Distribusi frekuensi tidak dikelompokkan: pengertian & contoh
Misalkan kita melakukan survei yang menanyakan kepada 15 rumah tangga berapa banyak hewan yang mereka miliki di rumahnya. Hasilnya adalah sebagai berikut:
1, 1, 1, 1, 2, 2, 2, 3, 3, 4, 5, 5, 6, 7, 8
Salah satu cara untuk meringkas hasil ini adalah dengan membuat distribusi frekuensi , yang memberi tahu kita seberapa sering nilai yang berbeda muncul dalam kumpulan data.
Kita sering menggunakan distribusi frekuensi berkerumun , di mana kita membuat kelompok nilai dan kemudian merangkum jumlah observasi dalam kumpulan data yang termasuk dalam kelompok tersebut.
Berikut adalah contoh distribusi frekuensi yang dikelompokkan untuk data survei kami:
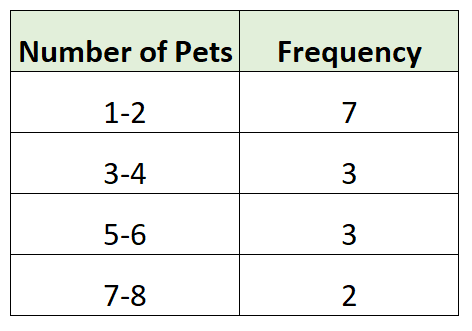
Pertama-tama kami membuat grup berukuran 2 dan kemudian menghitung jumlah observasi individu dari kumpulan data yang termasuk dalam setiap grup. Misalnya:
- 7 keluarga memiliki 1 atau 2 hewan
- 3 keluarga memiliki 3 atau 4 hewan
- 3 keluarga memiliki 5 atau 6 hewan
- 2 keluarga memiliki 7 atau 8 hewan
Jenis distribusi frekuensi lain yang dapat kita buat adalah distribusi frekuensi tak berkelompok , yang menampilkan frekuensi masing-masing nilai data individual, bukan kelompok nilai data.
Berikut adalah contoh distribusi frekuensi yang tidak dikelompokkan untuk data survei kami:
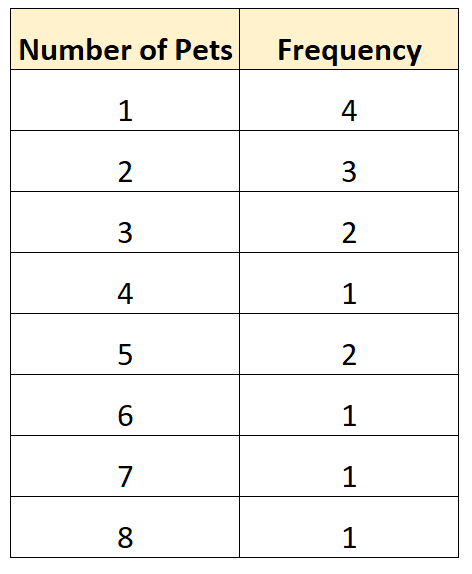
Jenis distribusi frekuensi ini memungkinkan kita melihat secara langsung seberapa sering nilai yang berbeda muncul dalam kumpulan data kita. Misalnya:
- 4 keluarga memiliki 1 hewan
- 3 keluarga memiliki 2 hewan
- 2 keluarga memiliki 3 hewan
- 1 keluarga memiliki 4 hewan
Dan seterusnya.
Kapan menggunakan distribusi frekuensi yang tidak dikelompokkan
Distribusi frekuensi yang tidak dikelompokkan dapat berguna ketika Anda ingin melihat seberapa sering setiap nilai muncul dalam kumpulan data.
Perhatikan bahwa distribusi frekuensi yang tidak dikelompokkan bekerja paling baik dengan kumpulan data kecil yang hanya memiliki sedikit nilai unik.
Misalnya, pada data survei kami sebelumnya, hanya terdapat 8 nilai unik, sehingga masuk akal untuk membuat distribusi frekuensi yang tidak dikelompokkan.
Namun, jika kita memiliki ribuan kumpulan data yang berisi ratusan atau nilai unik, distribusi frekuensi yang tidak dikelompokkan akan sangat memakan waktu dan sulit untuk mengumpulkan informasi.
Untuk kumpulan data yang lebih besar, masuk akal untuk membuat distribusi frekuensi yang dikelompokkan.
Cara memvisualisasikan distribusi frekuensi yang tidak dikelompokkan
Cara paling sederhana untuk memvisualisasikan nilai dalam distribusi frekuensi yang tidak dikelompokkan adalah dengan membuat poligon frekuensi , yang menampilkan frekuensi masing-masing nilai dalam grafik sederhana.
Berikut tampilan poligon frekuensi untuk data sampel kita:
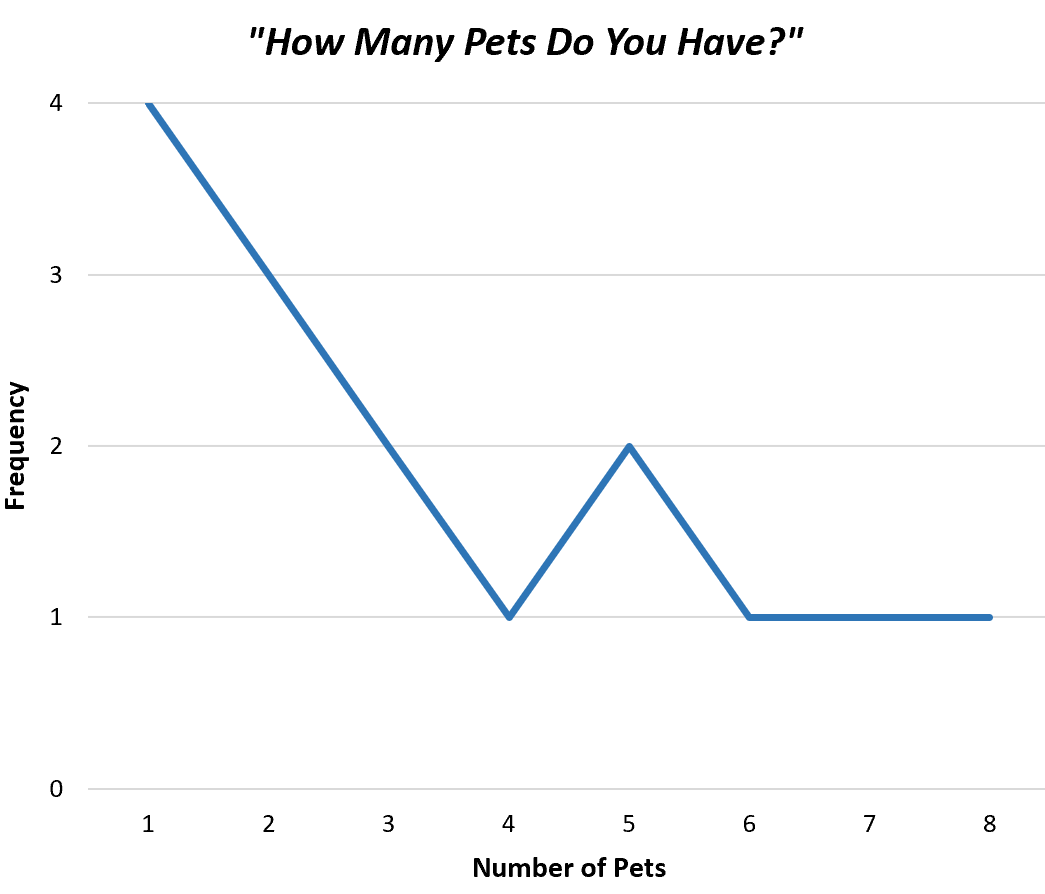
Hal ini membantu kami dengan cepat memahami seberapa sering setiap nilai muncul dalam kumpulan data.
Alternatifnya, kita dapat membuat diagram batang untuk menampilkan data yang sama persis menggunakan batang, bukan satu garis:
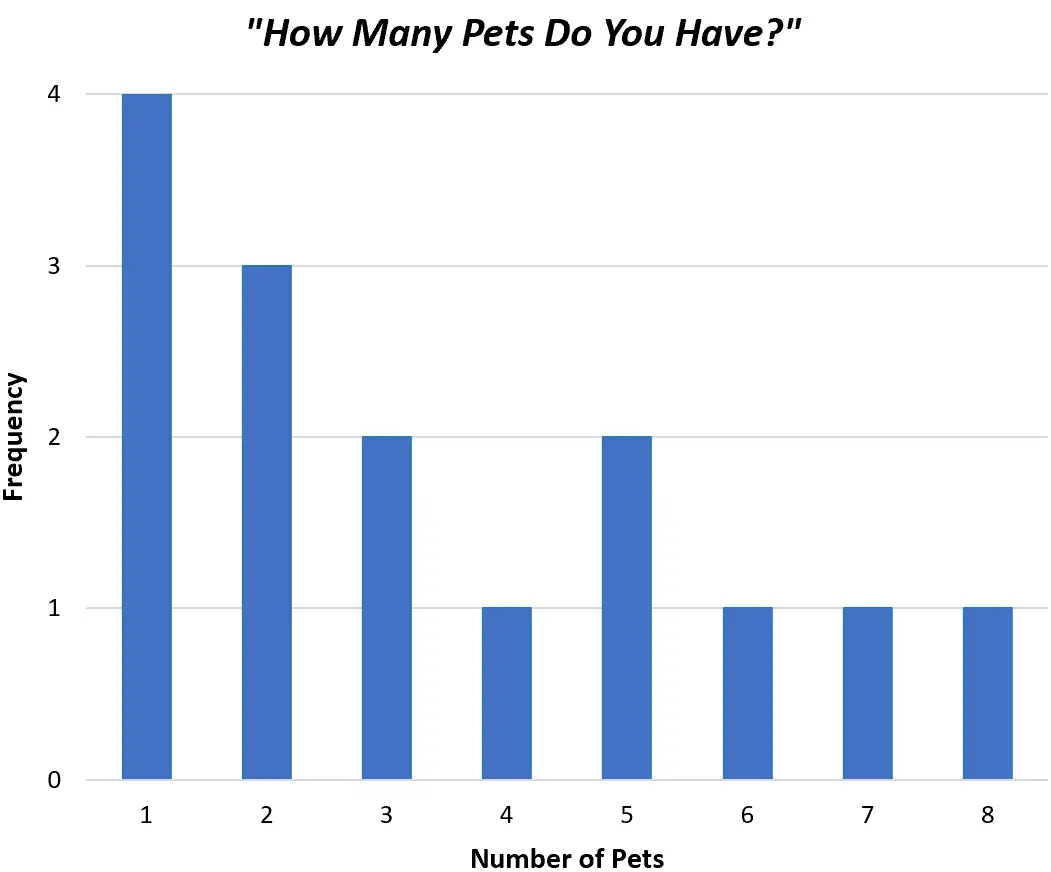
Kedua grafik tersebut memungkinkan kita memahami dengan cepat distribusi nilai dalam kumpulan data kita.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya