Apa itu distribusi terbuka?
Dalam statistika, distribusi terbuka adalah distribusi frekuensi di mana satu atau lebih kelas (atau “bins”) terbuka.
Misalnya, distribusi frekuensi berikut mewakili distribusi terbuka yang kelas terkecilnya terbuka:
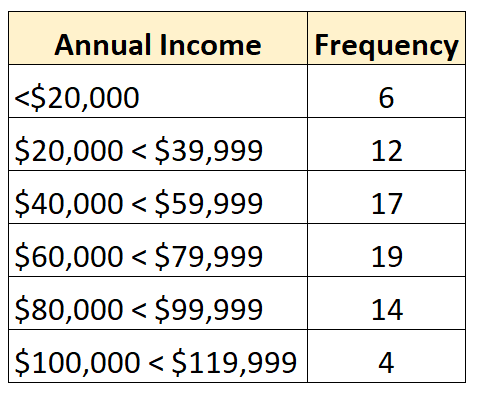
Dan distribusi frekuensi berikut menunjukkan distribusi terbuka dimana kelas terbesarnya terbuka:
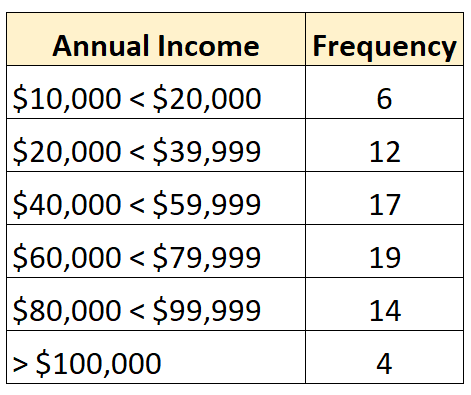
Sebaliknya distribusi tertutup adalah distribusi yang setiap kelas distribusi frekuensinya mempunyai batas atas dan batas bawah, seperti berikut:
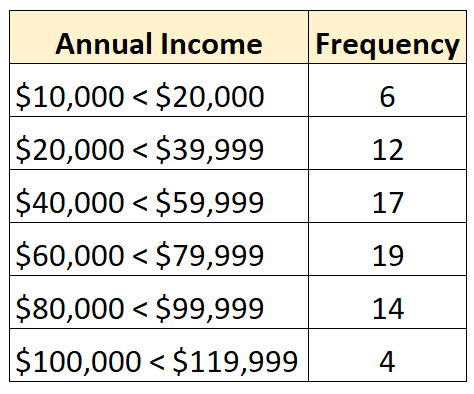
Apa yang menyebabkan distribusi terbuka?
Distribusi terbuka seringkali merupakan hasil dari pilihan peneliti untuk mengumpulkan data sedemikian rupa sehingga salah satu kelas akhirnya menjadi terbuka.
Misalnya, seorang peneliti mensurvei penduduk kota tertentu dan menanyakan pendapatan rumah tangga tahunan mereka.
Peneliti dapat memilih untuk memberikan jawaban seluas-luasnya yaitu “>$100.000” karena mereka mengetahui bahwa penduduk berpendapatan tinggi mungkin tidak nyaman membagi penghasilan mereka jika penghasilannya jauh lebih besar dari $100.000.
Sebaliknya, peneliti mungkin memilih untuk memberikan jawaban sesingkat mungkin karena ia mengetahui bahwa penduduk yang berpenghasilan sangat sedikit juga tidak akan merasa nyaman membagi penghasilan yang sedikit tersebut.
Singkatnya, peneliti sering kali menyertakan kursus terbuka dalam survei mereka karena mereka ingin memaksimalkan jumlah orang yang merasa nyaman menjawab pertanyaan survei.
Masalah dengan distribusi terbuka
Masalah dengan distribusi terbuka adalah data sebenarnya disensor . Dengan kata lain, kita dapat mengetahui jumlah orang yang berpenghasilan lebih dari $100.000 di suatu kota, namun kita tidak mengetahui secara pasti pendapatan tahunan mereka.
Ada kemungkinan bahwa beberapa orang memperoleh $150.000, $250.000, $500.000 atau bahkan lebih, namun kami tidak tahu karena masing-masing dari orang-orang ini tidak dapat menunjukkan bahwa mereka memperoleh “>$100.000” dalam penyelidikan.
Karena data disensor dalam distribusi terbuka, kami juga tidak dapat menghitung rata-rata dan deviasi standar yang tepat dari nilai-nilai dalam kumpulan data karena kami tidak memiliki akses ke semua nilai dalam data mentah.
Bagaimana menganalisis distribusi terbuka
Karena kita tidak dapat menghitung rata-rata pasti dari suatu distribusi terbuka, kita sering menggunakan median sebagai ukuran “pusat” kumpulan data.
Ingatlah bahwa median mewakili nilai tengah dari kumpulan data.
Saat bekerja dengan distribusi terbuka, kita dapat menggunakan rumus berikut untuk mencari estimasi median terbaik:
Perkiraan median terbaik: L + ((n/2 – F) / f) * w
Emas:
- L : Batas bawah kelompok menengah
- n : Jumlah total observasi
- F : Frekuensi kumulatif sampai kelompok menengah
- f : Frekuensi kelompok menengah
- w : Lebar kelompok tengah
Misalnya, kita mempunyai distribusi terbuka berikut:
Ada total 72 nilai dalam dataset. Jadi, kita tahu bahwa nilai mediannya akan berada di antara nilai terbesar ke-36 dan ke-37 dalam dataset. Masing-masing nilai ini termasuk dalam kelas “$60.000 – $79.999”, jadi kita tahu pendapatan median berada di kisaran tersebut.
Perkiraan median terbaik kami adalah:
Median: 60.000 + ((72/2 – 25) / 19) * 19.999 = $71.578
Nilai ini mewakili perkiraan terbaik kami mengenai median pendapatan tahunan individu dalam kumpulan data ini.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya