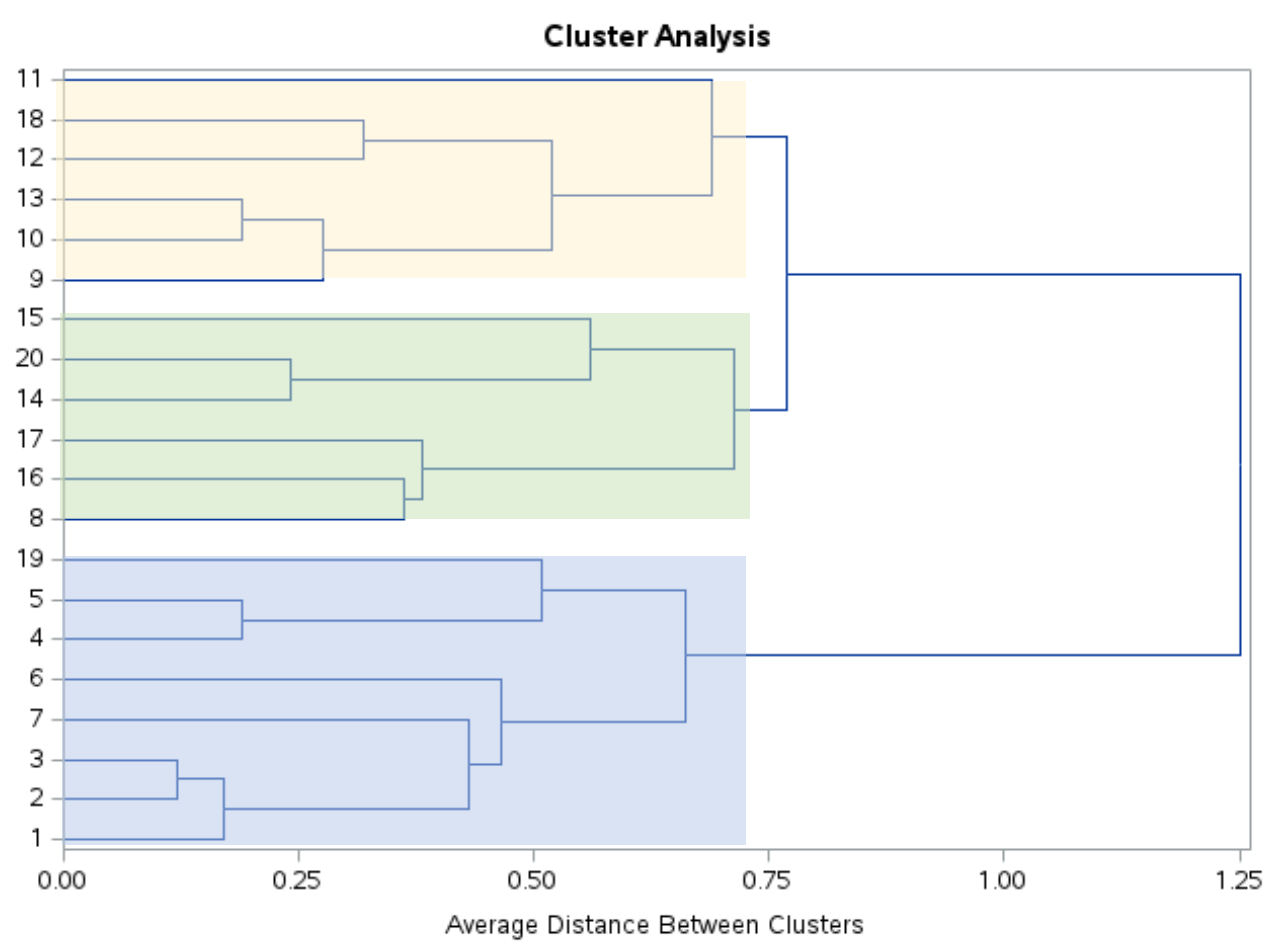
Kita kemudian dapat menggunakan pernyataan PROC TREE dengan ncl=3 untuk memberitahu SAS agar menetapkan setiap observasi dalam kumpulan data asli ke salah satu dari tiga cluster:
/*assign each observation to one of three clusters*/
proc tree data =clustd noprint ncl =3 out =clusts;
copy points assists rebounds;
id player_ID;
run ;
proc sort ;
by cluster;
run ;
/*view cluster assignments*/
proc print data = clusters;
id player_ID;
run ;
Kumpulan data yang dihasilkan menunjukkan setiap observasi asli beserta clusternya:
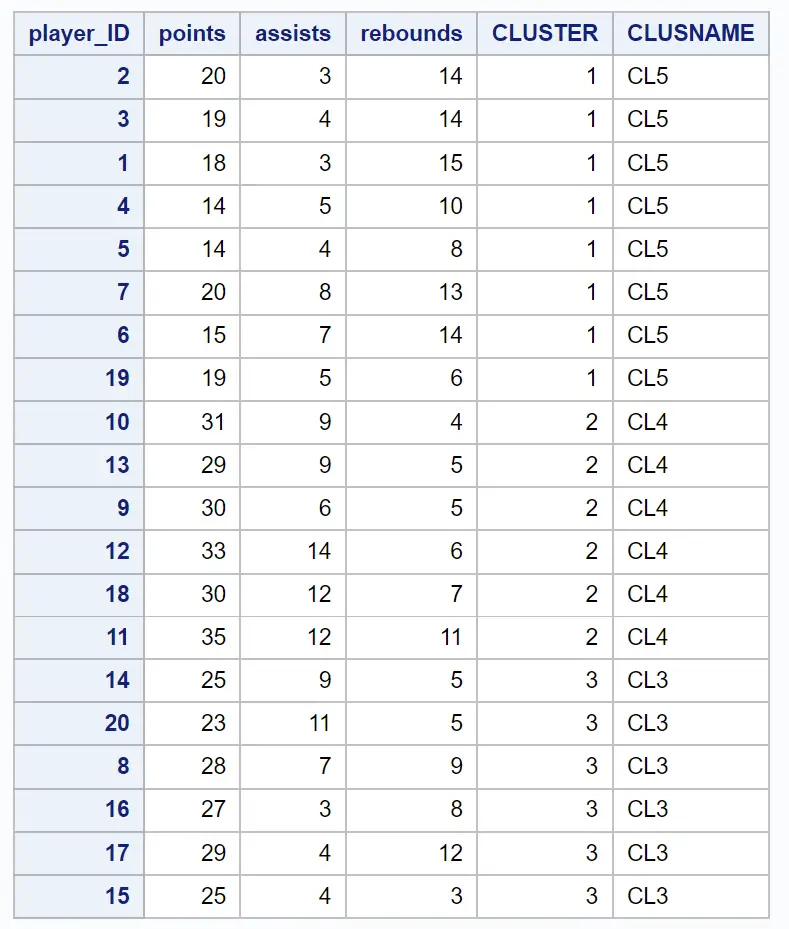
Misalnya, kita dapat melihat: pemain dengan ID 2, 3, 1, 4, 5, 7, 6 dan 19 semuanya termasuk dalam cluster 1 .
Hal ini menunjukkan kepada kita bahwa kedelapan pemain ini “mirip” dalam hal variabel poin, assist, dan rebound.
Catatan : Untuk contoh ini, kami memilih untuk menggunakan rata-rata sebagai metode penghubung untuk pengelompokan. Lihat dokumentasi SAS untuk daftar lengkap metode pengikatan lainnya yang dapat Anda gunakan.
Sumber daya tambahan
Tutorial berikut menjelaskan cara melakukan tugas umum lainnya di SAS:
Bagaimana Melakukan Analisis Komponen Utama di SAS
Cara melakukan regresi linier berganda di SAS
Cara melakukan regresi logistik di SAS
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya