Cara membuat hutan acak di r (langkah demi langkah)
Ketika hubungan antara sekumpulan variabel prediktor dan variabel respon sangat kompleks, kita sering menggunakan metode nonlinier untuk memodelkan hubungan di antara keduanya.
Salah satu metode tersebut adalah dengan membangun pohon keputusan . Namun, kelemahan dari penggunaan pohon keputusan tunggal adalah bahwa pohon tersebut cenderung memiliki varians yang tinggi .
Artinya, jika kita membagi kumpulan data menjadi dua bagian dan menerapkan pohon keputusan pada kedua bagian tersebut, hasilnya bisa sangat berbeda.
Salah satu metode yang dapat kita gunakan untuk mengurangi varians dari satu pohon keputusan adalah dengan membangun model hutan acak , yang cara kerjanya sebagai berikut:
1. Ambil b sampel bootstrap dari kumpulan data asli.
2. Buat pohon keputusan untuk setiap sampel bootstrap.
- Saat membangun pohon, setiap kali pemisahan dipertimbangkan, hanya sampel acak dari m prediktor yang dianggap sebagai kandidat untuk pemisahan dari kumpulan p prediktor lengkap. Umumnya, kita memilih m sama dengan √p .
3. Rata-ratakan prediksi dari setiap pohon untuk mendapatkan model akhir.
Ternyata hutan acak cenderung menghasilkan model yang jauh lebih akurat dibandingkan pohon keputusan tunggal dan bahkan model kantong .
Tutorial ini memberikan contoh langkah demi langkah tentang cara membuat model hutan acak untuk kumpulan data di R.
Langkah 1: Muat paket yang diperlukan
Pertama, kami akan memuat paket yang diperlukan untuk contoh ini. Untuk contoh sederhana ini, kita hanya membutuhkan satu paket:
library (randomForest)
Langkah 2: Sesuaikan Model Hutan Acak
Untuk contoh ini, kami akan menggunakan kumpulan data R bawaan yang disebut Kualitas Udara yang berisi pengukuran kualitas udara di Kota New York selama 153 hari.
#view structure of air quality dataset str(airquality) 'data.frame': 153 obs. of 6 variables: $ Ozone: int 41 36 12 18 NA 28 23 19 8 NA ... $Solar.R: int 190 118 149 313 NA NA 299 99 19 194 ... $ Wind: num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6 ... $ Temp: int 67 72 74 62 56 66 65 59 61 69 ... $Month: int 5 5 5 5 5 5 5 5 5 5 ... $Day: int 1 2 3 4 5 6 7 8 9 10 ... #find number of rows with missing values sum(! complete . cases (airquality)) [1] 42
Kumpulan data ini memiliki 42 baris dengan nilai yang hilang. Oleh karena itu, sebelum memasang model hutan acak, kita akan mengisi nilai yang hilang di setiap kolom dengan median kolom:
#replace NAs with column medians for (i in 1: ncol (air quality)) { airquality[,i][ is . na (airquality[, i])] <- median (airquality[, i], na . rm = TRUE ) }
Terkait: Cara memperhitungkan nilai yang hilang di R
Kode berikut menunjukkan cara menyesuaikan model hutan acak di R menggunakan fungsi randomForest() dari paket randomForest .
#make this example reproducible set.seed(1) #fit the random forest model model <- randomForest( formula = Ozone ~ ., data = airquality ) #display fitted model model Call: randomForest(formula = Ozone ~ ., data = airquality) Type of random forest: regression Number of trees: 500 No. of variables tried at each split: 1 Mean of squared residuals: 327.0914 % Var explained: 61 #find number of trees that produce lowest test MSE which.min(model$mse) [1] 82 #find RMSE of best model sqrt(model$mse[ which . min (model$mse)]) [1] 17.64392
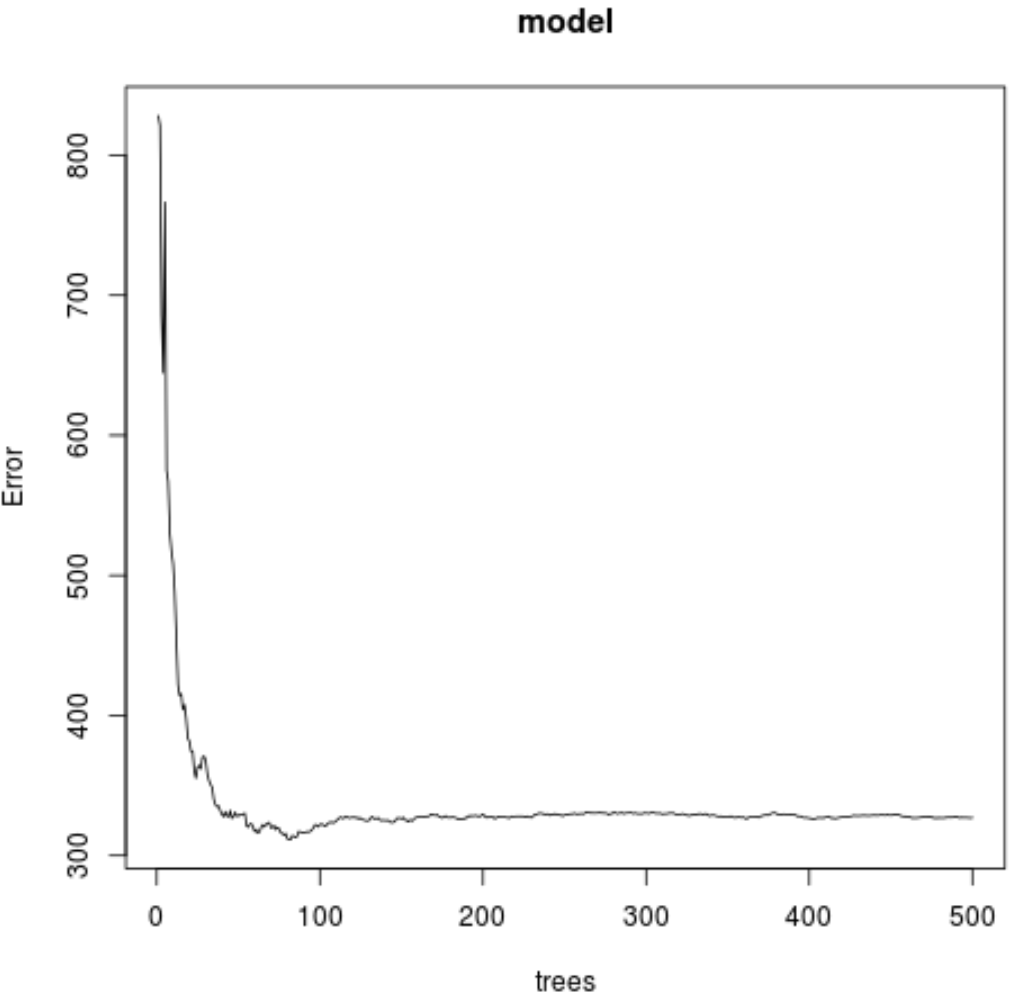
Dari hasil tersebut terlihat bahwa model yang menghasilkan test mean square error (MSE) terendah menggunakan 82 pohon.
Kita juga dapat melihat bahwa root mean square error model ini adalah 17.64392 . Kita dapat menganggap ini sebagai perbedaan rata-rata antara nilai perkiraan ozon dan nilai sebenarnya yang diamati.
Kita juga dapat menggunakan kode berikut untuk menghasilkan plot pengujian MSE berdasarkan jumlah pohon yang digunakan:
#plot the MSE test by number of trees
plot(model)
Dan kita dapat menggunakan fungsi varImpPlot() untuk membuat plot yang menampilkan pentingnya setiap variabel prediktor dalam model akhir:
#produce variable importance plot
varImpPlot(model)
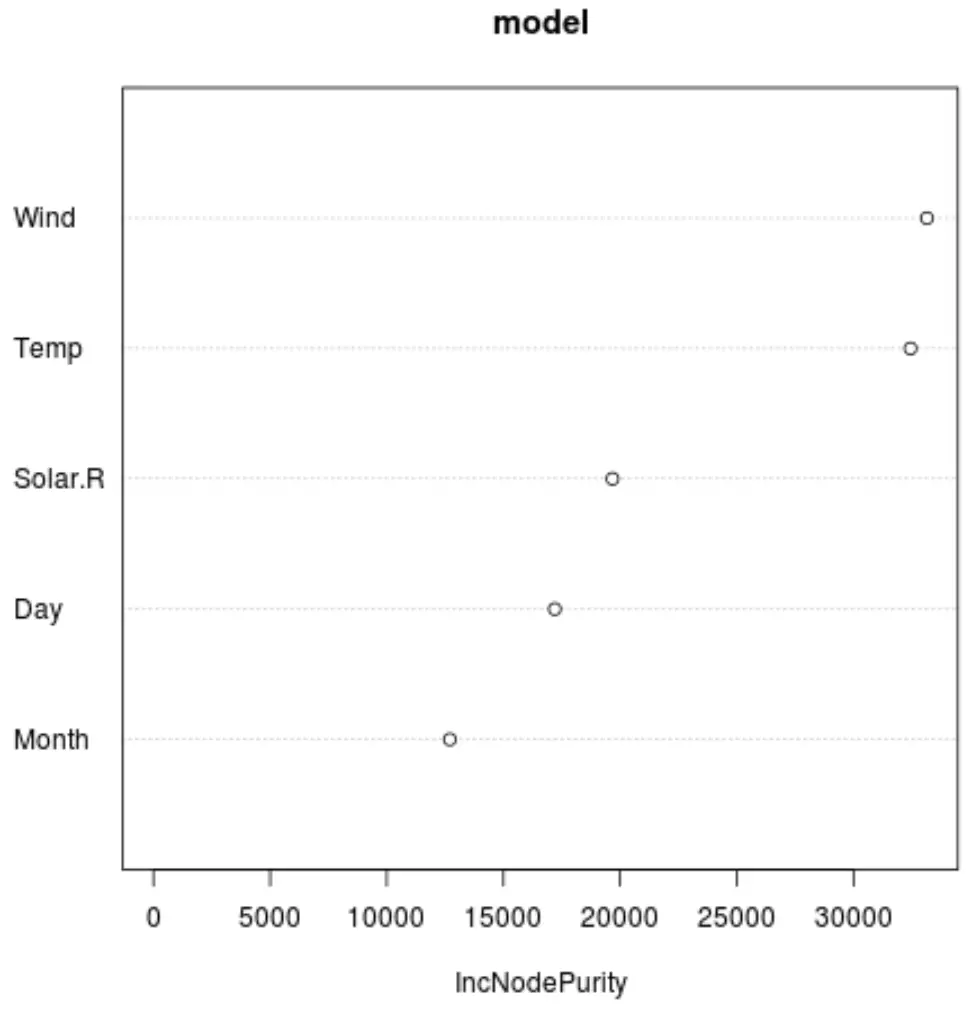
Sumbu x menampilkan peningkatan rata-rata kemurnian simpul pohon regresi sebagai fungsi pemisahan berbagai prediktor yang ditampilkan pada sumbu y.
Dari grafik tersebut terlihat bahwa Angin merupakan variabel prediktor terpenting, diikuti oleh Suhu .
Langkah 3: Sesuaikan modelnya
Secara default, fungsi randomForest() menggunakan 500 pohon dan (total prediktor/3) prediktor yang dipilih secara acak sebagai kandidat potensial untuk setiap pemisahan. Kita dapat menyesuaikan parameter ini menggunakan fungsi tuneRF() .
Kode berikut menunjukkan cara mencari model optimal menggunakan spesifikasi berikut:
- ntreeTry: Jumlah pohon yang akan dibangun.
- mtryStart: jumlah awal variabel prediktor yang harus diperhitungkan di setiap divisi.
- stepFactor: Faktor yang akan ditingkatkan hingga estimasi error out-of-bag berhenti meningkat pada jumlah tertentu.
- perbaikan: jumlah kesalahan keluar kantong yang harus diperbaiki untuk terus meningkatkan faktor langkah.
model_tuned <- tuneRF(
x=airquality[,-1], #define predictor variables
y=airquality$Ozone, #define response variable
ntreeTry= 500 ,
mtryStart= 4 ,
stepFactor= 1.5 ,
improve= 0.01 ,
trace= FALSE #don't show real-time progress
)
Fungsi ini menghasilkan plot berikut, yang menampilkan jumlah prediktor yang digunakan pada setiap pemisahan ketika membangun pohon pada sumbu x dan perkiraan kesalahan yang terjadi pada sumbu y:
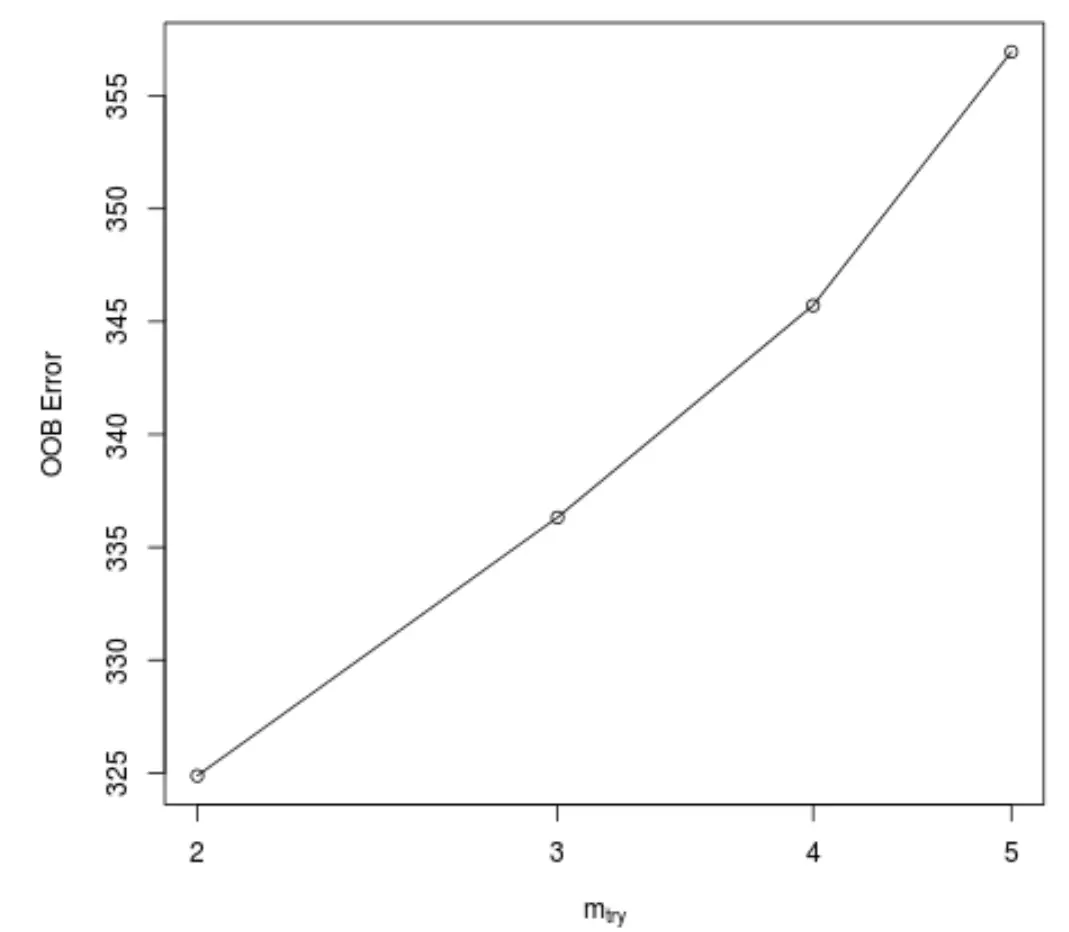
Kita dapat melihat bahwa kesalahan OOB terendah diperoleh dengan menggunakan 2 prediktor yang dipilih secara acak pada setiap pemisahan saat membangun pohon.
Ini sebenarnya sesuai dengan pengaturan default (total prediktor/3 = 6/3 = 2) yang digunakan oleh fungsi randomForest() awal.
Langkah 4: Gunakan model akhir untuk membuat prediksi
Terakhir, kita dapat menggunakan model hutan acak yang disesuaikan untuk membuat prediksi mengenai observasi baru.
#define new observation new <- data.frame(Solar.R=150, Wind=8, Temp=70, Month=5, Day=5) #use fitted bagged model to predict Ozone value of new observation predict(model, newdata=new) 27.19442
Berdasarkan nilai variabel prediktor, model hutan acak yang dipasang memperkirakan nilai ozon pada hari tersebut adalah 27,19442 .
Kode R lengkap yang digunakan dalam contoh ini dapat ditemukan di sini .
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya