Cara melakukan regresi logistik di spss
Regresi logistik adalah metode yang kami gunakan untuk menyesuaikan model regresi ketika variabel responsnya adalah biner.
Tutorial ini menjelaskan cara melakukan regresi logistik di SPSS.
Contoh: regresi logistik di SPSS
Gunakan langkah-langkah berikut untuk melakukan regresi logistik di SPSS untuk kumpulan data yang menunjukkan apakah pemain bola basket perguruan tinggi direkrut ke NBA atau tidak (draft: 0 = tidak, 1 = ya) berdasarkan IPK mereka. poin per game dan tingkat divisinya.
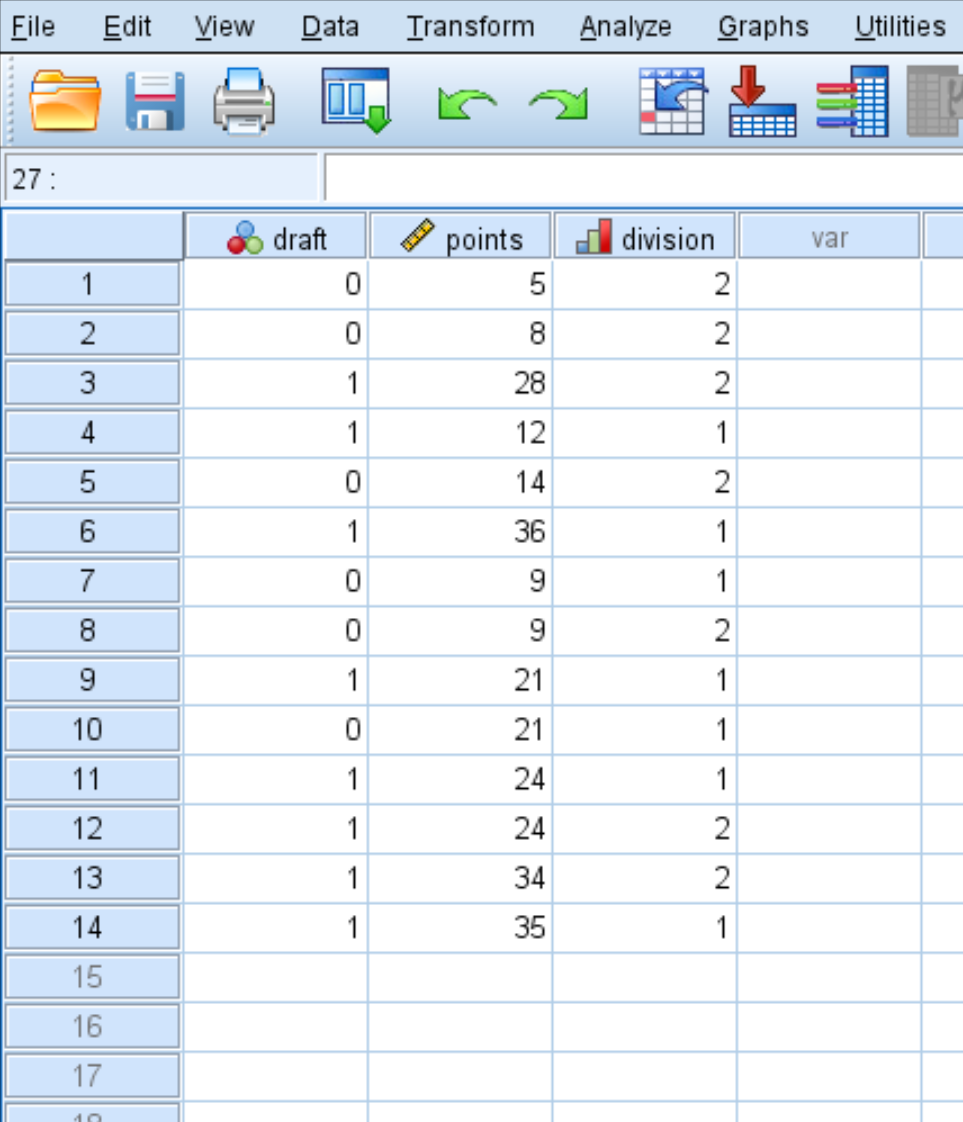
Langkah 1: Masukkan datanya.
Pertama, masukkan data berikut:
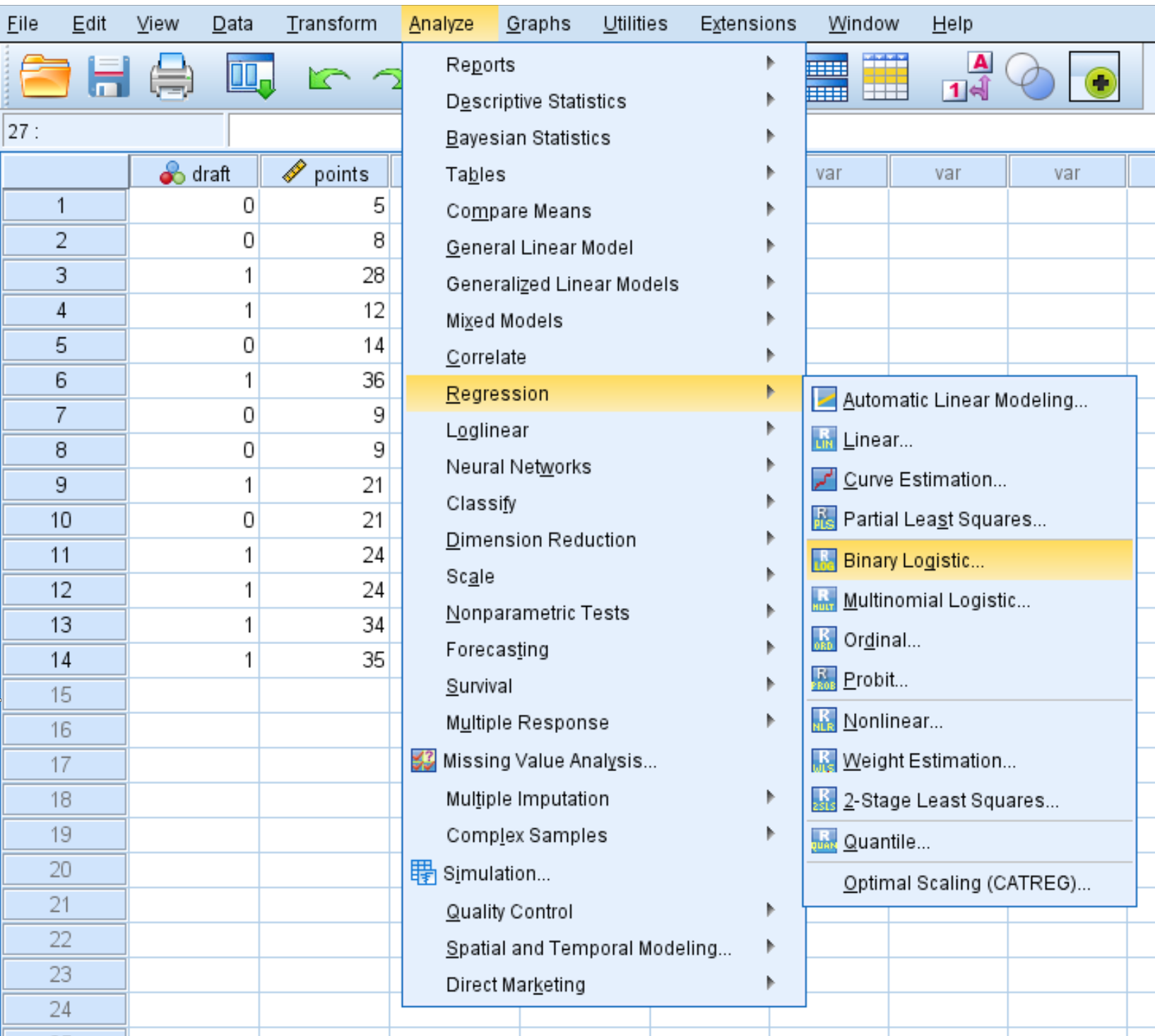
Langkah 2: Lakukan regresi logistik.
Klik tab Analisis , lalu Regresi , lalu Regresi Logistik Biner :
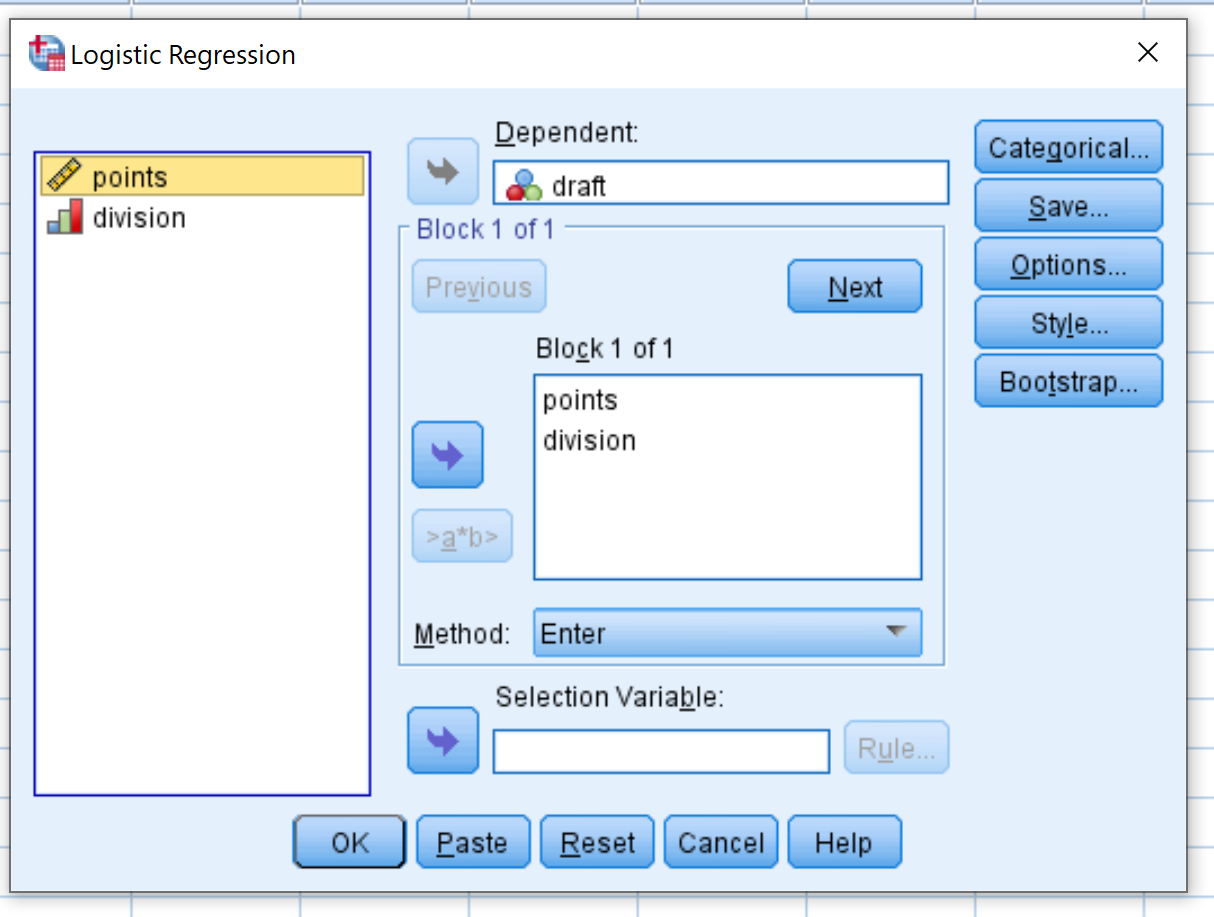
Di jendela baru yang muncul, seret proyek variabel respon biner ke dalam area berlabel Dependent. Kemudian seret titik dua dan pembagian variabel prediktor ke dalam kotak berlabel Blok 1 dari 1. Biarkan metode disetel ke Enter. Lalu klik oke .
Langkah 3. Interpretasikan hasilnya.
Setelah Anda klik OK , maka akan muncul hasil regresi logistik:
Berikut cara menafsirkan hasilnya:
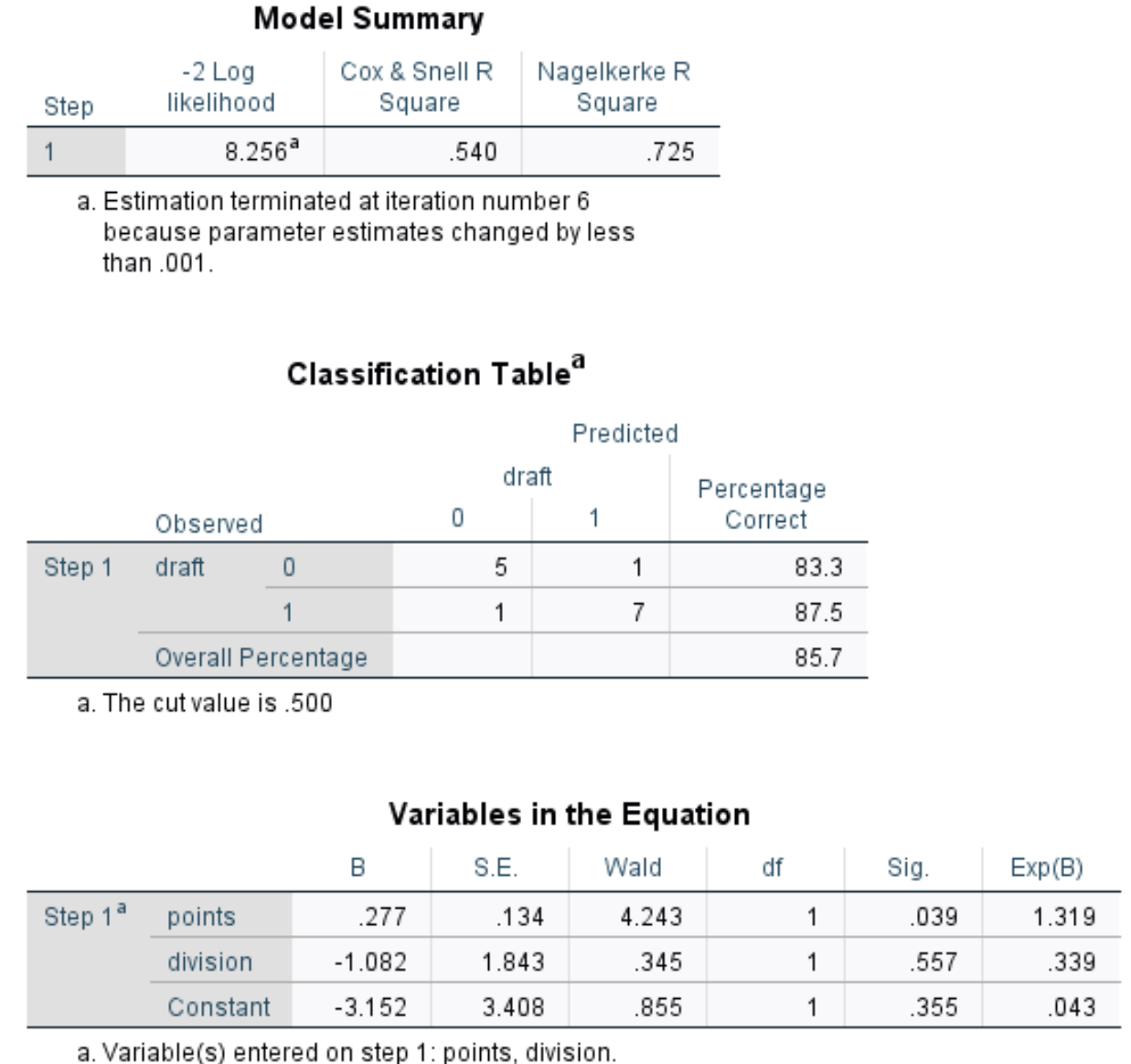
Ringkasan Model: Metrik yang paling berguna dalam tabel ini adalah Nagelkerke R Square, yang menunjukkan persentase variasi dalam variabel respons yang dapat dijelaskan oleh variabel prediktor. Dalam hal ini poin dan pembagian dapat menjelaskan 72,5% variabilitas rancangan.
Tabel klasifikasi: Metrik yang paling berguna dalam tabel ini adalah persentase keseluruhan, yang memberi tahu kita persentase observasi yang dapat diklasifikasikan dengan benar oleh model. Dalam hal ini, model regresi logistik mampu memprediksi dengan tepat hasil rancangan 85,7% pemain.
Variabel dalam persamaan: Tabel terakhir ini memberi kita beberapa pengukuran yang berguna, termasuk:
- Wald: Statistik uji Wald untuk setiap variabel prediktor, yang digunakan untuk menentukan apakah setiap variabel prediktor signifikan secara statistik atau tidak.
- Sig: nilai p yang sesuai dengan statistik uji Wald untuk setiap variabel prediktor. Kita melihat bahwa nilai p untuk poin adalah 0,039 dan nilai p untuk pembagian adalah 0,557.
- Exp(B): rasio odds untuk setiap variabel prediktor. Ini memberi tahu kita perubahan peluang seorang pemain untuk direkrut terkait dengan peningkatan satu unit dalam variabel prediktor tertentu. Misalnya, peluang pemain Divisi 2 untuk direkrut hanya 0,339 dari peluang pemain Divisi 1 untuk direkrut. Demikian pula, setiap peningkatan unit tambahan dalam poin per game dikaitkan dengan peningkatan peluang seorang pemain untuk direkrut sebesar 1,319.
Kita kemudian dapat menggunakan koefisien (nilai pada kolom berlabel B) untuk memprediksi kemungkinan pemain tertentu akan direkrut, menggunakan rumus berikut:
Peluang = e -3.152 + 0.277 (poin) – 1.082 (pembagian) / (1+e -3.152 + 0.277 (poin) – 1.082 (pembagian) )
Misalnya, probabilitas bahwa seorang pemain yang memiliki rata-rata 20 poin per game dan bermain di Divisi 1 akan direkrut dapat dihitung sebagai berikut:
Probabilitas = e -3.152 + 0.277(20) – 1.082(1) / (1+e -3.152 + 0.277(20) – 1.082(1) ) = 0.787 .
Karena probabilitas ini lebih besar dari 0,5, kami memperkirakan bahwa pemain ini akan direkrut.
Langkah 4. Laporkan hasilnya.
Terakhir, kami ingin melaporkan hasil regresi logistik kami. Berikut ini contoh cara melakukan ini:
Regresi logistik dilakukan untuk menentukan bagaimana poin per permainan dan tingkat divisi mempengaruhi kemungkinan pemain bola basket untuk direkrut. Sebanyak 14 pemain digunakan dalam analisis.
Model tersebut menjelaskan 72,5% variasi hasil proyek dan mengklasifikasikan 85,7% kasus dengan benar.
Peluang pemain Divisi 2 untuk direkrut hanya 0,339 dari peluang pemain Divisi 1 untuk direkrut.
Setiap peningkatan unit tambahan dalam poin per game dikaitkan dengan peningkatan peluang pemain untuk direkrut sebesar 1.319.
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya