Introduzione alla regressione logistica
Quando vogliamo comprendere la relazione tra una o più variabili predittive e una variabile di risposta continua, spesso utilizziamo la regressione lineare .
Tuttavia, quando la variabile di risposta è categoriale, possiamo utilizzare la regressione logistica .
La regressione logistica è un tipo di algoritmo di classificazione perché tenta di “classificare” le osservazioni in un set di dati in categorie distinte.
Ecco alcuni esempi di utilizzo della regressione logistica:
- Vogliamo utilizzare il punteggio di credito e il saldo bancario per prevedere se un determinato cliente andrà in default su un prestito. (Variabile di risposta = “Predefinito” o “Nessun valore predefinito”)
- Vogliamo utilizzare la media dei rimbalzi per partita e la media dei punti per partita per prevedere se un determinato giocatore di basket verrà scelto o meno nell’NBA (variabile di risposta = “Drafted” o “Undrafted”).
- Vogliamo utilizzare la metratura e il numero di bagni per prevedere se una casa in una determinata città sarà quotata o meno a un prezzo di vendita di $ 200.000 o più. (Variabile di risposta = “Sì” o “No”)
Tieni presente che la variabile di risposta in ciascuno di questi esempi può assumere solo uno di due valori. Confrontalo con la regressione lineare in cui la variabile di risposta assume un valore continuo.
L’equazione della regressione logistica
La regressione logistica utilizza un metodo noto come stima di massima verosimiglianza (i dettagli non verranno discussi qui) per trovare un’equazione della forma seguente:
log[p(X) / ( 1 -p(X))] = β 0 + β 1 X 1 + β 2 X 2 + … + β p
Oro:
- X j : la j- esima variabile predittiva
- β j : stima del coefficiente per la j -esima variabile predittiva
La formula sul lato destro dell’equazione prevede le probabilità logaritmiche che la variabile di risposta assuma il valore 1.
Pertanto, quando adattiamo un modello di regressione logistica, possiamo utilizzare la seguente equazione per calcolare la probabilità che una data osservazione assuma il valore 1:
p(X) = eβ 0 + β 1 X 1 + β 2 X 2 + … + β p
Utilizziamo quindi una certa soglia di probabilità per classificare l’osservazione come 1 o 0.
Ad esempio, potremmo dire che le osservazioni con probabilità maggiore o uguale a 0,5 verranno classificate come “1” e tutte le altre osservazioni verranno classificate come “0”.
Come interpretare il risultato della regressione logistica
Supponiamo di utilizzare un modello di regressione logistica per prevedere se un dato giocatore di basket verrà scelto o meno nella NBA in base alla sua media di rimbalzi per partita e ai suoi punti medi per partita.
Ecco il risultato del modello di regressione logistica:
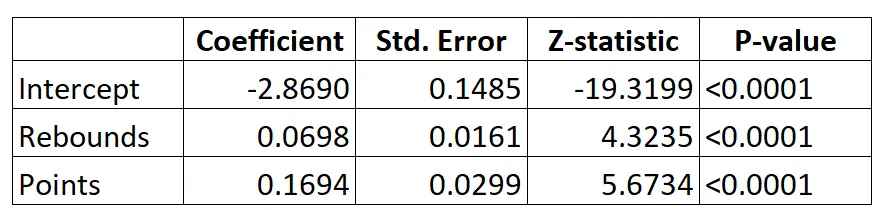
Utilizzando i coefficienti, possiamo calcolare la probabilità che un determinato giocatore venga scelto nella NBA in base alla media dei rimbalzi e dei punti per partita utilizzando la seguente formula:
P(Drafted) = e -2.8690 + 0.0698*(ribs) + 0.1694*(punti) / (1+e -2.8690 + 0.0698*(ribs) + 0.1694*(punti) ) )
Ad esempio, supponiamo che un dato giocatore abbia una media di 8 rimbalzi e 15 punti a partita. Secondo il modello, la probabilità che questo giocatore venga arruolato nella NBA è 0,557 .
P(Scritto) = e -2,8690 + 0,0698*(8) + 0,1694*(15) / (1+e -2,8690 + 0,0698*(8) + 0,1694*(15 ) ) = 0,557
Poiché questa probabilità è maggiore di 0,5, prevediamo che questo giocatore verrà scelto.
Confrontalo con un giocatore che ha una media di solo 3 rimbalzi e 7 punti a partita. La probabilità che questo giocatore venga arruolato nella NBA è 0,186 .
P(Scritto) = e -2,8690 + 0,0698*(3) + 0,1694*(7) / (1+e -2,8690 + 0,0698*(3) + 0,1694*(7 ) ) = 0,186
Poiché questa probabilità è inferiore a 0,5, prevediamo che questo giocatore non verrà scelto.
Ipotesi di regressione logistica
La regressione logistica utilizza le seguenti ipotesi:
1. La variabile di risposta è binaria. Si presuppone che la variabile di risposta possa assumere solo due possibili risultati.
2. Le osservazioni sono indipendenti. Si presuppone che le osservazioni nel set di dati siano indipendenti l’una dall’altra. Cioè, le osservazioni non dovrebbero provenire da misurazioni ripetute dello stesso individuo o essere correlate tra loro in alcun modo.
3. Non esiste una seria multicollinearità tra le variabili predittive . Si presuppone che nessuna delle variabili predittive sia altamente correlata tra loro.
4. Non ci sono valori anomali estremi. Si presuppone che nel set di dati non siano presenti valori anomali estremi o osservazioni influenti.
5. Esiste una relazione lineare tra le variabili predittive e il logit della variabile di risposta . Questa ipotesi può essere verificata utilizzando il test di Box-Tidwell.
6. La dimensione del campione è sufficientemente ampia. In genere, dovresti avere un minimo di 10 casi con l’esito meno frequente per ciascuna variabile esplicativa. Ad esempio, se hai 3 variabili esplicative e la probabilità prevista del risultato meno frequente è 0,20, allora dovresti avere una dimensione del campione di almeno (10*3) / 0,20 = 150.
Consulta questo articolo per una spiegazione dettagliata su come verificare queste ipotesi.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più