Cara membaca papan distribusi f
Tutorial ini menjelaskan cara membaca dan menginterpretasikan tabel distribusi F.
Apa yang dimaksud dengan tabel distribusi F?
Tabel distribusi F merupakan tabel yang menunjukkan nilai kritis dari distribusi F. Untuk menggunakan tabel distribusi F, Anda hanya memerlukan tiga nilai:
- Derajat kebebasan pembilangnya
- Derajat kebebasan penyebutnya
- Tingkat alfa (pilihan umum adalah 0,01, 0,05, dan 0,10)
Tabel berikut menunjukkan tabel distribusi F untuk alpha = 0,10. Angka-angka di bagian atas tabel mewakili derajat kebebasan pembilang (berlabel DF1 dalam tabel) dan angka-angka di sebelah kiri tabel mewakili derajat kebebasan penyebut (berlabel DF2 dalam tabel).
Silakan klik pada tabel untuk memperbesar.
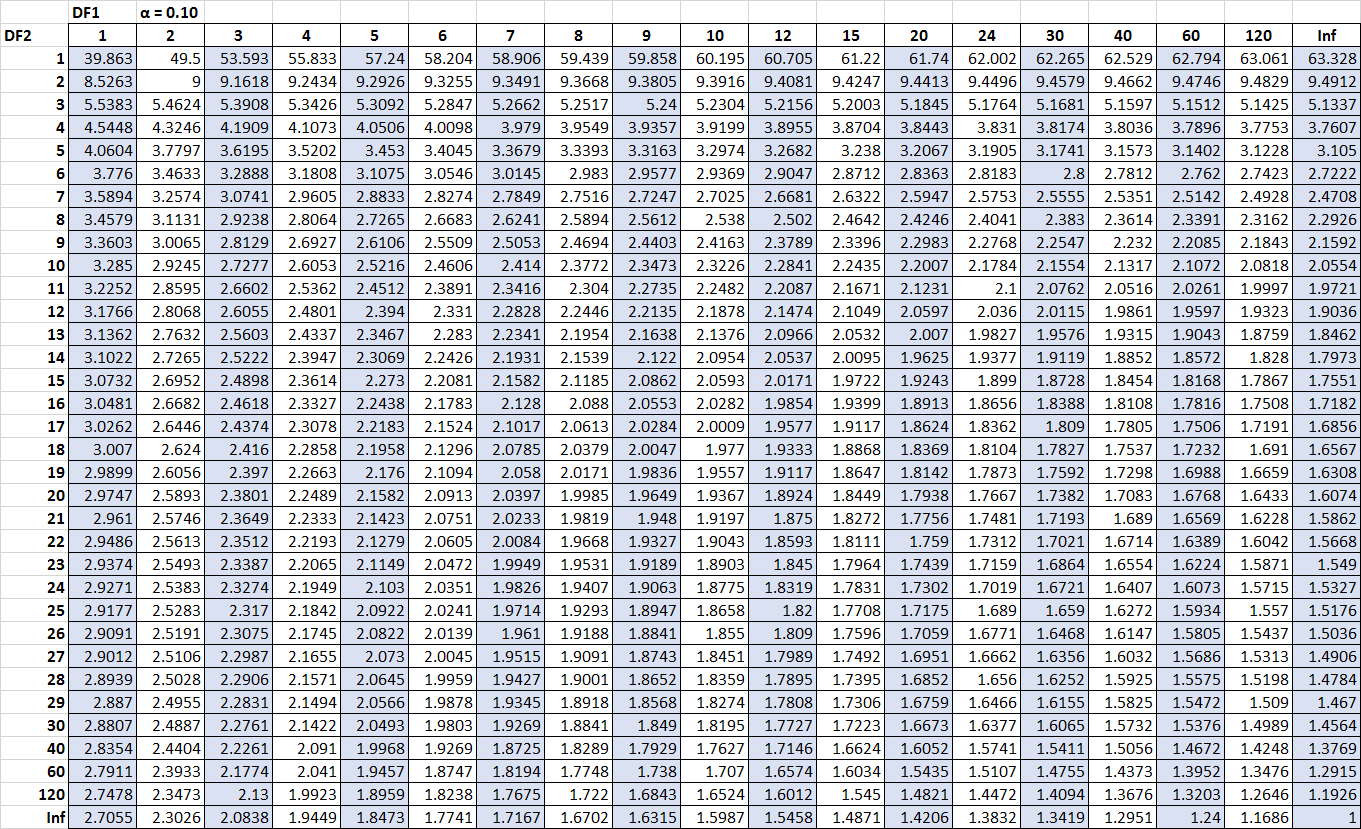
Nilai kritis dalam tabel sering dibandingkan dengan statistik F dari uji F. Jika statistik F lebih besar dari nilai kritis yang terdapat pada tabel, maka Anda dapat menolak hipotesis nol uji F dan menyimpulkan bahwa hasil pengujian tersebut signifikan secara statistik.
