Regresi ridge di r (langkah demi langkah)
Regresi ridge adalah metode yang dapat kita gunakan untuk menyesuaikan model regresi ketika terdapat multikolinearitas dalam data.
Singkatnya, regresi kuadrat terkecil berupaya menemukan estimasi koefisien yang meminimalkan jumlah sisa kuadrat (RSS):
RSS = Σ(y saya – ŷ saya )2
Emas:
- Σ : Simbol Yunani yang berarti jumlah
- y i : nilai respon sebenarnya untuk observasi ke-i
- ŷ i : Nilai respons yang diprediksi berdasarkan model regresi linier berganda
Sebaliknya, regresi ridge berupaya meminimalkan hal-hal berikut:
RSS + λΣβ j 2
dimana j beralih dari 1 ke p variabel prediktor dan λ ≥ 0.
Suku kedua dalam persamaan ini dikenal sebagai penalti penarikan . Dalam regresi ridge, kami memilih nilai λ yang menghasilkan uji MSE (mean square error) serendah mungkin.
Tutorial ini memberikan contoh langkah demi langkah tentang cara melakukan regresi ridge di R.
Langkah 1: Muat data
Untuk contoh ini, kita akan menggunakan kumpulan data bawaan R yang disebut mtcars . Kita akan menggunakan hp sebagai variabel respon dan variabel berikut sebagai prediktor:
- mpg
- berat
- kotoran
- qdetik
Untuk melakukan regresi ridge, kita akan menggunakan fungsi dari paket glmnet . Paket ini mengharuskan variabel respon berupa vektor dan himpunan variabel prediktor berasal dari kelas data.matrix .
Kode berikut menunjukkan cara mendefinisikan data kita:
#define response variable
y <- mtcars$hp
#define matrix of predictor variables
x <- data.matrix(mtcars[, c('mpg', 'wt', 'drat', 'qsec')])
Langkah 2: Sesuaikan Model Regresi Ridge
Selanjutnya, kita akan menggunakan fungsi glmnet() agar sesuai dengan model regresi Ridge dan menentukan alpha=0 .
Perhatikan bahwa menetapkan alpha sama dengan 1 setara dengan menggunakan regresi Lasso dan menetapkan alpha ke nilai antara 0 dan 1 setara dengan menggunakan jaring elastis.
Perhatikan juga bahwa regresi ridge memerlukan data yang distandarisasi sedemikian rupa sehingga setiap variabel prediktor memiliki rata-rata 0 dan deviasi standar 1.
Untungnya, glmnet() secara otomatis melakukan standardisasi ini untuk Anda. Jika Anda sudah membakukan variabel, Anda dapat menentukan standardize=False .
library (glmnet)
#fit ridge regression model
model <- glmnet(x, y, alpha = 0 )
#view summary of model
summary(model)
Length Class Mode
a0 100 -none- numeric
beta 400 dgCMatrix S4
df 100 -none- numeric
dim 2 -none- numeric
lambda 100 -none- numeric
dev.ratio 100 -none- numeric
nulldev 1 -none- numeric
npasses 1 -none- numeric
jerr 1 -none- numeric
offset 1 -none- logical
call 4 -none- call
nobs 1 -none- numeric
Langkah 3: Pilih nilai optimal untuk Lambda
Selanjutnya kita akan mengidentifikasi nilai lambda yang menghasilkan test mean squared error (MSE) terendah menggunakan k-fold cross-validation .
Untungnya, glmnet memiliki fungsi cv.glmnet() yang secara otomatis melakukan validasi silang k-fold menggunakan k = 10 kali.
#perform k-fold cross-validation to find optimal lambda value
cv_model <- cv. glmnet (x, y, alpha = 0 )
#find optimal lambda value that minimizes test MSE
best_lambda <- cv_model$ lambda . min
best_lambda
[1] 10.04567
#produce plot of test MSE by lambda value
plot(cv_model)
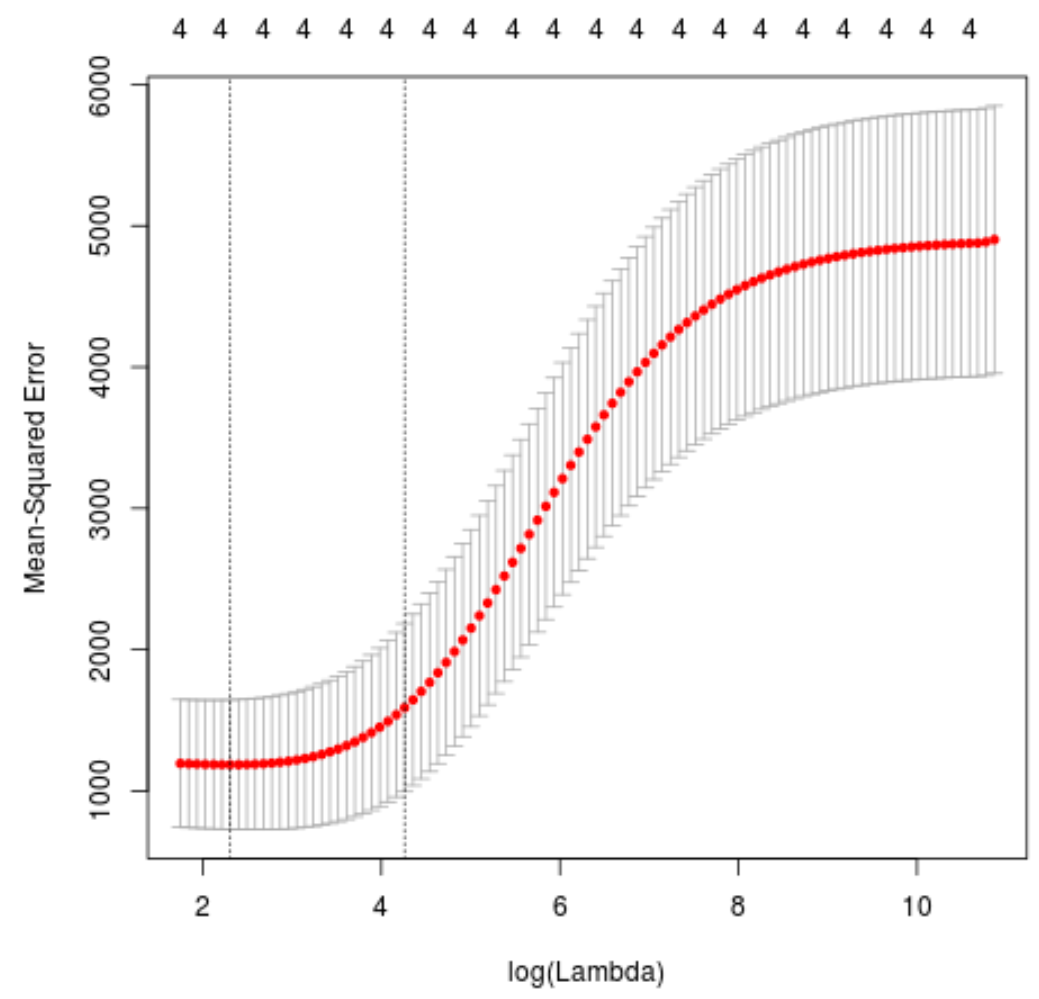
Nilai lambda yang meminimalkan uji MSE ternyata adalah 10.04567 .
Langkah 4: Analisis model akhir
Terakhir, kita dapat menganalisis model akhir yang dihasilkan dengan nilai lambda optimal.
