Le cinque ipotesi della regressione lineare multipla
La regressione lineare multipla è un metodo statistico che possiamo utilizzare per comprendere la relazione tra più variabili predittive e una variabile di risposta .
Tuttavia, prima di eseguire la regressione lineare multipla, dobbiamo prima assicurarci che siano soddisfatte cinque ipotesi:
1. Relazione lineare: esiste una relazione lineare tra ciascuna variabile predittrice e la variabile di risposta.
2. Nessuna multicollinearità: nessuna delle variabili predittive è altamente correlata tra loro.
3. Indipendenza: le osservazioni sono indipendenti.
4. Omoschedasticità: i residui hanno una varianza costante in ogni punto del modello lineare.
5. Normalità multivariata: i residui del modello sono distribuiti normalmente.
Se una o più di queste ipotesi non vengono soddisfatte, i risultati della regressione lineare multipla potrebbero non essere affidabili.
In questo articolo forniamo una spiegazione per ciascun presupposto, come determinare se il presupposto è soddisfatto e cosa fare se il presupposto non è soddisfatto.
Ipotesi 1: relazione lineare
La regressione lineare multipla presuppone che esista una relazione lineare tra ciascuna variabile predittrice e la variabile di risposta.
Come determinare se questo presupposto è soddisfatto
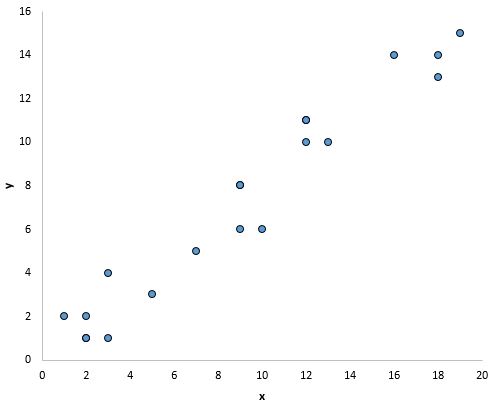
Il modo più semplice per determinare se questo presupposto è soddisfatto è creare un grafico a dispersione di ciascuna variabile predittore e della variabile di risposta.
Ciò consente di vedere visivamente se esiste una relazione lineare tra le due variabili.
Se i punti nel grafico a dispersione si trovano approssimativamente lungo una linea diagonale retta, è probabile che esista una relazione lineare tra le variabili.
Ad esempio, i punti nel grafico seguente sembrano cadere su una linea retta, indicando che esiste una relazione lineare tra questa particolare variabile predittrice (x) e la variabile di risposta (y):
Cosa fare se questo presupposto non viene rispettato
Se non esiste una relazione lineare tra una o più variabili predittive e la variabile di risposta, allora abbiamo diverse opzioni:
1. Applicare una trasformazione non lineare alla variabile predittore, ad esempio prendendo il logaritmo o la radice quadrata. Questo spesso può trasformare la relazione in una relazione più lineare.
2. Aggiungere un’altra variabile predittiva al modello. Ad esempio, se il grafico di x rispetto a y ha una forma parabolica, potrebbe avere senso aggiungere X 2 come variabile predittiva aggiuntiva nel modello.
3. Rimuovere la variabile predittore dal modello. Nel caso più estremo, se non esiste una relazione lineare tra una determinata variabile predittiva e la variabile di risposta, potrebbe non essere utile includere la variabile predittiva nel modello.
Ipotesi 2: nessuna multicollinearità
La regressione lineare multipla presuppone che nessuna delle variabili predittive sia altamente correlata tra loro.
Quando una o più variabili predittive sono altamente correlate, il modello di regressione soffre di multicollinearità , rendendo inaffidabili le stime dei coefficienti del modello.
Come determinare se questo presupposto è soddisfatto
Il modo più semplice per determinare se questo presupposto è soddisfatto è calcolare il valore VIF per ciascuna variabile predittrice.
I valori VIF iniziano da 1 e non hanno un limite superiore. Generalmente, valori VIF superiori a 5* indicano una potenziale multicollinearità.
I seguenti tutorial mostrano come calcolare il VIF in vari software statistici:
*A volte i ricercatori utilizzano invece un valore VIF pari a 10, a seconda del campo di studio.
Cosa fare se questo presupposto non viene rispettato
Se una o più variabili predittore hanno un valore VIF maggiore di 5, il modo più semplice per risolvere questo problema consiste nel rimuovere semplicemente le variabili predittore con i valori VIF elevati.
In alternativa, se si desidera mantenere ciascuna variabile predittore nel modello, è possibile utilizzare un metodo statistico diverso, ad esempio la regressione ridge , la regressione lazo o la regressione parziale dei minimi quadrati , progettato per gestire variabili predittive altamente correlate.
Ipotesi 3: Indipendenza
La regressione lineare multipla presuppone che ciascuna osservazione nel set di dati sia indipendente.
Come determinare se questo presupposto è soddisfatto
Il modo più semplice per determinare se questa ipotesi è soddisfatta è eseguire un test di Durbin-Watson , che è un test statistico formale che ci dice se i residui (e quindi le osservazioni) presentano o meno autocorrelazione.
Cosa fare se questo presupposto non viene rispettato
A seconda di come viene violato questo presupposto, hai diverse opzioni:
- Per una correlazione seriale positiva, prendere in considerazione l’aggiunta di ritardi della variabile dipendente e/o indipendente al modello.
- Per la correlazione seriale negativa, assicurati che nessuna delle variabili abbia un ritardo eccessivo .
- Per la correlazione stagionale, prendere in considerazione l’aggiunta di dummy stagionali al modello.
Ipotesi 4: omoschedasticità
La regressione lineare multipla presuppone che i residui abbiano una varianza costante in ogni punto del modello lineare. Quando questo non è il caso, i residui soffrono di eteroschedasticità .
Quando l’eteroschedasticità è presente in un’analisi di regressione, i risultati del modello di regressione diventano inaffidabili.
Nello specifico, l’eteroschedasticità aumenta la varianza delle stime dei coefficienti di regressione, ma il modello di regressione non ne tiene conto. Ciò rende molto più probabile che un modello di regressione affermi che un termine nel modello è statisticamente significativo, quando in realtà non lo è.
Come determinare se questo presupposto è soddisfatto
Il modo più semplice per determinare se questo presupposto è soddisfatto è creare un grafico dei residui standardizzati rispetto ai valori previsti.
Dopo aver adattato un modello di regressione a un set di dati, è possibile creare un grafico a dispersione che visualizza i valori previsti della variabile di risposta sull’asse x e i residui standardizzati del modello sull’asse x. sì.