Contoh penggunaan tabel distribusi F
Tabel distribusi F digunakan untuk mencari nilai kritis uji F. Tiga skenario paling umum di mana Anda akan melakukan uji F adalah:
- Uji F dalam analisis regresi untuk menguji signifikansi keseluruhan suatu model regresi.
- Uji F dalam ANOVA (analisis varians) untuk menguji perbedaan keseluruhan antara rata-rata kelompok.
- Uji F untuk mengetahui apakah dua populasi mempunyai varian yang sama.
Mari kita lihat contoh penggunaan tabel distribusi F di setiap skenario.
Uji F dalam Analisis Regresi
Misalkan kita melakukan analisis regresi linier berganda dengan menggunakan jam belajar dan ujian persiapan sebagai variabel prediktor dan nilai ujian akhir sebagai variabel respon. Saat kami menjalankan analisis regresi, kami menerima hasil berikut:
| Sumber | SS | df | MS. | F | P. |
|---|---|---|---|---|---|
| Regresi | 546.53 | 2 | 273.26 | 5.09 | 0,033 |
| Sisa | 483.13 | 9 | 53.68 | ||
| Total | 1029.66 | 11 |
Dalam analisis regresi, statistik f dihitung sebagai regresi MS/residual MS. Statistik ini menunjukkan apakah model regresi memberikan kesesuaian yang lebih baik terhadap data dibandingkan model yang tidak memuat variabel independen. Pada dasarnya, ini menguji apakah model regresi secara keseluruhan bermanfaat.
Dalam contoh ini, statistik F adalah 273.26 / 53.68 = 5.09 .
Misalkan kita ingin mengetahui apakah statistik F ini signifikan pada tingkat alpha = 0,05. Menggunakan tabel distribusi F untuk alpha = 0,05, dengan pembilang derajat kebebasan 2 ( df untuk Regresi) dan penyebut derajat kebebasan 9 ( df untuk Residual) , kita peroleh bahwa nilai kritis F adalah 4, 2565 .
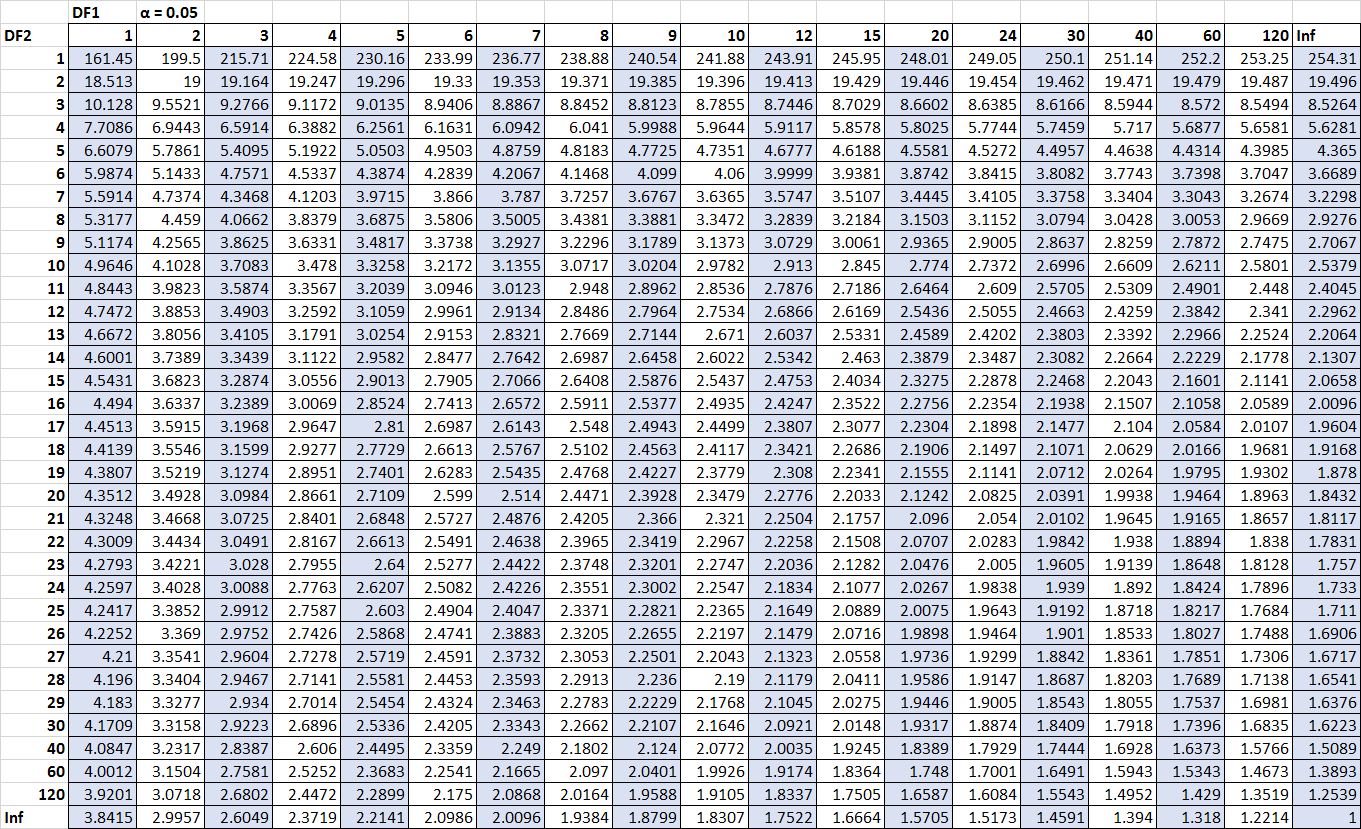
Karena statistik kami f( 5.09 ) lebih besar dari nilai kritis F( 4.2565) , kami dapat menyimpulkan bahwa model regresi secara keseluruhan signifikan secara statistik.