Kita dapat menggunakan kode berikut untuk mendapatkan estimasi koefisien untuk model ini:
#find coefficients of best model
best_model <- glmnet(x, y, alpha = 0 , lambda = best_lambda)
coef(best_model)
5 x 1 sparse Matrix of class "dgCMatrix"
s0
(Intercept) 475.242646
mpg -3.299732
wt 19.431238
drat -1.222429
qsec -17.949721
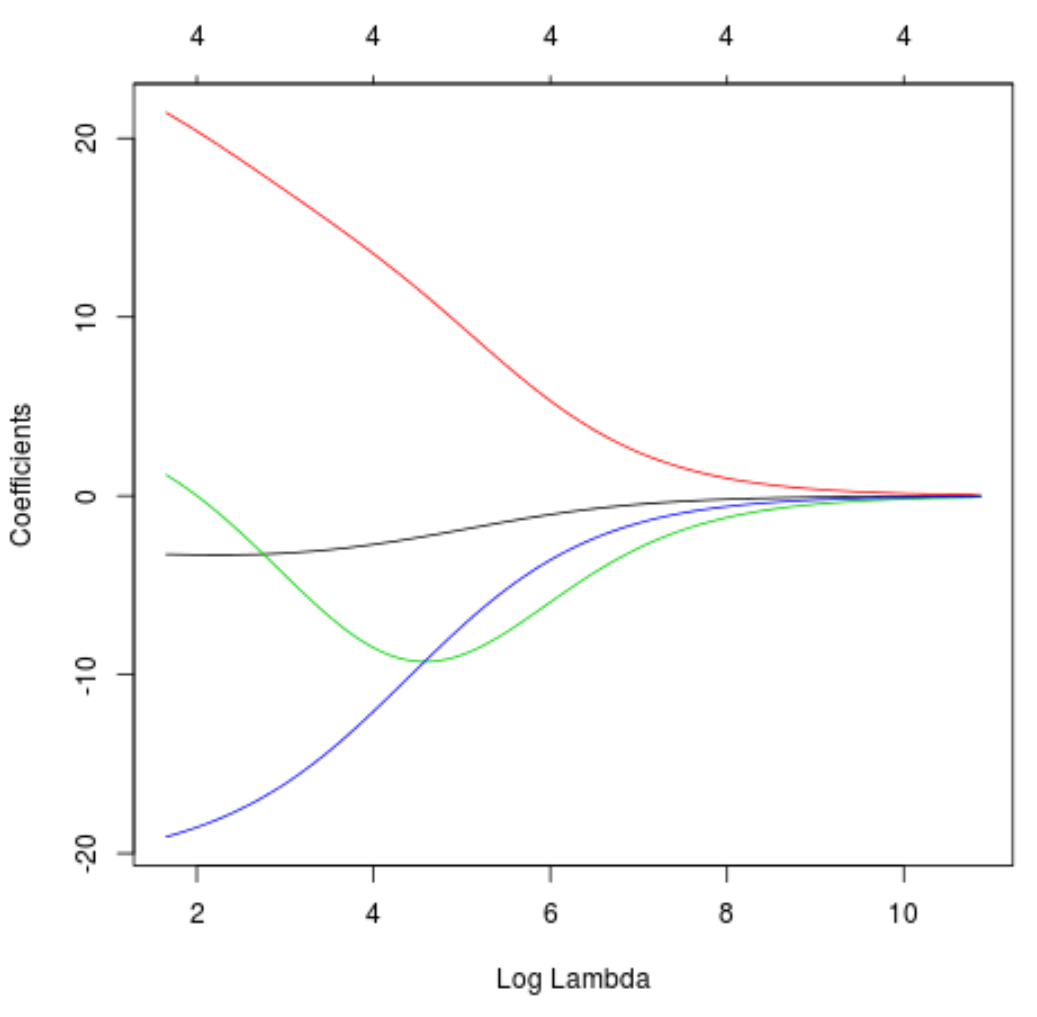
Kami juga dapat membuat plot Trace untuk memvisualisasikan bagaimana estimasi koefisien berubah karena peningkatan lambda:
#produce Ridge trace plot
plot(model, xvar = " lambda ")
Terakhir, kita dapat menghitung R-kuadrat model pada data pelatihan:
#use fitted best model to make predictions
y_predicted <- predict (model, s = best_lambda, newx = x)
#find OHS and SSE
sst <- sum ((y - mean (y))^2)
sse <- sum ((y_predicted - y)^2)
#find R-Squared
rsq <- 1 - sse/sst
rsq
[1] 0.7999513
R kuadratnya ternyata 0,7999513 . Artinya, model terbaik mampu menjelaskan 79,99% variasi nilai respon data pelatihan.
Anda dapat menemukan kode R lengkap yang digunakan dalam contoh ini di sini .
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya