Un'introduzione alla regressione polinomiale
Quando disponiamo di un set di dati con una variabile predittrice e una variabile di risposta , spesso utilizziamo la regressione lineare semplice per quantificare la relazione tra le due variabili.
Tuttavia, la regressione lineare semplice (SLR) presuppone che la relazione tra il predittore e la variabile di risposta sia lineare. Scritto in notazione matematica, SLR presuppone che la relazione assuma la forma:
Y = β 0 + β 1 X + ε
Ma in pratica, la relazione tra le due variabili potrebbe effettivamente essere non lineare e il tentativo di utilizzare la regressione lineare potrebbe risultare in un modello poco appropriato.
Un modo per tenere conto di una relazione non lineare tra il predittore e la variabile di risposta è utilizzare la regressione polinomiale , che assume la forma:
Y = β 0 + β 1 X + β 2 X 2 + … + β h
In questa equazione h è chiamato grado del polinomio.
Aumentando il valore di h , il modello è in grado di adattarsi meglio alle relazioni non lineari, ma in pratica raramente scegliamo che h sia maggiore di 3 o 4. Oltre questo punto il modello diventa troppo flessibile e si adatta eccessivamente ai dati .
Note tecniche
- Sebbene la regressione polinomiale possa adattarsi a dati non lineari, è comunque considerata una forma di regressione lineare perché è lineare nei coefficienti β1 , β2 , …, βh .
- La regressione polinomiale può essere utilizzata anche per più variabili predittive, ma ciò crea termini di interazione nel modello, che possono rendere il modello estremamente complesso se vengono utilizzate più variabili predittive.
Quando utilizzare la regressione polinomiale
Usiamo la regressione polinomiale quando la relazione tra un predittore e una variabile di risposta non è lineare.
Esistono tre modi comuni per rilevare una relazione non lineare:
1. Crea un grafico a dispersione.
Il modo più semplice per rilevare una relazione non lineare è creare un grafico a dispersione della variabile di risposta rispetto alla variabile predittore.
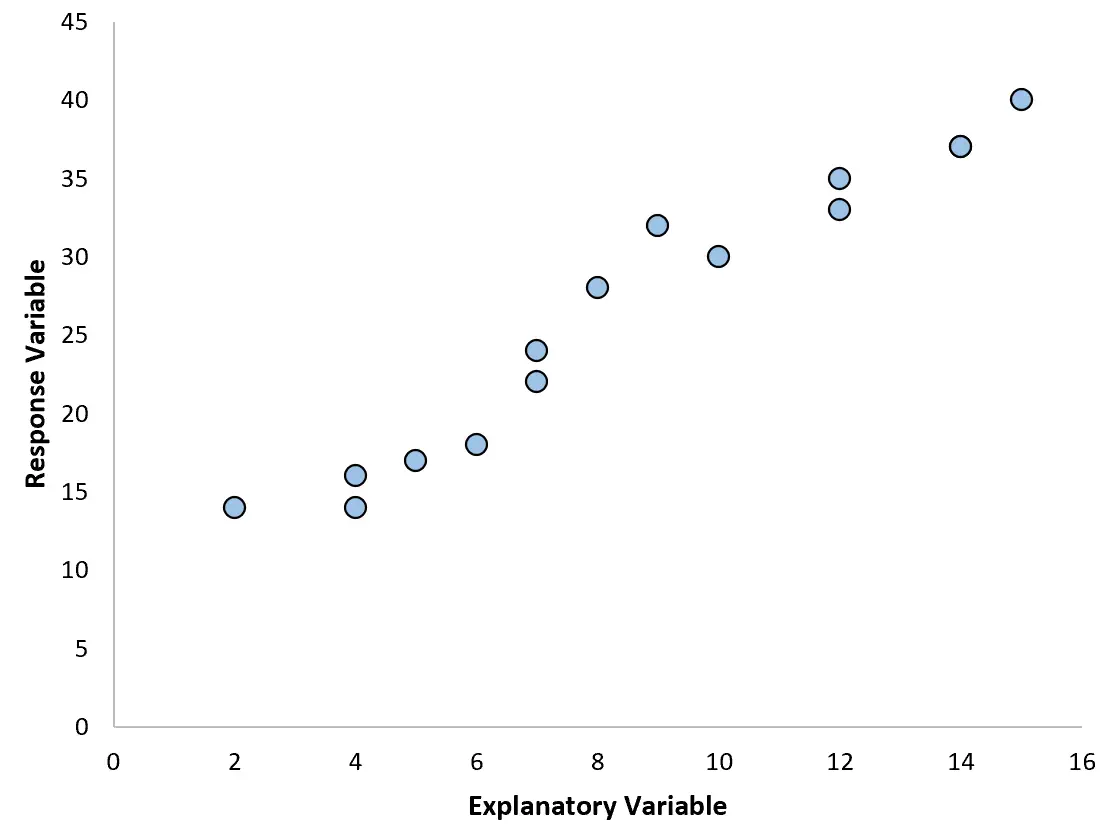
Ad esempio, se creiamo il seguente grafico a dispersione, possiamo vedere che la relazione tra le due variabili è approssimativamente lineare, quindi una semplice regressione lineare probabilmente funzionerebbe bene su questi dati.
Tuttavia, se il nostro grafico a dispersione assomiglia a uno dei seguenti grafici, potremmo vedere che la relazione non è lineare e quindi una regressione polinomiale sarebbe una buona idea:
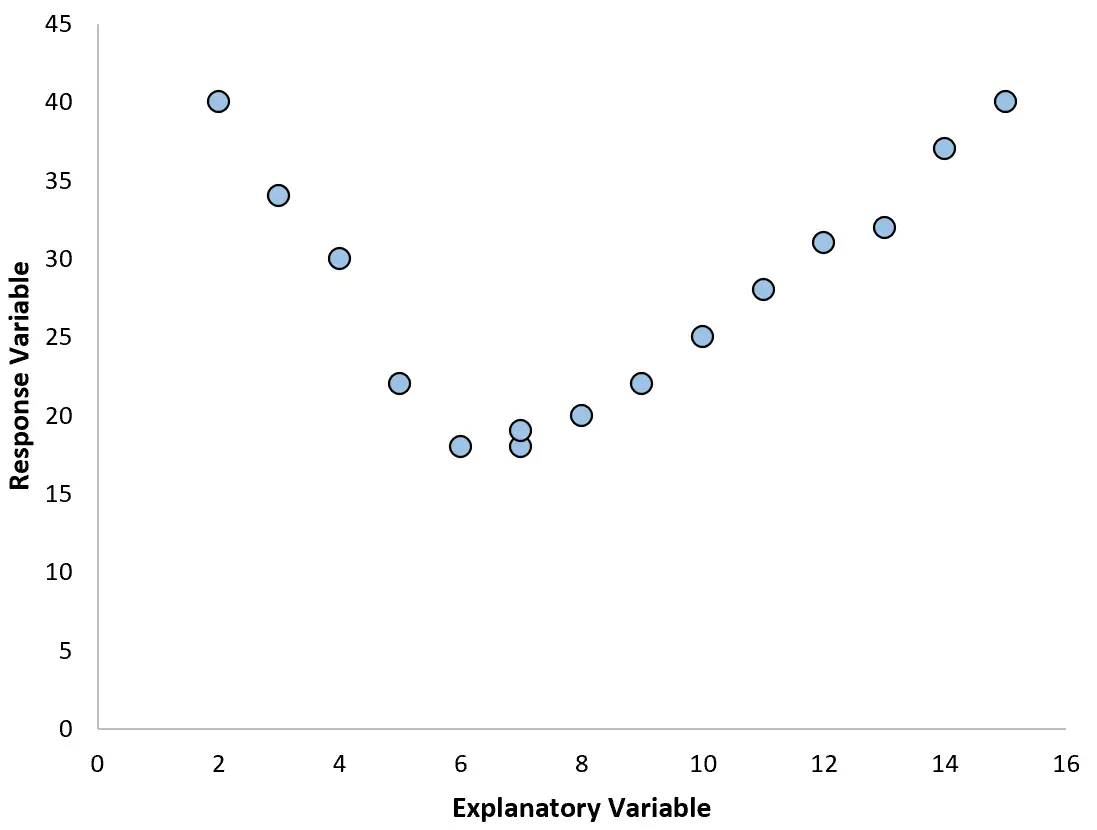
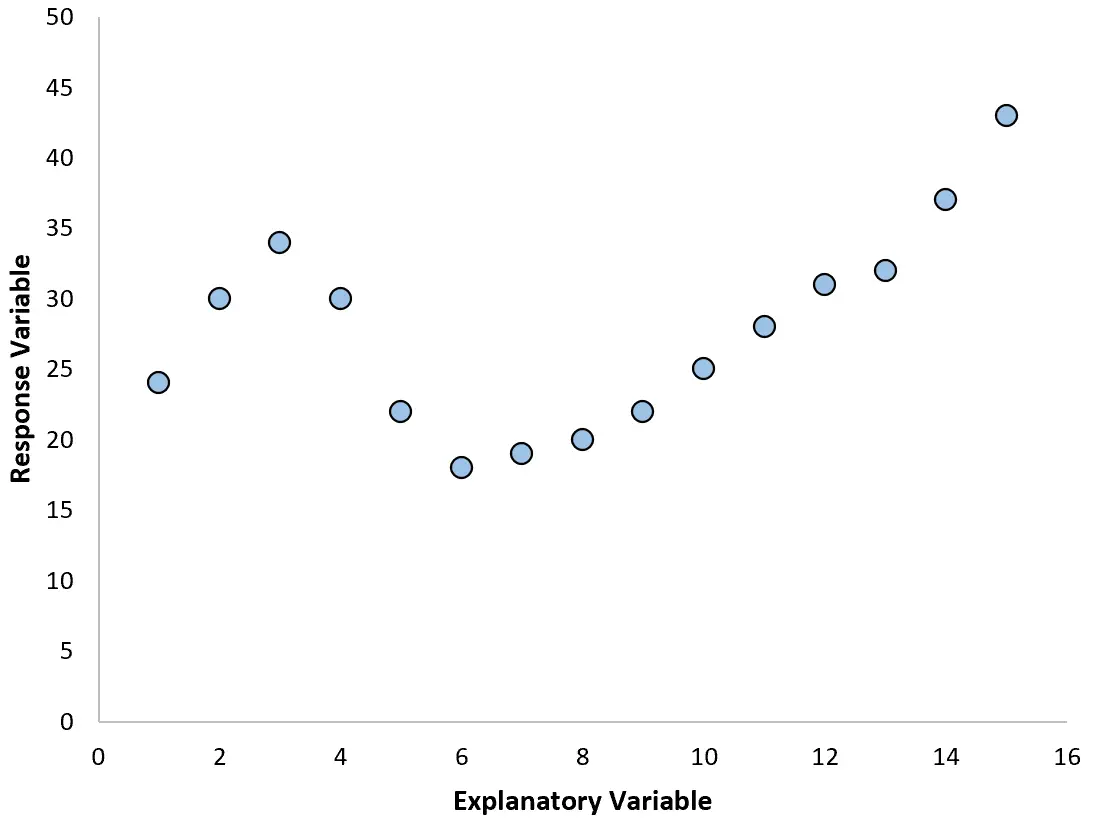
2. Creare un grafico dei residui rispetto al grafico adattato.
Un altro modo per rilevare la non linearità è adattare ai dati un semplice modello di regressione lineare e quindi produrre un grafico dei residui rispetto ai valori adattati .
Se i residui del grafico sono distribuiti in modo approssimativamente uniforme attorno allo zero senza una tendenza chiara, probabilmente è sufficiente una semplice regressione lineare.
Tuttavia, se i residui mostrano una tendenza non lineare nel grafico, ciò indica che la relazione tra il predittore e la risposta è probabilmente non lineare.
3. Calcolare la R 2 del modello.
Il valore R2 di un modello di regressione indica la percentuale di variazione nella variabile di risposta che può essere spiegata dalle variabili predittive.
Se si adatta un modello di regressione lineare semplice a un set di dati e il valore R2 del modello è piuttosto basso, ciò potrebbe indicare che la relazione tra il predittore e la variabile di risposta è più complessa di una semplice relazione lineare.
Questo potrebbe essere un segno che potresti dover provare invece la regressione polinomiale.
Correlato: Qual è un buon valore R quadrato?
Come scegliere il grado del polinomio
Un modello di regressione polinomiale assume la forma seguente:
Y = β 0 + β 1 X + β 2 X 2 + … + β h
In questa equazione, h è il grado del polinomio.
Ma come scegliere un valore per h ?
In pratica, adattiamo diversi modelli diversi con diversi valori di h ed eseguiamo una convalida incrociata k-fold per determinare quale modello produce l’errore quadratico medio del test (MSE) più basso.
Ad esempio, possiamo adattare i seguenti modelli a un determinato set di dati:
- Y = β0 + β1
- Y = β 0 + β 1 X + β 2 X 2
- Y = β0 + β1X + β2X2 + β3X3
- Y = β 0 + β 1 X + β 2 X 2 + β 3 X 3 + β 4 X 4
Possiamo quindi utilizzare la convalida incrociata k-fold per calcolare il test MSE per ciascun modello, che ci dirà quanto bene ciascun modello si comporta su dati mai visti prima.
Il compromesso bias-varianza della regressione polinomiale
Esiste un compromesso tra bias e varianza quando si utilizza la regressione polinomiale. Aumentando il grado del polinomio, la distorsione diminuisce (poiché il modello diventa più flessibile) ma la varianza aumenta.
Come per tutti i modelli di machine learning, dobbiamo trovare un compromesso ottimale tra bias e varianza.
Nella maggior parte dei casi ciò consente di aumentare in una certa misura il grado del polinomio, ma oltre un certo valore il modello inizia ad adattarsi al rumore nei dati e l’MSE del test inizia a diminuire.
Per garantire di adattare un modello flessibile ma non troppo flessibile, utilizziamo la convalida incrociata k-fold per trovare il modello che produce il test MSE più basso.
Come eseguire la regressione polinomiale
I seguenti tutorial forniscono esempi di come eseguire la regressione polinomiale in diversi software:
Come eseguire la regressione polinomiale in Excel
Come eseguire la regressione polinomiale in R
Come eseguire la regressione polinomiale in Python
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più