uji F dalam ANOVA
Misalkan kita ingin mengetahui apakah tiga teknik belajar yang berbeda menghasilkan hasil tes yang berbeda atau tidak. Untuk mengujinya, kami merekrut 60 siswa. Kami secara acak menugaskan masing-masing 20 siswa untuk menggunakan salah satu dari tiga teknik belajar selama satu bulan sebagai persiapan ujian. Setelah semua siswa mengikuti ujian, kami kemudian melakukan ANOVA satu arah untuk menentukan apakah teknik belajar berdampak pada hasil ujian atau tidak. Tabel berikut menunjukkan hasil ANOVA satu arah:
| Sumber | SS | df | MS. | F | P. |
|---|---|---|---|---|---|
| Perlakuan | 58.8 | 2 | 29.4 | 1.74 | 0,217 |
| Kesalahan | 202.8 | 12 | 16.9 | ||
| Total | 261.6 | 14 |
Dalam ANOVA, statistik f dihitung sebagai pengobatan MS/kesalahan MS. Statistik ini menunjukkan apakah skor rata-rata ketiga kelompok sama atau tidak.
Dalam contoh ini, statistik F adalah 29.4 / 16.9 = 1.74 .
Misalkan kita ingin mengetahui apakah statistik F ini signifikan pada tingkat alpha = 0,05. Dengan menggunakan tabel distribusi F untuk alpha = 0,05, dengan pembilang derajat kebebasan 2 ( df untuk Treatment) dan penyebut derajat kebebasan 12 ( df untuk Error) , diperoleh nilai kritis F adalah 3,8853 .
Karena f statistik kami ( 1,74 ) tidak lebih besar dari nilai kritis F ( 3,8853) , kami menyimpulkan bahwa tidak ada perbedaan yang signifikan secara statistik antara skor rata-rata ketiga kelompok.
Uji F untuk persamaan varians dua populasi
Misalkan kita ingin mengetahui apakah varian dua populasi sama atau tidak. Untuk mengujinya, kita dapat melakukan uji F untuk variansi yang sama di mana kita mengambil sampel acak sebanyak 25 observasi dari setiap populasi dan mencari varians sampel untuk setiap sampel.
Statistik uji untuk Uji-F ini didefinisikan sebagai berikut:
Statistik F = s 1 2 / s 2 2
dimana s 1 2 dan s 2 2 adalah varians sampel. Semakin jauh rasio ini dari satu, semakin kuat bukti adanya ketimpangan varians dalam populasi.
Nilai kritis uji F didefinisikan sebagai berikut:
Nilai kritis F = nilai yang terdapat pada tabel distribusi F dengan n 1 -1 dan n 2 -1 derajat kebebasan dan tingkat signifikansi α.
Asumsikan varians sampel untuk sampel 1 adalah 30,5 dan varians sampel untuk sampel 2 adalah 20,5. Artinya statistik pengujian kita adalah 30,5 / 20,5 = 1,487 . Untuk mengetahui apakah statistik uji ini signifikan pada alpha = 0,10, kita dapat mencari nilai kritis pada tabel distribusi F yang berhubungan dengan alpha = 0,10, pembilang df = 24 dan penyebut df = 24. Ternyata angka tersebut adalah 1,7019. .
Karena statistik kami f( 1.487 ) tidak lebih besar dari nilai kritis F( 1.7019) , kami menyimpulkan bahwa tidak ada perbedaan yang signifikan secara statistik antara varians kedua populasi ini.
Sumber daya tambahan
Untuk tabel distribusi F lengkap untuk nilai alpha 0,001, 0,01, 0,025, 0,05, dan 0,10, lihat halaman ini .
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya