Cara menghasilkan distribusi normal dengan python (dengan contoh)
Anda dapat dengan cepat menghasilkan distribusi normal dengan Python menggunakan fungsi numpy.random.normal() , yang menggunakan sintaks berikut:
numpy. random . normal (loc=0.0, scale=1.0, size=None)
Emas:
- loc : Rata-rata distribusi. Nilai defaultnya adalah 0.
- skala: Standar deviasi distribusi. Nilai defaultnya adalah 1.
- ukuran: ukuran sampel.
Tutorial ini menunjukkan contoh penggunaan fungsi ini untuk menghasilkan distribusi normal dengan Python.
Terkait:Cara Membuat Kurva Lonceng dengan Python
Contoh: Menghasilkan Distribusi Normal dengan Python
Kode berikut menunjukkan cara menghasilkan distribusi normal dengan Python:
from numpy. random import seed
from numpy. random import normal
#make this example reproducible
seed(1)
#generate sample of 200 values that follow a normal distribution
data = normal (loc=0, scale=1, size=200)
#view first six values
data[0:5]
array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Kita dapat dengan cepat menemukan mean dan deviasi standar dari distribusi ini:
import numpy as np
#find mean of sample
n.p. mean (data)
0.1066888148479486
#find standard deviation of sample
n.p. std (data, ddof= 1 )
0.9123296653173484
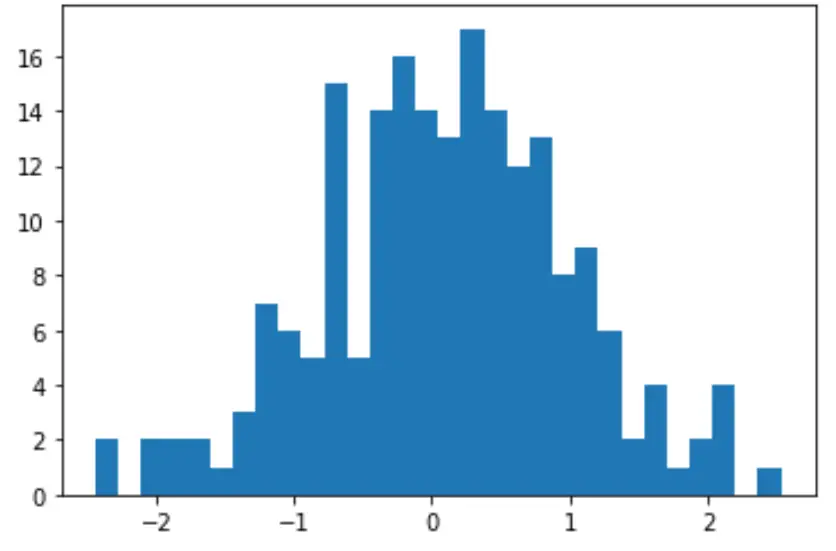
Kita juga dapat membuat histogram cepat untuk memvisualisasikan distribusi nilai data:
import matplotlib. pyplot as plt
count, bins, ignored = plt. hist (data, 30)
plt. show ()
Kami bahkan dapat melakukan tes Shapiro-Wilk untuk melihat apakah kumpulan data tersebut berasal dari populasi normal:
from scipy. stats import shapiro
#perform Shapiro-Wilk test
shapiro(data)
ShapiroResult(statistic=0.9958659410, pvalue=0.8669294714)
Nilai p dari tes tersebut ternyata 0,8669 . Karena nilai ini tidak kurang dari 0,05, maka kita dapat berasumsi bahwa data sampel berasal dari populasi yang berdistribusi normal.
Hasil ini seharusnya tidak mengejutkan karena kami menghasilkan data menggunakan fungsi numpy.random.normal() , yang menghasilkan sampel data acak dari distribusi normal.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya