Come utilizzare gli errori standard robusti nella regressione in stata
La regressione lineare multipla è un metodo che possiamo utilizzare per comprendere la relazione tra più variabili esplicative e una variabile di risposta.
Sfortunatamente, un problema che spesso si verifica nella regressione è noto come eteroschedasticità , in cui si verifica un cambiamento sistematico nella varianza dei residui su un intervallo di valori misurati.
Ciò porta ad un aumento della varianza delle stime dei coefficienti di regressione, ma il modello di regressione non ne tiene conto. Ciò rende molto più probabile che un modello di regressione affermi che un termine nel modello è statisticamente significativo, quando in realtà non lo è.
Un modo per tenere conto di questo problema è utilizzare errori standard robusti , che sono più “robusti” rispetto al problema dell’eteroschedasticità e tendono a fornire una misura più accurata del vero errore standard di un coefficiente di regressione.
Questo tutorial spiega come utilizzare gli errori standard robusti nell’analisi di regressione in Stata.
Esempio: errori standard robusti in Stata
Utilizzeremo il set di dati Stata integrato automaticamente per illustrare come utilizzare gli errori standard robusti nella regressione.
Passaggio 1: caricare e visualizzare i dati.
Innanzitutto, utilizza il seguente comando per caricare i dati:
utilizzo automatico del sistema
Quindi visualizzare i dati grezzi utilizzando il seguente comando:
fratello
Passaggio 2: eseguire una regressione lineare multipla senza errori standard robusti.
Successivamente, inseriremo il seguente comando per eseguire una regressione lineare multipla utilizzando il prezzo come variabile di risposta e mpg e peso come variabili esplicative:
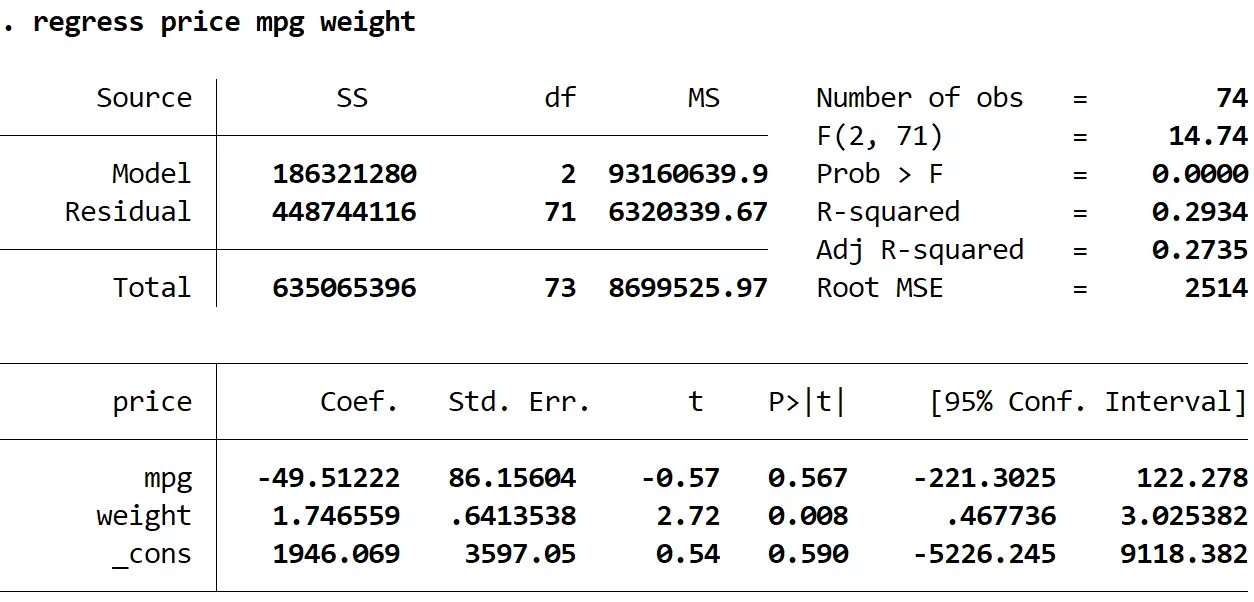
prezzo di regressione peso mpg
Passaggio 3: eseguire una regressione lineare multipla utilizzando errori standard robusti.
Ora eseguiremo la stessa identica regressione lineare multipla, ma questa volta utilizzeremo il comando vce(robust) in modo che Stata sappia come utilizzare errori standard robusti:
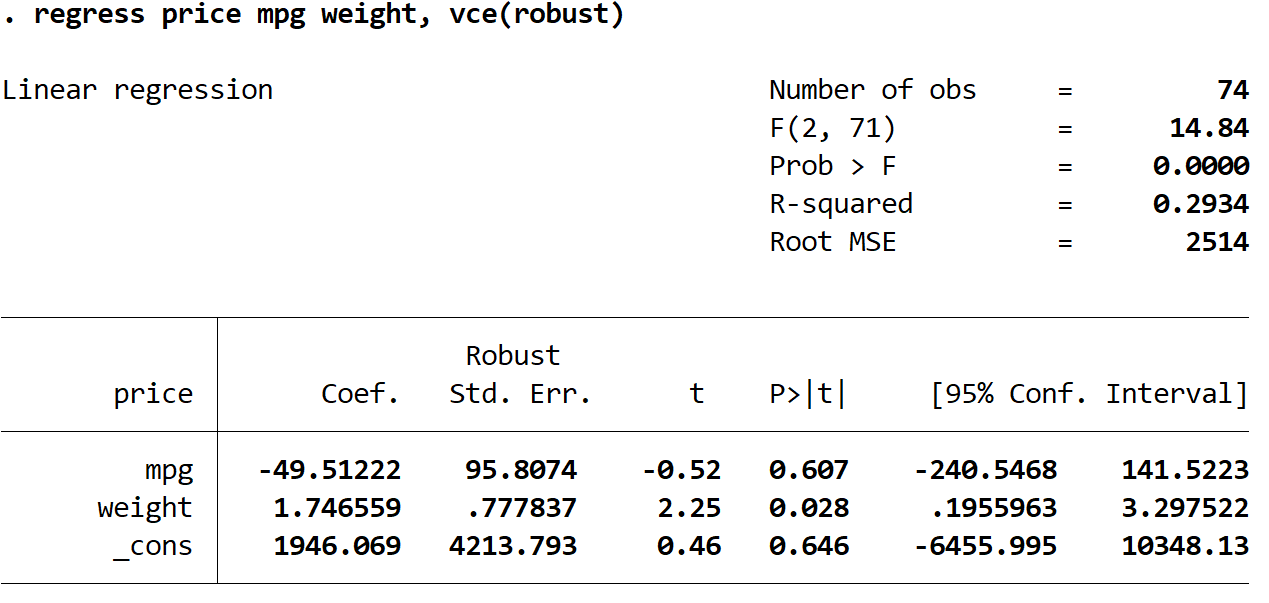
prezzo di regressione mpg peso, vce (robusto)
Ci sono alcune cose interessanti da notare qui:
1. Le stime dei coefficienti sono rimaste le stesse . Quando utilizziamo errori standard robusti, le stime dei coefficienti non cambiano affatto. Si noti che le stime dei coefficienti per mpg, peso e costante sono le seguenti per entrambe le regressioni:
- mpg: -49.51222
- peso: 1,746559
- _contro: 1946.069
2. Gli errori standard sono cambiati . Si noti che quando abbiamo utilizzato errori standard robusti, gli errori standard per ciascuna stima dei coefficienti sono aumentati.
Nota: nella maggior parte dei casi, gli errori standard robusti saranno maggiori degli errori standard normali, ma in rari casi è possibile che gli errori standard robusti siano effettivamente inferiori.
3. La statistica del test di ciascun coefficiente è cambiata. Si noti che il valore assoluto di ciascuna statistica del test , t , è diminuito. In effetti, la statistica del test viene calcolata come il coefficiente stimato diviso per l’errore standard. Pertanto, maggiore è l’errore standard, minore è il valore assoluto della statistica del test.
4. I valori p sono cambiati . Si noti che anche i valori p per ciascuna variabile sono aumentati. Questo perché statistiche di test più piccole sono associate a valori p più grandi.
Sebbene i valori p siano cambiati per i nostri coefficienti, la variabile mpg non è ancora statisticamente significativa con α = 0,05 e il peso della variabile è ancora statisticamente significativo con α = 0,05.
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più