Bagaimana menafsirkan kesalahan standar sisa
Kesalahan standar sisa digunakan untuk mengukur seberapa cocok model regresi dengan kumpulan data.
Secara sederhana, ini mengukur deviasi standar residu dalam model regresi.
Ini dihitung sebagai berikut:
Kesalahan standar sisa = √ Σ(y – ŷ) 2 /df
Emas:
- y : Nilai yang diamati
- ŷ : Nilai prediksi
- df: Derajat kebebasan, dihitung sebagai jumlah total observasi – jumlah total parameter model.
Semakin kecil kesalahan standar sisa, semakin baik model regresi cocok dengan kumpulan data. Sebaliknya, semakin tinggi kesalahan standar sisa, semakin buruk kesesuaian model regresi terhadap kumpulan data.
Model regresi yang memiliki kesalahan standar sisa yang kecil akan memiliki titik-titik data yang mengelompok di sekitar garis regresi yang sesuai:
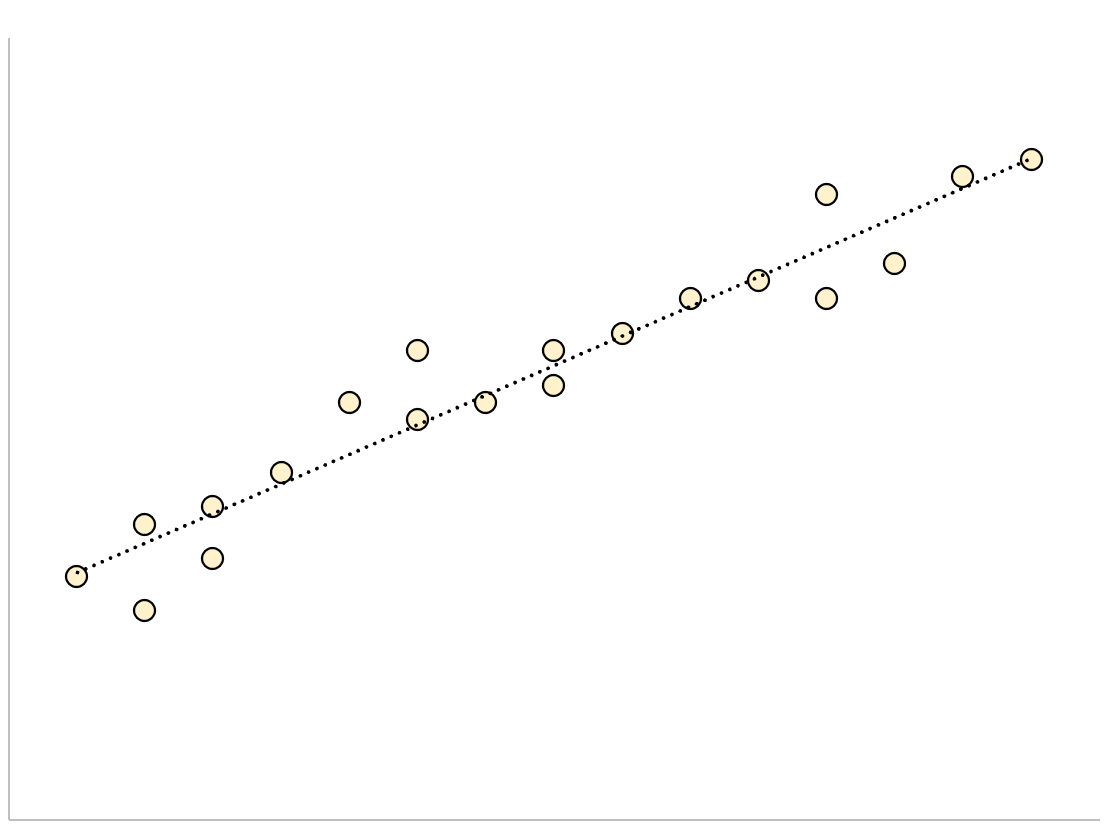
Residual model ini (selisih antara nilai observasi dan nilai prediksi) akan kecil, artinya standar error sisa juga akan kecil.
