Cara menggunakan metode siku dengan python untuk menemukan cluster yang optimal
Salah satu algoritma pengelompokan yang paling umum dalam pembelajaran mesin dikenal sebagai pengelompokan k-means .
K-means clustering adalah teknik di mana kita menempatkan setiap observasi dari suatu dataset ke dalam salah satu K cluster.
Tujuan akhirnya adalah untuk memiliki K cluster dimana observasi dalam setiap cluster cukup mirip satu sama lain, sedangkan observasi dalam cluster yang berbeda sangat berbeda satu sama lain.
Saat melakukan k-means clustering, langkah pertama adalah memilih nilai K – jumlah cluster yang ingin kita observasi.
Salah satu cara paling umum untuk memilih nilai K dikenal sebagai metode siku , yang melibatkan pembuatan plot dengan jumlah cluster pada sumbu x dan total jumlah kuadrat pada sumbu y, kemudian mengidentifikasi di mana “lutut” atau belokan muncul dalam plot.
Titik pada sumbu x di mana “lutut” muncul memberi tahu kita jumlah cluster optimal untuk digunakan dalam algoritma clustering k-means.
Contoh berikut menunjukkan cara menggunakan metode siku dengan Python.
Langkah 1: Impor modul yang diperlukan
Pertama, kita akan mengimpor semua modul yang kita perlukan untuk melakukan k-means clustering:
import pandas as pd
import numpy as np
import matplotlib. pyplot as plt
from sklearn. cluster import KMeans
from sklearn. preprocessing import StandardScaler
Langkah 2: Buat DataFrame
Selanjutnya, kita akan membuat DataFrame yang berisi tiga variabel untuk 20 pemain bola basket berbeda:
#createDataFrame
df = pd. DataFrame ({' points ': [18, np.nan, 19, 14, 14, 11, 20, 28, 30, 31,
35, 33, 29, 25, 25, 27, 29, 30, 19, 23],
' assists ': [3, 3, 4, 5, 4, 7, 8, 7, 6, 9, 12, 14,
np.nan, 9, 4, 3, 4, 12, 15, 11],
' rebounds ': [15, 14, 14, 10, 8, 14, 13, 9, 5, 4,
11, 6, 5, 5, 3, 8, 12, 7, 6, 5]})
#drop rows with NA values in any columns
df = df. dropna ()
#create scaled DataFrame where each variable has mean of 0 and standard dev of 1
scaled_df = StandardScaler(). fit_transform (df)
Langkah 3: Gunakan Metode Siku untuk Menemukan Jumlah Cluster yang Optimal
Katakanlah kita ingin menggunakan pengelompokan k-means untuk mengelompokkan aktor serupa berdasarkan ketiga metrik ini.
Untuk melakukan clustering k-means dengan Python, kita dapat menggunakan fungsi KMeans dari modul sklearn .
Argumen paling penting untuk fungsi ini adalah n_clusters , yang menentukan berapa banyak cluster yang akan dijadikan tempat observasi.
Untuk menentukan jumlah cluster yang optimal, kita akan membuat grafik yang menampilkan jumlah cluster serta SSE (sum of squared error) model.
Kita kemudian akan mencari “lutut” di mana jumlah kuadrat mulai “membungkuk” atau stabil. Titik ini mewakili jumlah cluster yang optimal.
Kode berikut menunjukkan cara membuat plot jenis ini yang menampilkan jumlah cluster pada sumbu x dan SSE pada sumbu y:
#initialize kmeans parameters kmeans_kwargs = { " init ": " random ", " n_init ": 10, " random_state ": 1, } #create list to hold SSE values for each k sse = [] for k in range(1, 11): kmeans = KMeans(n_clusters=k, ** kmeans_kwargs) kmeans. fit (scaled_df) sse. append (kmeans.inertia_) #visualize results plt. plot (range(1, 11), sse) plt. xticks (range(1, 11)) plt. xlabel (" Number of Clusters ") plt. ylabel (“ SSE ”) plt. show ()
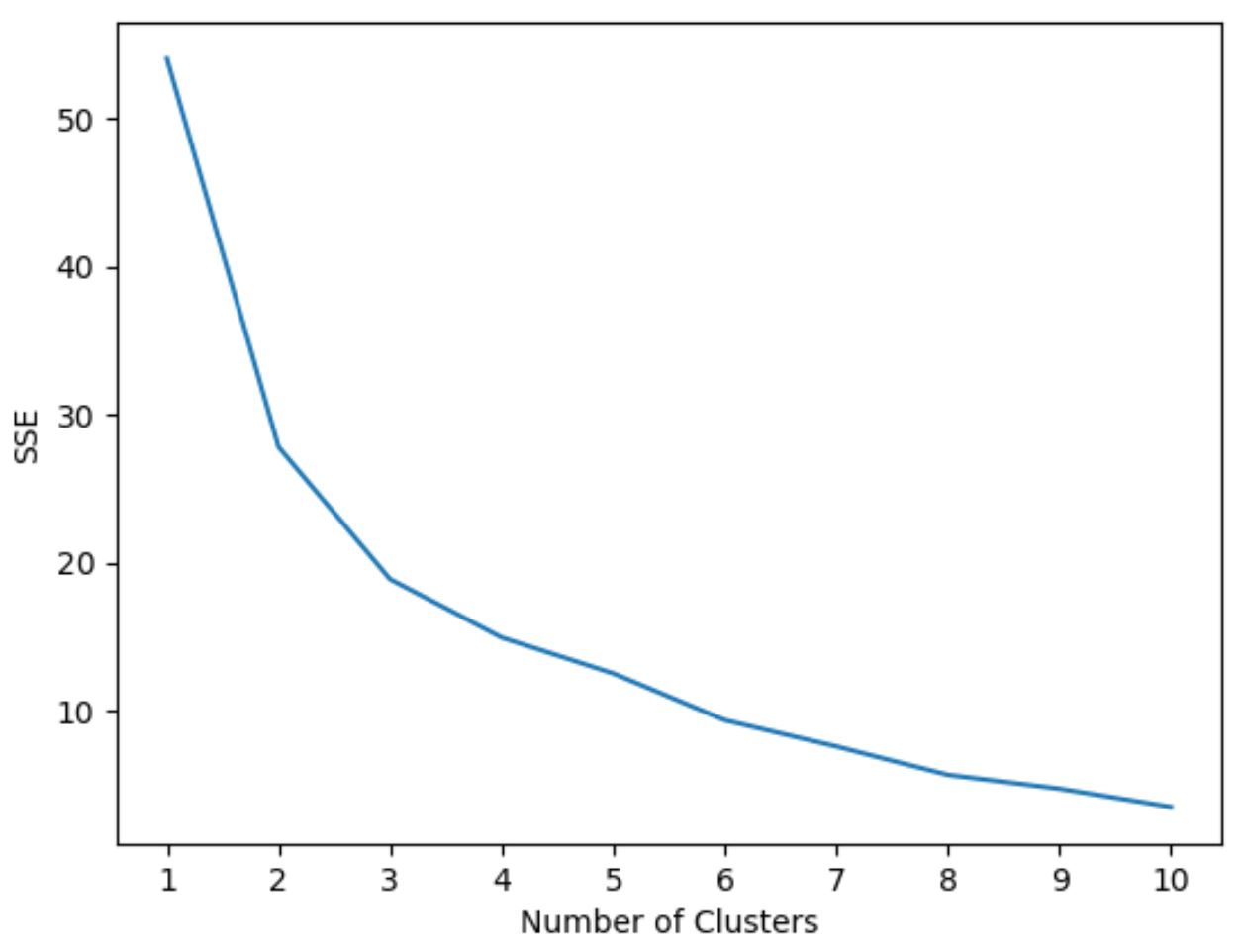
Pada grafik ini terlihat terdapat kekusutan atau “lutut” pada k = 3 cluster .
Jadi, kita akan menggunakan 3 cluster saat menyesuaikan model clustering k-means pada langkah berikutnya.
Langkah 4: Lakukan K-Means Clustering dengan K Optimal
Kode berikut menunjukkan cara melakukan k-means clustering pada dataset menggunakan nilai optimal k dari 3:
#instantiate the k-means class, using optimal number of clusters
kmeans = KMeans(init=" random ", n_clusters= 3 , n_init= 10 , random_state= 1 )
#fit k-means algorithm to data
kmeans. fit (scaled_df)
#view cluster assignments for each observation
kmeans. labels_
array([1, 1, 1, 1, 1, 1, 2, 2, 0, 0, 0, 0, 2, 2, 2, 0, 0, 0])
Tabel yang dihasilkan memperlihatkan penetapan cluster untuk setiap observasi di DataFrame.
Untuk membuat hasil ini lebih mudah diinterpretasikan, kita bisa menambahkan kolom ke DataFrame yang memperlihatkan penetapan cluster setiap pemain:
#append cluster assingments to original DataFrame
df[' cluster '] = kmeans. labels_
#view updated DataFrame
print (df)
points assists rebounds cluster
0 18.0 3.0 15 1
2 19.0 4.0 14 1
3 14.0 5.0 10 1
4 14.0 4.0 8 1
5 11.0 7.0 14 1
6 20.0 8.0 13 1
7 28.0 7.0 9 2
8 30.0 6.0 5 2
9 31.0 9.0 4 0
10 35.0 12.0 11 0
11 33.0 14.0 6 0
13 25.0 9.0 5 0
14 25.0 4.0 3 2
15 27.0 3.0 8 2
16 29.0 4.0 12 2
17 30.0 12.0 7 0
18 19.0 15.0 6 0
19 23.0 11.0 5 0
Kolom cluster berisi nomor cluster (0, 1, atau 2) yang telah ditetapkan untuk setiap pemain.
Pemain yang tergabung dalam cluster yang sama memiliki nilai yang kurang lebih sama untuk kolom poin , assist , dan rebound .
Catatan : Anda dapat menemukan dokumentasi lengkap untuk fungsi KMeans sklearn di sini .
Sumber daya tambahan
Tutorial berikut menjelaskan cara melakukan tugas umum lainnya dengan Python:
Cara melakukan regresi linier dengan Python
Cara Melakukan Regresi Logistik dengan Python
Cara melakukan validasi silang K-Fold dengan Python
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya