Cos’è l’affidabilità tra valutatori? (definizione & #038; esempio)
Nelle statistiche, l’affidabilità tra valutatori è un modo per misurare il livello di accordo tra più valutatori o giudici.
Viene utilizzato per valutare l’affidabilità delle risposte prodotte da diversi elementi in un test. Se un test ha un’affidabilità inter-valutatore inferiore, potrebbe indicare che gli elementi del test sono confusi, poco chiari o addirittura inutili.
Esistono due modi comuni per misurare l’affidabilità tra valutatori:
1. Percentuale di accordo
Il modo più semplice per misurare l’affidabilità tra valutatori è calcolare la percentuale di elementi su cui i giudici concordano.
Questo è chiamato accordo percentuale , che è sempre compreso tra 0 e 1, dove 0 indica assenza di accordo tra i valutatori e 1 indica perfetto accordo tra i valutatori.
Ad esempio, supponiamo che a due giudici venga chiesto di valutare la difficoltà di 10 elementi di un test su una scala da 1 a 3. I risultati sono mostrati di seguito:
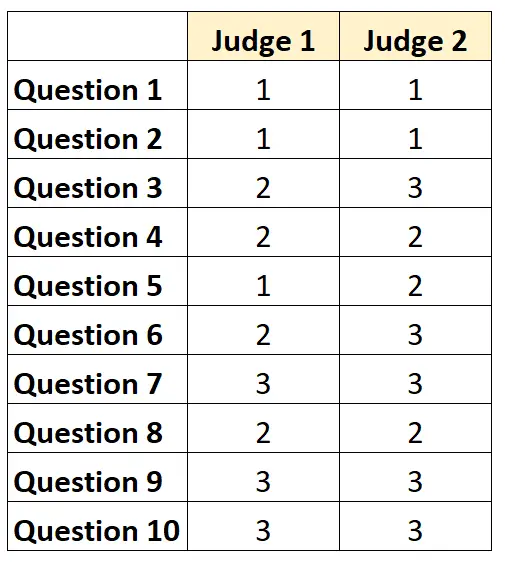
Per ogni domanda possiamo scrivere “1” se entrambi i giudici sono d’accordo e “0” se non sono d’accordo.
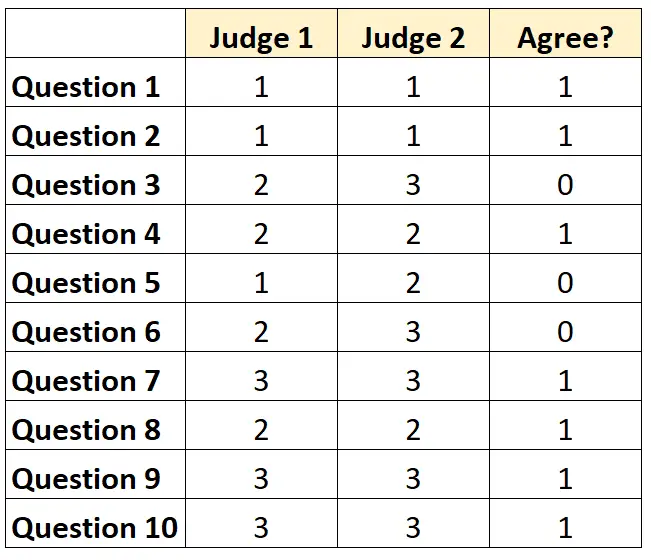
La percentuale di domande su cui i giudici si sono accordati è stata di 7/10 = 70% .
2. Kappa di Cohen
Il modo più difficile (e più rigoroso) per misurare l’affidabilità tra valutatori è utilizzare il Kappa di Cohen , che calcola la percentuale di elementi su cui i valutatori sono d’accordo, tenendo conto del fatto che i valutatori possono concordare solo su determinati elementi. Fortunatamente.
La formula kappa di Cohen si calcola come segue:
k = (p o – p e ) / (1 – p e )
Oro:
- p o : Accordo relativo osservato tra i valutatori
- p e : Probabilità ipotetica di accordo casuale
Il Kappa di Cohen varia sempre tra 0 e 1, dove 0 indica assenza di accordo tra i valutatori e 1 indica perfetto accordo tra i valutatori.
Per un esempio passo passo su come calcolare la Kappa di Cohen, consulta questo tutorial .
Come interpretare l’affidabilità inter-rater
Quanto maggiore è l’affidabilità tra valutatori, tanto più coerentemente più giudici valutano gli elementi o le domande di un test con punteggi simili.
In generale, nella maggior parte delle aree è necessario un accordo tra valutatori di almeno il 75% affinché un test sia considerato affidabile. Tuttavia, in domini specifici potrebbero essere necessarie affidabilità tra valutatori più elevate.
Ad esempio, un’affidabilità tra valutatori del 75% può essere accettabile per un test volto a determinare quanto bene verrà ricevuto un programma televisivo.
D’altra parte, può essere richiesta un’affidabilità inter-valutatore del 95% in contesti medici in cui più medici valutano se un determinato trattamento debba essere utilizzato o meno su un dato paziente.
Si noti che nella maggior parte dei contesti accademici e nelle aree di ricerca rigorose, il Kappa di Cohen viene utilizzato per calcolare l’affidabilità tra valutatori.
Risorse addizionali
Una rapida introduzione all’analisi dell’affidabilità
Cos’è l’affidabilità divisa in due?
Che cos’è l’affidabilità test-retest?
Cos’è l’affidabilità delle forme parallele?
Cos’è un errore standard di misura?
Calcolatore Kappa di Cohen
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più