Se i punti nel grafico a dispersione mostrano una tendenza, allora è presente eteroschedasticità.
Il grafico seguente mostra un esempio di modello di regressione in cui l’eteroschedasticità non è un problema:
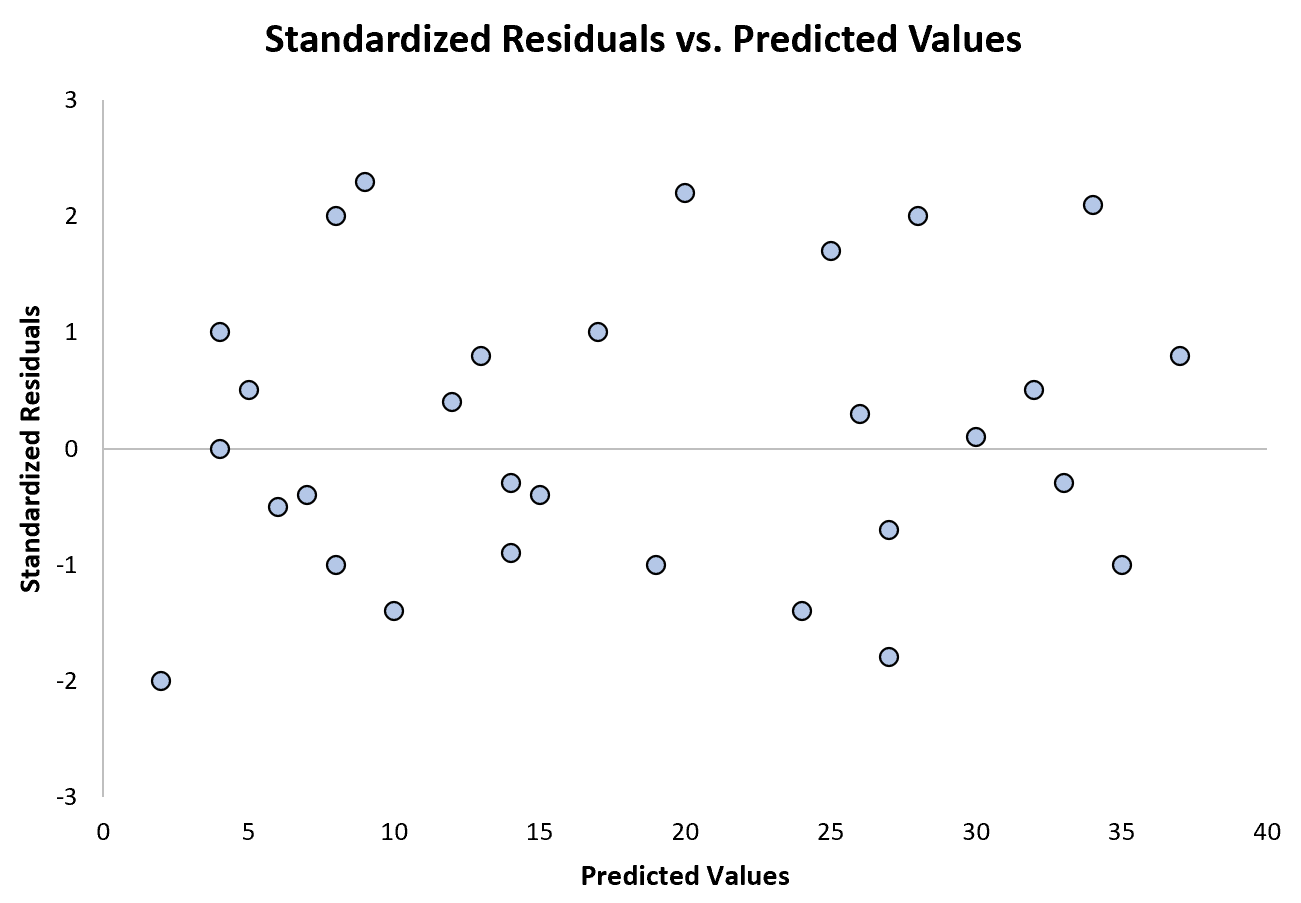
Si noti che i residui standardizzati sono sparsi attorno allo zero senza uno schema chiaro.
Il grafico seguente mostra un esempio di modello di regressione in cui l’eteroschedasticità è un problema:
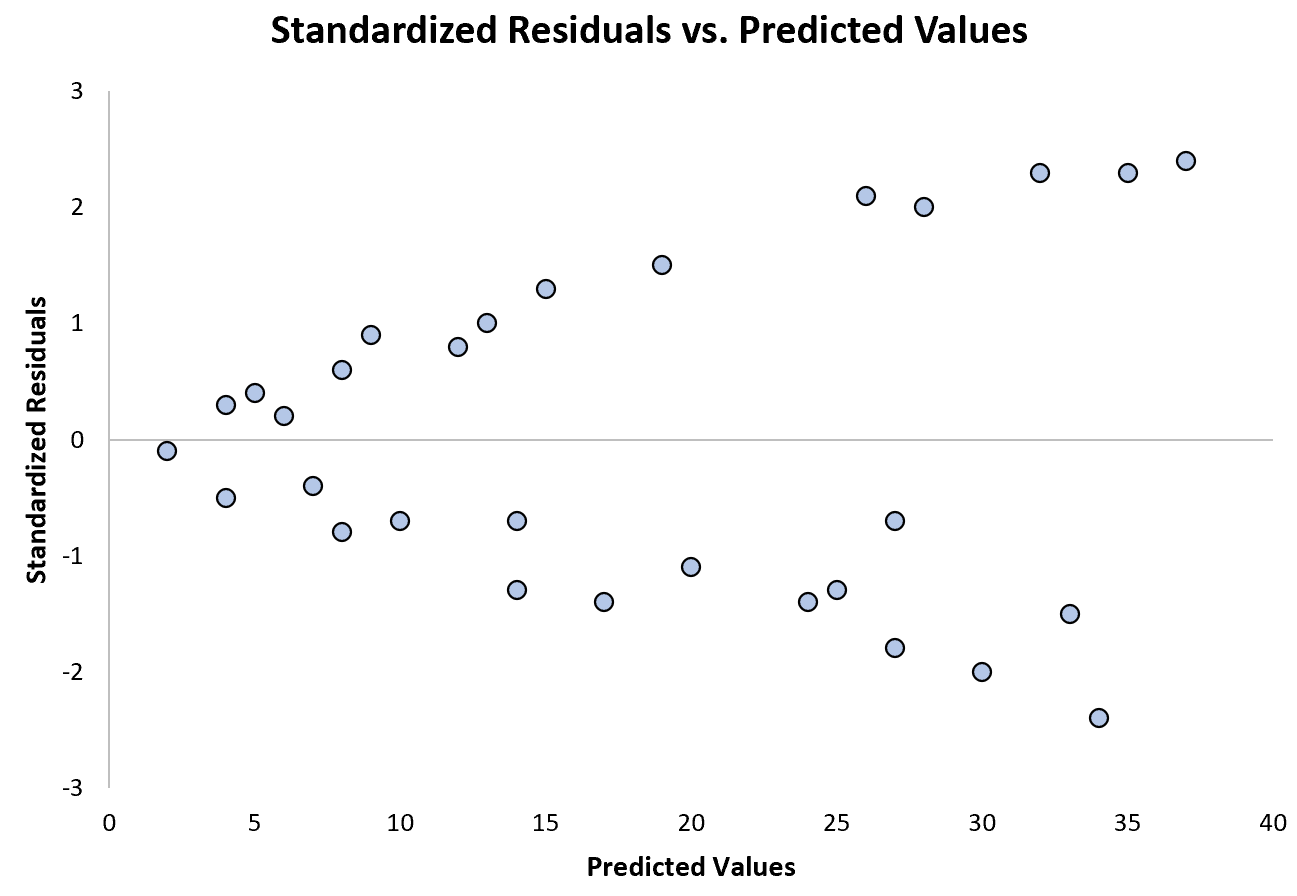
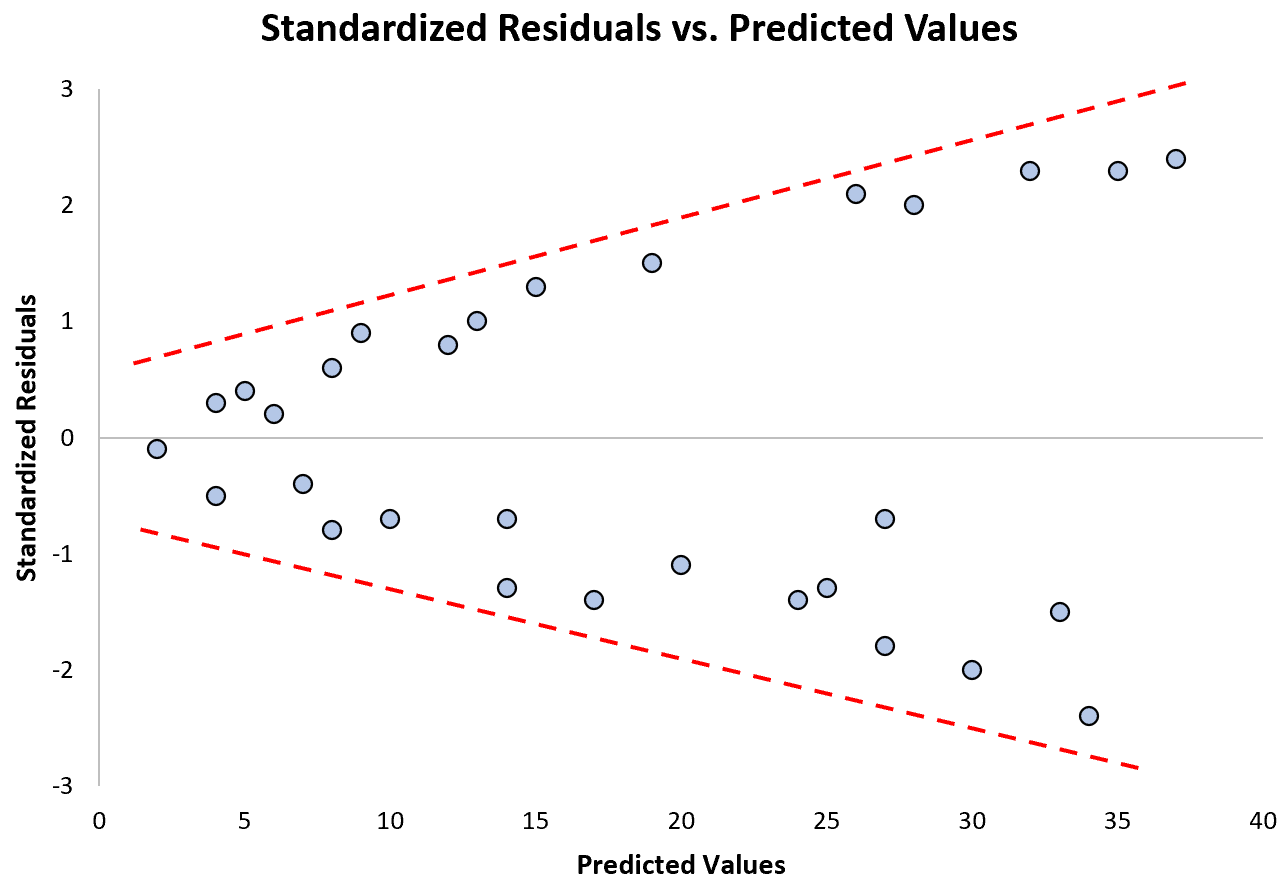
Si noti come i residui standardizzati si diffondono sempre di più all’aumentare dei valori previsti. Questa forma a “cono” è un classico segno di eteroschedasticità:
Cosa fare se questo presupposto non viene rispettato
Esistono tre modi comuni per correggere l’eteroschedasticità:
1. Trasformare la variabile di risposta. Il modo più comune per gestire l’eteroschedasticità è trasformare la variabile di risposta prendendo il logaritmo, la radice quadrata o la radice cubica di tutti i valori della variabile di risposta. Ciò spesso si traduce nella scomparsa dell’eteroschedasticità.
2. Ridefinire la variabile di risposta. Un modo per ridefinire la variabile di risposta è utilizzare un tasso anziché il valore grezzo. Ad esempio, invece di utilizzare la dimensione della popolazione per prevedere il numero di fioristi in una città, possiamo utilizzare la dimensione della popolazione per prevedere il numero di fioristi pro capite.
Nella maggior parte dei casi, ciò riduce la variabilità che si verifica naturalmente all’interno di popolazioni più grandi poiché misuriamo il numero di fioristi per persona, piuttosto che il numero di fioristi stessi.
3. Utilizzare la regressione ponderata. Un altro modo per correggere l’eteroschedasticità consiste nell’utilizzare la regressione ponderata, che assegna un peso a ciascun punto dati in base alla varianza del relativo valore adattato.
In sostanza, ciò attribuisce pesi bassi ai punti dati che presentano varianze più elevate, riducendo i loro quadrati residui. Quando vengono utilizzati i pesi appropriati, ciò può eliminare il problema dell’eteroschedasticità.
Correlati : Come eseguire la regressione ponderata in R
Presupposto 4: normalità multivariata
La regressione lineare multipla presuppone che i residui del modello siano distribuiti normalmente.
Come determinare se questo presupposto è soddisfatto
Esistono due modi comuni per verificare se questa ipotesi è soddisfatta:
1. Verificare visivamente l’ipotesi utilizzando i grafici QQ .
Un grafico QQ, abbreviazione di grafico quantile-quantile, è un tipo di grafico che possiamo utilizzare per determinare se i residui di un modello seguono o meno una distribuzione normale. Se i punti sul grafico formano approssimativamente una linea diagonale retta, il presupposto di normalità è soddisfatto.
Il seguente grafico QQ mostra un esempio di residui che seguono approssimativamente una distribuzione normale:
Tuttavia, il grafico QQ riportato di seguito mostra un esempio di un caso in cui i residui deviano chiaramente da una linea diagonale retta, indicando che non seguono la distribuzione normale:
2. Verificare l’ipotesi utilizzando un test statistico formale come Shapiro-Wilk, Kolmogorov-Smironov, Jarque-Barre o D’Agostino-Pearson.
Tieni presente che questi test sono sensibili alle dimensioni del campione di grandi dimensioni, ovvero spesso concludono che i residui non sono normali quando la dimensione del campione è estremamente ampia. Questo è il motivo per cui spesso è più semplice utilizzare metodi grafici come un grafico QQ per verificare questa ipotesi.
Cosa fare se questo presupposto non viene rispettato
Se il presupposto di normalità non viene soddisfatto, hai diverse opzioni:
1. Innanzitutto, verificare che nei dati non siano presenti valori anomali estremi che comportino una violazione del presupposto di normalità.
2. Successivamente è possibile applicare una trasformazione non lineare alla variabile di risposta, ad esempio prendendo la radice quadrata, il logaritmo o la radice cubica di tutti i valori della variabile di risposta. Ciò spesso si traduce in una distribuzione più normale dei residui del modello.
Risorse addizionali
Le esercitazioni seguenti forniscono informazioni aggiuntive sulla regressione lineare multipla e sui relativi presupposti:
Introduzione alla regressione lineare multipla
Una guida all’eteroschedasticità nell’analisi di regressione
Una guida alla multicollinearità e al VIF nella regressione
I seguenti tutorial forniscono esempi passo passo su come eseguire una regressione lineare multipla utilizzando diversi software statistici:
Come eseguire una regressione lineare multipla in Excel
Come eseguire la regressione lineare multipla in R
Come eseguire la regressione lineare multipla in SPSS
Come eseguire la regressione lineare multipla in Stata
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più