Sebaliknya, model regresi yang memiliki kesalahan standar sisa yang besar akan memiliki titik-titik data yang tersebar lebih longgar di sekitar garis regresi yang dipasang:
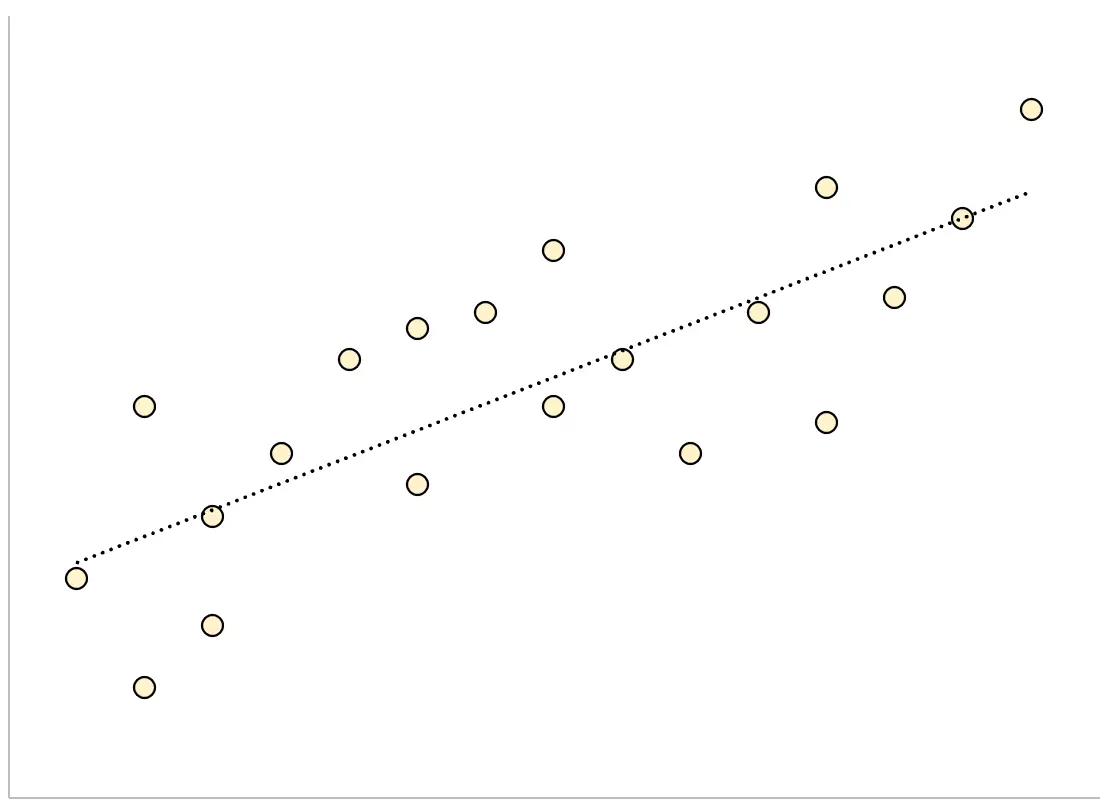
Residual dari model ini akan semakin besar yang berarti sisa standar errornya juga akan semakin besar.
Contoh berikut menunjukkan cara menghitung dan menafsirkan kesalahan standar sisa model regresi di R.
Contoh: Menafsirkan kesalahan standar sisa
Misalkan kita ingin menyesuaikan model regresi linier berganda berikut:
mpg = β 0 + β 1 (perpindahan) + β 2 (daya)
Model ini menggunakan variabel prediktor “perpindahan” dan “tenaga kuda” untuk memprediksi mil per galon yang ditempuh oleh mobil tertentu.
Kode berikut menunjukkan cara menyesuaikan model regresi ini di R:
#load built-in mtcars dataset data(mtcars) #fit regression model model <- lm(mpg~disp+hp, data=mtcars) #view model summary summary(model) Call: lm(formula = mpg ~ disp + hp, data = mtcars) Residuals: Min 1Q Median 3Q Max -4.7945 -2.3036 -0.8246 1.8582 6.9363 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 30.735904 1.331566 23.083 < 2nd-16 *** available -0.030346 0.007405 -4.098 0.000306 *** hp -0.024840 0.013385 -1.856 0.073679 . --- Significant. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: 3.127 on 29 degrees of freedom Multiple R-squared: 0.7482, Adjusted R-squared: 0.7309 F-statistic: 43.09 on 2 and 29 DF, p-value: 2.062e-09
Di bagian bawah hasil, kita dapat melihat bahwa kesalahan standar sisa model ini adalah 3,127 .
Hal ini menunjukkan bahwa model regresi memprediksi mpg mobil dengan kesalahan rata-rata sekitar 3,127.
Menggunakan kesalahan standar sisa untuk membandingkan model
Kesalahan standar sisa sangat berguna untuk membandingkan kesesuaian model regresi yang berbeda.
Misalnya, kita memasangkan dua model regresi berbeda untuk memprediksi mpg mobil. Kesalahan standar sisa masing-masing model adalah sebagai berikut:
- Kesalahan standar sisa model 1: 3.127
- Kesalahan standar sisa model 2: 5.657
Karena Model 1 memiliki kesalahan standar sisa yang lebih rendah, model ini lebih cocok dengan data dibandingkan Model 2. Oleh karena itu, kami lebih memilih menggunakan Model 1 untuk memprediksi mpg mobil, karena prediksi yang dibuatnya lebih dekat dengan nilai mpg mobil yang diamati.
Sumber daya tambahan
Cara melakukan regresi linier sederhana di R
Cara melakukan regresi linier berganda di R
Cara membuat plot sisa di R
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya