Cara melakukan uji kesesuaian chi-kuadrat di stata
Uji kesesuaian chi-kuadrat digunakan untuk menentukan apakah suatu variabel kategori mengikuti distribusi hipotetis atau tidak.
Tutorial ini menjelaskan cara melakukan uji kecocokan chi-kuadrat di Stata.
Contoh: Uji kesesuaian chi-kuadrat di Stata
Untuk mengilustrasikan cara melakukan tes ini, kami akan menggunakan kumpulan data bernama nlsw88 , yang berisi informasi tentang statistik pekerjaan perempuan di Amerika Serikat pada tahun 1988.
Ikuti langkah-langkah berikut untuk melakukan uji kesesuaian chi-kuadrat untuk menentukan apakah distribusi ras yang sebenarnya dalam kumpulan data ini adalah: 70% Putih, 20% Hitam, 10% Lainnya.
Langkah 1: Muat dan tampilkan data mentah.
Pertama, kita akan memuat data dengan mengetikkan perintah berikut:
sistem nlsw88
Kita dapat melihat data mentahnya dengan mengetikkan perintah berikut:
saudara
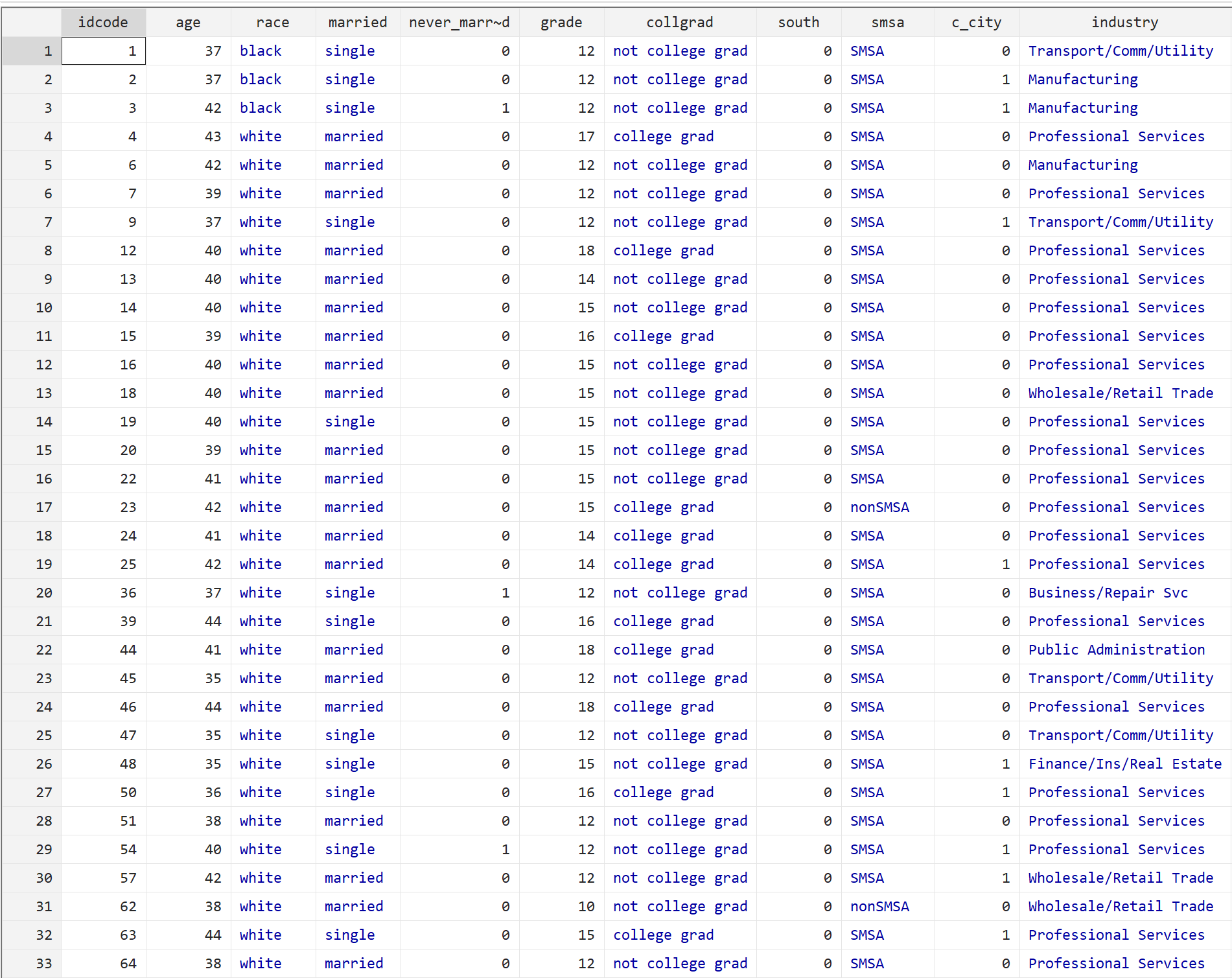
Setiap baris menampilkan informasi tentang seseorang, termasuk usia, ras, status perkawinan, tingkat pendidikan, dan berbagai faktor lainnya.
Langkah 2: Muat paket penyesuaian.
Untuk melakukan uji kesesuaian, kita perlu menginstal paket csgof . Kita dapat melakukannya dengan mengetikkan perintah berikut:
temukan csgof
Jendela baru akan muncul. Klik tautan yang bertuliskan csgof dari https://stats.idre.ucla.edu/stat/stata/ado/analisis .
Jendela lain akan muncul. Klik tautan yang bertuliskan klik di sini untuk menginstal .
Menginstal paket hanya memerlukan waktu beberapa detik.
Langkah 3: Lakukan uji kecocokan.
Setelah paket diinstal, kita dapat melakukan uji kesesuaian pada data untuk menentukan apakah rincian ras yang sebenarnya adalah: 70% Putih, 20% Hitam, 10% Lainnya.
Kami akan menggunakan sintaks berikut untuk melakukan pengujian:
csgof variabel_of_interest, expperc(daftar_of_expected_percentages)
Berikut adalah sintaks yang tepat yang akan kita gunakan dalam kasus kita:
jalankan csgof,experc(70, 20, 10)

Berikut cara menafsirkan hasilnya:
Kotak ringkasan: Kotak ini menunjukkan kepada kita persentase yang diharapkan, frekuensi yang diharapkan, dan frekuensi yang diamati untuk setiap balapan. Misalnya:
- Persentase orang kulit putih yang diharapkan adalah 70%. Ini adalah persentase yang kami tentukan.
- Frekuensi yang diharapkan dari individu kulit putih adalah 1.572,2. Hal ini dihitung berdasarkan fakta bahwa terdapat 2.246 individu dalam dataset, sehingga 70% dari jumlah tersebut adalah 1.572,2.
- Frekuensi yang diamati pada individu kulit putih adalah 1.637. Ini adalah jumlah sebenarnya orang kulit putih dalam kumpulan data.
Chisq(2): Ini adalah statistik uji Chi-kuadrat untuk uji goodness-of-fit. Ternyata 218.13.
p: Ini adalah nilai p yang terkait dengan statistik uji Chi-kuadrat. Hasilnya adalah 0. Karena kurang dari 0,05, kita gagal menolak hipotesis nol yang menyatakan bahwa distribusi ras yang sebenarnya adalah 70% Kulit Putih, 20% Kulit Hitam, dan 10% Lainnya. Kami mempunyai cukup bukti untuk menyimpulkan bahwa distribusi rasial yang sebenarnya berbeda dari distribusi hipotetis ini.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya