Binning frekuensi yang sama dengan python
Dalam statistik, pengelompokan adalah proses menempatkan nilai numerik ke dalam kelompok .
Bentuk pengelompokan yang paling umum dikenal sebagai pengelompokan dengan lebar yang sama , di mana kita membagi kumpulan data menjadi k kelompok dengan lebar yang sama.
Bentuk pengelompokan yang kurang umum digunakan dikenal sebagai pengelompokan frekuensi yang sama , di mana kita membagi kumpulan data menjadi k kelompok yang semuanya memiliki jumlah frekuensi yang sama.
Tutorial ini menjelaskan cara melakukan pengelompokan frekuensi yang sama dengan python.
Binning Frekuensi yang Sama dengan Python
Misalkan kita memiliki kumpulan data yang berisi 100 nilai:
import numpy as np import matplotlib.pyplot as plt #create data np.random.seed(1) data = np.random.randn(100) #view first 5 values data[:5] array([ 1.62434536, -0.61175641, -0.52817175, -1.07296862, 0.86540763])
Pengelompokan lebar yang sama:
Jika kita membuat histogram untuk menampilkan nilai-nilai ini, Python akan secara default menggunakan pengelompokan dengan lebar yang sama:
#create histogram with equal-width bins n, bins, patches = plt.hist(data, edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -1.85282729, -1.40411588, -0.95540447, -0.50669306, -0.05798165, 0.39072977, 0.83944118, 1.28815259, 1.736864, 2.18557541]), array([ 3., 1., 6., 17., 19., 20., 14., 12., 5., 3.]))
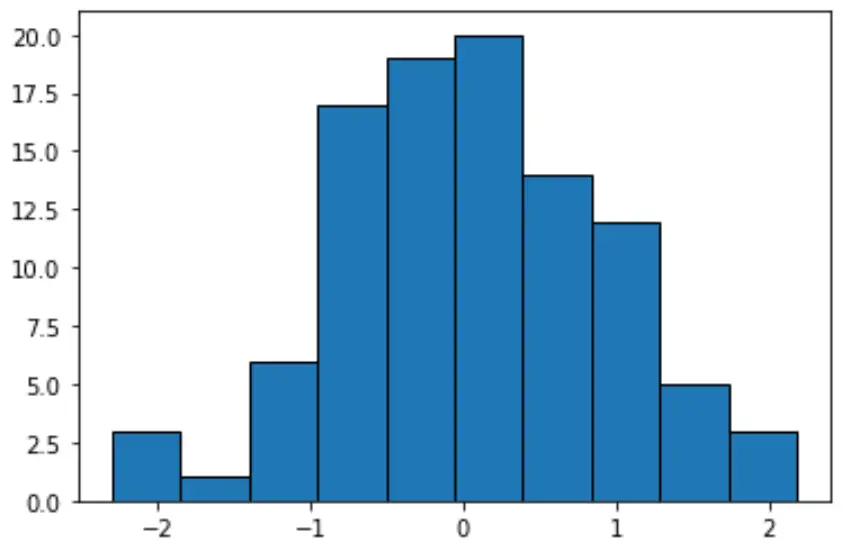
Setiap kelompok mempunyai lebar yang sama yaitu sekitar 0,4487, tetapi setiap kelompok tidak mempunyai jumlah pengamatan yang sama. Misalnya:
- Bin pertama terbentang dari -2.3015387 hingga -1.8528279 dan berisi 3 observasi.
- Bin kedua terbentang dari -1.8528279 hingga -1.40411588 dan berisi 1 observasi.
- Bin ketiga terbentang dari -1.40411588 hingga -0.95540447 dan berisi 6 observasi.
Dan seterusnya.
Pengelompokan frekuensi yang sama:
Untuk membuat keranjang berisi jumlah observasi yang sama, kita dapat menggunakan fungsi berikut:
#define function to calculate equal-frequency bins def equalObs(x, nbin): nlen = len(x) return np.interp(np.linspace(0, nlen, nbin + 1), np.arange(nlen), np.sort(x)) #create histogram with equal-frequency bins n, bins, patches = plt.hist(data, equalObs(data, 10), edgecolor='black') plt.show() #display bin boundaries and frequency per bin bins, n (array([-2.3015387 , -0.93576943, -0.67124613, -0.37528495, -0.20889423, 0.07734007, 0.2344157, 0.51292982, 0.86540763, 1.19891788, 2.18557541]), array([10., 10., 10., 10., 10., 10., 10., 10., 10., 10.]))
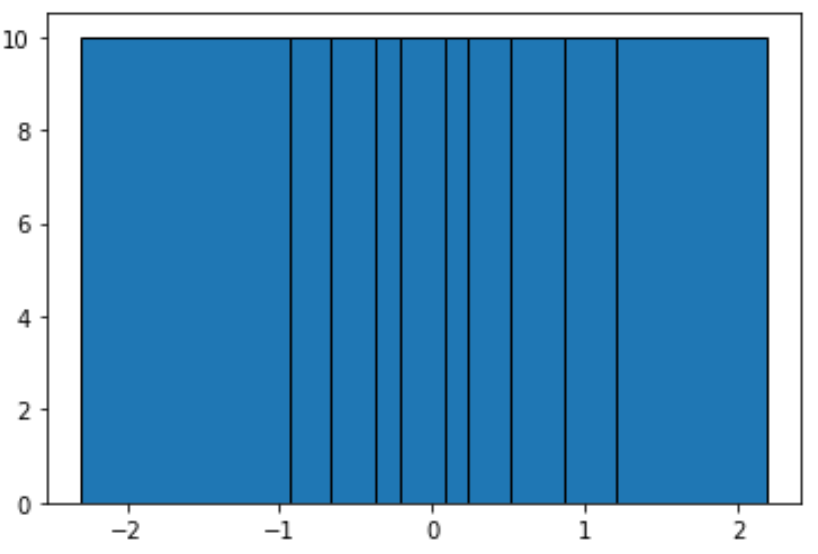
Setiap kelompok tidak sama lebarnya, tetapi setiap kelompok berisi jumlah pengamatan yang sama. Misalnya:
- Bin pertama terbentang dari -2.3015387 hingga -0.93576943 dan berisi 10 observasi.
- Bin kedua terbentang dari -0.93576943 hingga -0.67124613 dan berisi 10 observasi.
- Bin ketiga terbentang dari -0,67124613 hingga -0,37528495 dan berisi 10 observasi.
Dan seterusnya.
Kita dapat melihat dari histogram bahwa setiap nampan jelas tidak memiliki lebar yang sama, tetapi setiap nampan berisi jumlah pengamatan yang sama, yang dibuktikan dengan fakta bahwa tinggi setiap nampan adalah sama.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya