Analisis diskriminan linier dengan python (langkah demi langkah)
Analisis diskriminan linier adalah metode yang dapat Anda gunakan ketika Anda memiliki sekumpulan variabel prediktor dan ingin mengklasifikasikan variabel respons ke dalam dua kelas atau lebih.
Tutorial ini memberikan contoh langkah demi langkah tentang cara melakukan analisis diskriminan linier dengan Python.
Langkah 1: Muat Perpustakaan yang Diperlukan
Pertama, kita akan memuat fungsi dan perpustakaan yang diperlukan untuk contoh ini:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
Langkah 2: Muat data
Untuk contoh ini, kita akan menggunakan dataset iris dari perpustakaan sklearn. Kode berikut menunjukkan cara memuat kumpulan data ini dan mengonversinya menjadi DataFrame pandas untuk kemudahan penggunaan:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Kita dapat melihat bahwa dataset tersebut berisi total 150 observasi.
Untuk contoh ini, kita akan membangun model analisis diskriminan linier untuk mengklasifikasikan spesies bunga tertentu.
Kami akan menggunakan variabel prediktor berikut dalam model:
- Panjang sepal
- Lebar sepal
- Panjang kelopak
- Lebar kelopak
Dan kita akan menggunakannya untuk memprediksi variabel respon Spesies , yang mendukung tiga kelas potensial berikut:
- setosa
- versikolor
- Virginia
Langkah 3: Sesuaikan model LDA
Selanjutnya, kita akan menyesuaikan model LDA ke data kita menggunakan fungsi LinearDiscriminantAnalsys sklearn:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Langkah 4: Gunakan model untuk membuat prediksi
Setelah kami memasang model menggunakan data kami, kami dapat mengevaluasi performa model menggunakan validasi silang k-fold bertingkat berulang.
Untuk contoh ini, kita akan menggunakan 10 lipatan dan 3 pengulangan:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Kita dapat melihat bahwa model tersebut mencapai akurasi rata-rata sebesar 97,78% .
Kita juga dapat menggunakan model ini untuk memprediksi kelas mana yang dimiliki bunga baru, berdasarkan nilai masukan:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Kita melihat bahwa model tersebut memperkirakan bahwa pengamatan baru ini milik spesies yang disebut setosa .
Langkah 5: Visualisasikan hasilnya
Terakhir, kita dapat membuat plot LDA untuk memvisualisasikan diskriminan linier model dan memvisualisasikan seberapa baik model tersebut memisahkan tiga spesies berbeda dalam kumpulan data kita:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
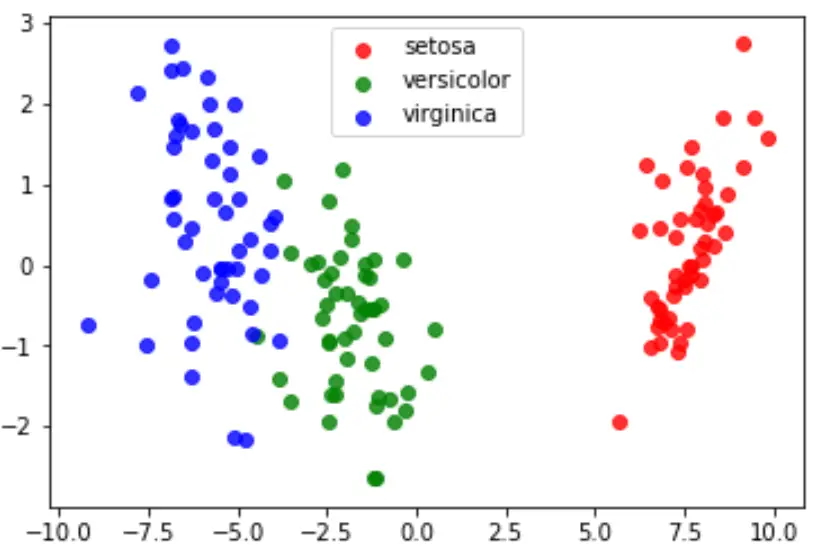
Anda dapat menemukan kode Python lengkap yang digunakan dalam tutorial ini di sini .
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya