Cara menggunakan variabel dummy dalam analisis regresi
Regresi linier adalah metode yang dapat kita gunakan untuk mengukur hubungan antara satu atau lebih variabel prediktor dan variabel respon .
Kami umumnya menggunakan regresi linier dengan variabel kuantitatif . Kadang-kadang disebut variabel “numerik”, ini adalah variabel yang mewakili kuantitas yang dapat diukur. Contohnya meliputi:
- Jumlah kaki persegi dalam sebuah rumah
- Ukuran populasi suatu kota
- Usia seorang individu
Namun terkadang kita ingin menggunakan variabel kategori sebagai variabel prediktor. Ini adalah variabel yang mempunyai nama atau label dan dapat digolongkan ke dalam kategori. Contohnya meliputi:
- Warna mata (misalnya “biru”, “hijau”, “coklat”)
- Gender (misalnya “pria”, “wanita”)
- Status perkawinan (misalnya “menikah”, “lajang”, “bercerai”)
Saat menggunakan variabel kategori, tidak masuk akal untuk hanya menetapkan nilai seperti 1, 2, 3 ke nilai seperti “biru”, “hijau”, dan “coklat”, karena tidak masuk akal untuk mengatakannya hijau itu ganda. berwarna seperti biru atau coklat tiga kali lebih berwarna daripada biru.
Sebaliknya, solusinya adalah dengan menggunakan variabel dummy . Ini adalah variabel yang kami buat khusus untuk analisis regresi dan mengambil salah satu dari dua nilai: nol atau satu.
Variabel dummy: Variabel numerik yang digunakan dalam analisis regresi untuk mewakili data kategorikal yang hanya dapat mengambil salah satu dari dua nilai: nol atau satu.
Banyaknya variabel dummy yang perlu kita buat sama dengan k -1 dimana k adalah banyaknya nilai berbeda yang dapat diambil oleh variabel kategori.
Contoh berikut mengilustrasikan cara membuat variabel dummy untuk kumpulan data yang berbeda.
Contoh 1: Buat variabel dummy dengan hanya dua nilai
Misalkan kita mempunyai kumpulan data berikut dan ingin menggunakan jenis kelamin dan usia untuk memprediksi pendapatan :
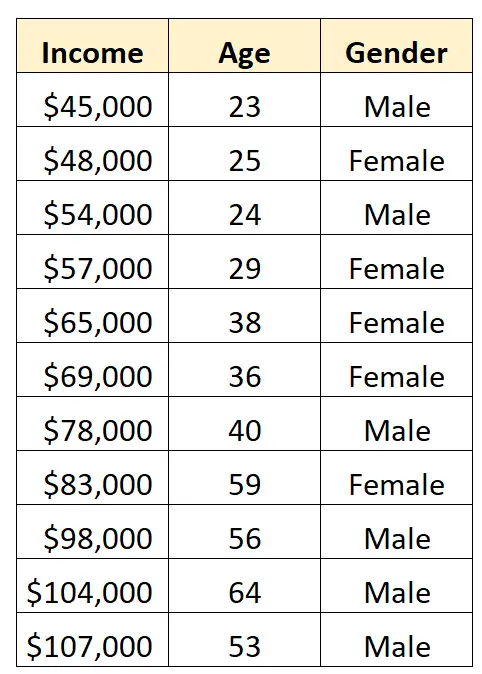
Untuk menggunakan gender sebagai variabel prediktor dalam model regresi, kita perlu mengubahnya menjadi variabel dummy.
Karena ini saat ini merupakan variabel kategori yang dapat mengambil dua nilai berbeda (“Pria” atau “Wanita”), kita cukup membuat k -1 = 2-1 = 1 variabel dummy.
Untuk membuat variabel dummy ini, kita dapat memilih salah satu nilai (“Pria” atau “Wanita”) untuk mewakili 0 dan nilai lainnya untuk mewakili 1.
Secara umum, kami biasanya mewakili nilai yang paling sering muncul dengan angka 0, yaitu “Pria” dalam kumpulan data ini.
Berikut cara mengubah gender menjadi variabel dummy:
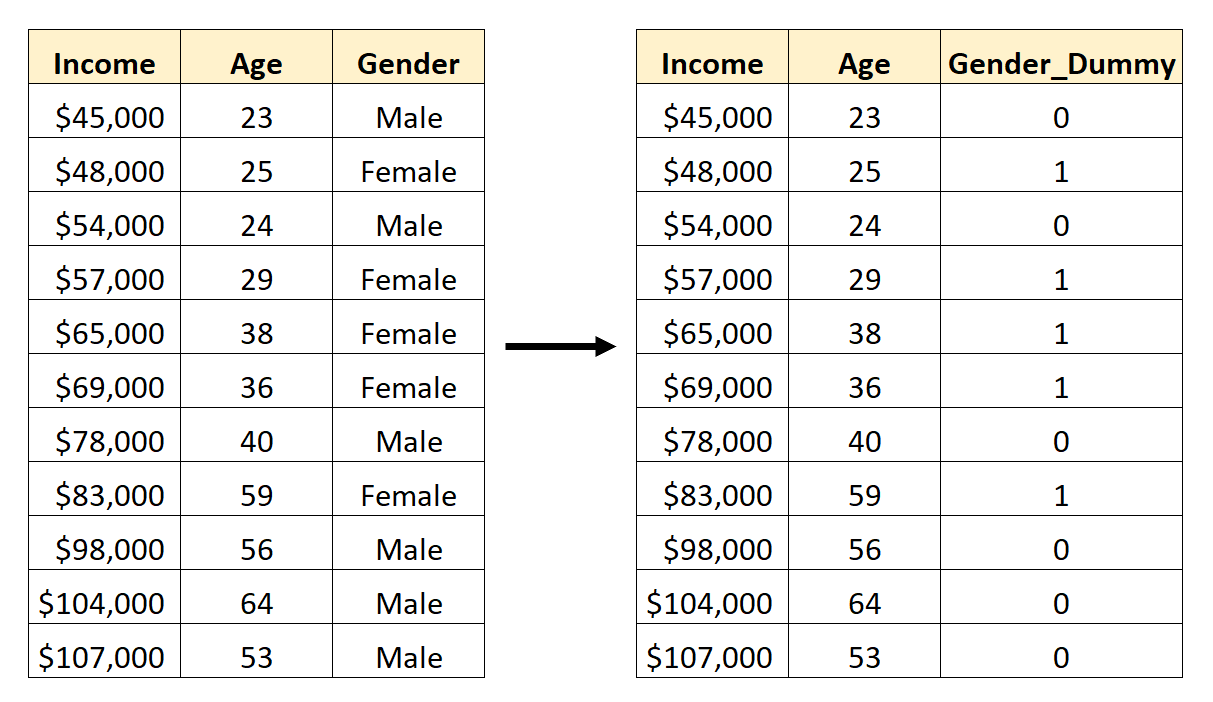
Kami kemudian dapat menggunakan Age dan Gender_Dummy sebagai variabel prediktor dalam model regresi.
Contoh 2: Buat variabel dummy dengan banyak nilai
Katakanlah kita mempunyai kumpulan data berikut dan ingin menggunakan status perkawinan dan usia untuk memprediksi pendapatan :

Untuk menggunakan status perkawinan sebagai variabel prediktor dalam model regresi, kita perlu mengubahnya menjadi variabel dummy.
Karena ini saat ini merupakan variabel kategori yang dapat mengambil tiga nilai berbeda (“Lajang”, “Menikah”, atau “Bercerai”), kita perlu membuat k -1 = 3-1 = 2 variabel tiruan.
Untuk membuat variabel dummy ini, kita dapat membiarkan “Tunggal” sebagai nilai dasar karena variabel ini paling sering muncul. Jadi, inilah cara kami mengubah status perkawinan menjadi variabel dummy:

Kita kemudian dapat menggunakan Usia , Menikah , dan Bercerai sebagai variabel prediktor dalam model regresi.
Bagaimana menginterpretasikan keluaran regresi dengan variabel dummy
Misalkan kita memasang model regresi linier berganda menggunakan kumpulan data dari contoh sebelumnya dengan Usia , Menikah , dan Bercerai sebagai variabel prediktor dan Pendapatan sebagai variabel respons.
Berikut hasil regresinya:
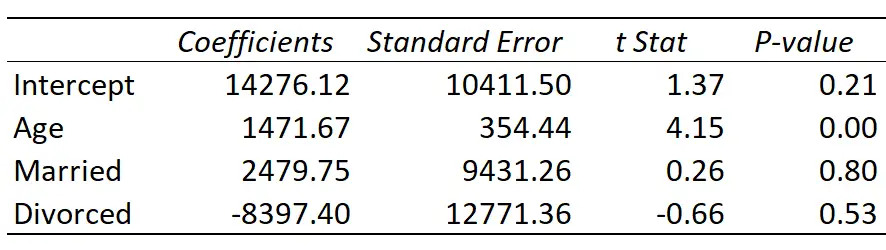
Garis regresi yang dipasang didefinisikan sebagai:
Pendapatan = 14,276.21 + 1,471.67*(Umur) + 2,479.75*(Menikah) – 8,397.40*(Cerai)
Kita dapat menggunakan persamaan ini untuk mengetahui perkiraan pendapatan seseorang berdasarkan usia dan status perkawinannya. Misalnya, seseorang yang berusia 35 tahun dan menikah akan memiliki perkiraan pendapatan sebesar $68,264 :
Pendapatan = 14,276.21 + 1,471.67*(35) + 2,479.75*(1) – 8,397.40*(0) = $68,264
Berikut cara menginterpretasikan koefisien regresi pada tabel:
- Intersep: Intersep mewakili pendapatan rata-rata satu orang berusia nol tahun. Tentu saja Anda tidak bisa mempunyai tahun nol, jadi tidak masuk akal untuk menafsirkan intersep itu sendiri dalam model regresi khusus ini.
- Usia: Setiap peningkatan usia setiap tahun dikaitkan dengan peningkatan pendapatan rata-rata sebesar $1,471,67. Karena nilai p (0,00) kurang dari 0,05, usia merupakan prediktor pendapatan yang signifikan secara statistik.
- Menikah: Orang yang menikah berpenghasilan rata-rata $2,479,75 lebih banyak daripada satu orang. Karena nilai p (0,80) tidak kurang dari 0,05, perbedaan ini tidak signifikan secara statistik.
- Bercerai: Orang yang bercerai berpenghasilan rata-rata $8,397.40 lebih sedikit dari satu orang. Karena nilai p (0,53) tidak kurang dari 0,05, perbedaan ini tidak signifikan secara statistik.
Karena kedua variabel dummy tersebut tidak signifikan secara statistik, kami dapat menghapus status perkawinan sebagai prediktor dari model, karena hal ini tampaknya tidak menambah nilai prediktif terhadap pendapatan.
Sumber daya tambahan
Variabel kualitatif dan kuantitatif
Perangkap variabel tiruan
Cara Membaca dan Menafsirkan Tabel Regresi
Penjelasan tentang nilai P dan signifikansi statistik
Tentang Penulis
Benjamin anderson
Halo, saya Benjamin, pensiunan profesor statistika yang menjadi guru Statorial yang berdedikasi. Dengan pengalaman dan keahlian yang luas di bidang statistika, saya ingin berbagi ilmu untuk memberdayakan mahasiswa melalui Statorials. Baca selengkapnya