Cara menggunakan kesalahan standar yang kuat dalam regresi di stata
Regresi linier berganda merupakan metode yang dapat kita gunakan untuk memahami hubungan antara beberapa variabel penjelas dan variabel respon.
Sayangnya, permasalahan yang sering terjadi dalam regresi disebut dengan heteroskedastisitas , yaitu terjadi perubahan sistematis pada varians residu pada rentang nilai yang diukur.
Hal ini menyebabkan peningkatan varians estimasi koefisien regresi, namun model regresi tidak memperhitungkan hal ini. Hal ini membuat model regresi lebih mungkin mengklaim bahwa suatu istilah dalam model tersebut signifikan secara statistik, padahal kenyataannya tidak.
Salah satu cara untuk mengatasi masalah ini adalah dengan menggunakan kesalahan standar yang kuat , yang lebih “kuat” terhadap masalah heteroskedastisitas dan cenderung memberikan ukuran yang lebih akurat dari kesalahan standar sebenarnya dari koefisien regresi.
Tutorial ini menjelaskan cara menggunakan kesalahan standar yang kuat dalam analisis regresi di Stata.
Contoh: Kesalahan standar yang kuat di Stata
Kami akan menggunakan kumpulan data Stata yang terintegrasi secara otomatis untuk mengilustrasikan cara menggunakan kesalahan standar yang kuat dalam regresi.
Langkah 1: Muat dan tampilkan data.
Pertama, gunakan perintah berikut untuk memuat data:
penggunaan otomatis sistem
Kemudian tampilkan data mentahnya menggunakan perintah berikut:
saudara
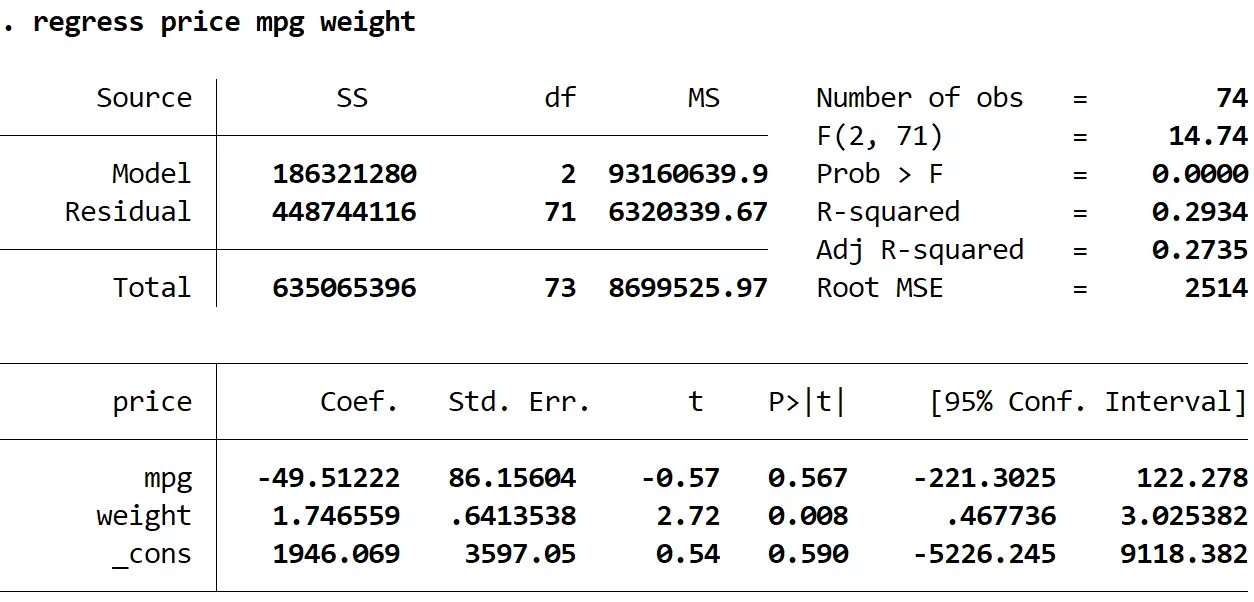
Langkah 2: Lakukan regresi linier berganda tanpa kesalahan standar yang kuat.
Selanjutnya, kita akan memasukkan perintah berikut untuk melakukan regresi linier berganda dengan menggunakan harga sebagai variabel respon dan mpg dan bobot sebagai variabel penjelas:
regresi harga mpg berat
Langkah 3: Lakukan regresi linier berganda menggunakan kesalahan standar yang kuat.
Sekarang kita akan melakukan regresi linier berganda yang sama, namun kali ini kita akan menggunakan perintah vce(robust) sehingga Stata mengetahui cara menggunakan kesalahan standar yang kuat:
harga regresi mpg berat, vce (kuat)
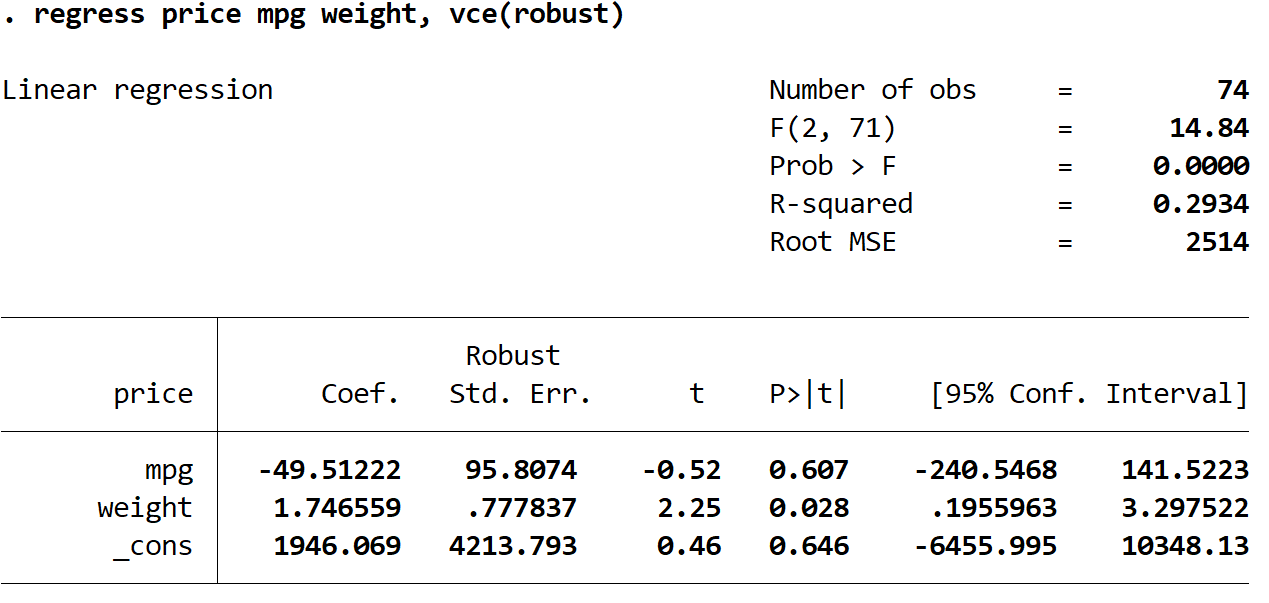
Ada beberapa hal menarik yang perlu diperhatikan di sini:
1. Perkiraan koefisiennya tetap sama . Saat kita menggunakan kesalahan standar yang kuat, estimasi koefisien tidak berubah sama sekali. Perhatikan bahwa estimasi koefisien untuk mpg, bobot, dan konstanta adalah sebagai berikut untuk kedua regresi:
- mpg: -49.51222
- berat: 1,746559
- _melawan: 1946.069
2. Kesalahan standar telah berubah . Perhatikan bahwa ketika kami menggunakan kesalahan standar yang kuat, kesalahan standar untuk setiap estimasi koefisien meningkat.
Catatan: Dalam kebanyakan kasus, kesalahan standar yang kuat akan lebih besar daripada kesalahan standar yang normal, namun dalam kasus yang jarang terjadi, ada kemungkinan bahwa kesalahan standar yang kuat sebenarnya akan lebih kecil.
3. Statistik uji setiap koefisien telah berubah. Perhatikan bahwa nilai absolut dari setiap statistik uji , t , mengalami penurunan. Akibatnya, statistik uji dihitung sebagai koefisien estimasi dibagi dengan kesalahan standar. Jadi, semakin besar kesalahan standarnya, semakin kecil nilai absolut statistik uji.
4. Nilai p telah berubah . Perhatikan bahwa nilai p untuk setiap variabel juga meningkat. Hal ini karena statistik pengujian yang lebih kecil dikaitkan dengan nilai p yang lebih besar.
Meskipun nilai p untuk koefisien kami telah berubah, variabel mpg masih tidak signifikan secara statistik pada α = 0,05 dan variabel bobot masih signifikan secara statistik pada α = 0,05.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya