Albero decisionale vs foreste casuali: qual è la differenza?
Un albero decisionale è un tipo di modello di machine learning utilizzato quando la relazione tra un insieme di variabili predittive e una variabile di risposta non è lineare.
L’idea di base alla base di un albero decisionale è costruire un “albero” utilizzando un insieme di variabili predittrici che prevedano il valore di una variabile di risposta utilizzando le regole decisionali.
Ad esempio, potremmo utilizzare le variabili predittive “anni giocati” e “fuoricampo medio” per prevedere lo stipendio annuale dei giocatori di baseball professionisti.
Utilizzando questo set di dati, ecco come potrebbe apparire il modello dell’albero decisionale:
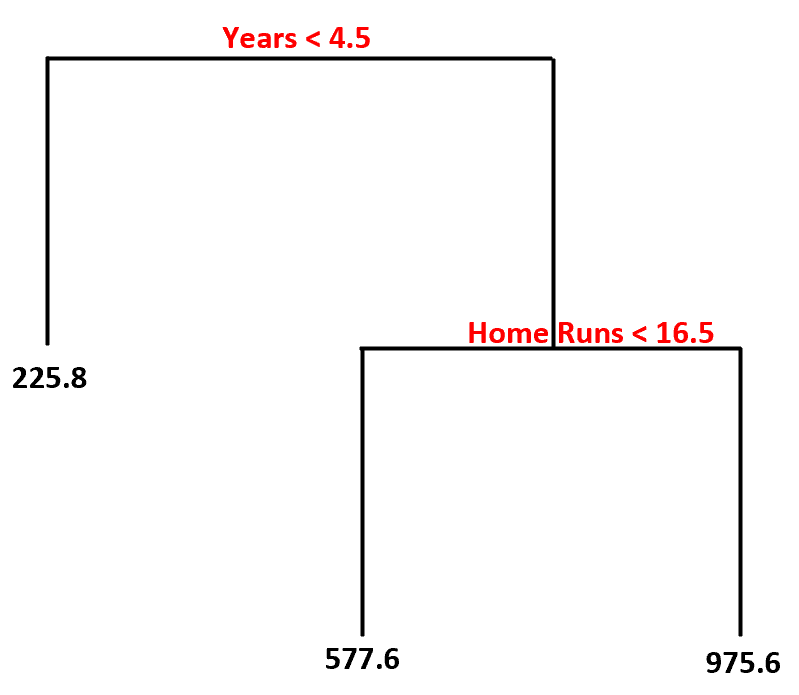
Ecco come interpreteremmo questo albero decisionale:
- I giocatori che hanno giocato meno di 4,5 anni hanno uno stipendio previsto di $ 225,8k .
- I giocatori che hanno giocato in media più di 4,5 anni o più e meno di 16,5 fuoricampo hanno uno stipendio previsto di $ 577,6K .
- I giocatori con 4,5 anni o più di esperienza e una media di 16,5 o più fuoricampo hanno uno stipendio previsto di $ 975,6K .
Il vantaggio principale di un albero decisionale è che può essere adattato rapidamente a un set di dati e il modello finale può essere visualizzato e interpretato chiaramente utilizzando un diagramma ad “albero” come quello sopra.
Lo svantaggio principale è che un albero decisionale tende a adattarsi eccessivamente a un set di dati di addestramento, il che significa che è probabile che funzioni male su dati invisibili. Ciò può anche essere fortemente influenzato da valori anomali nel set di dati.
Un’estensione dell’albero decisionale è un modello noto come foresta casuale , che è essenzialmente un insieme di alberi decisionali.
Ecco i passaggi che utilizziamo per creare un modello di foresta casuale:
1. Prendi campioni bootstrap dal set di dati originale.
2. Per ciascun campione di bootstrap, creare un albero decisionale utilizzando un sottoinsieme casuale di variabili predittive.
3. Media delle previsioni di ciascun albero per ottenere un modello finale.
Il vantaggio delle foreste casuali è che tendono a funzionare molto meglio degli alberi decisionali su dati invisibili e sono meno inclini a valori anomali.
Lo svantaggio delle foreste casuali è che non c’è modo di visualizzare il modello finale e la loro costruzione può richiedere molto tempo se non si dispone di potenza di calcolo sufficiente o se il set di dati con cui si lavora è estremamente ingombrante.
Vantaggi e svantaggi: alberi decisionali vs. Foreste casuali
La tabella seguente riassume i vantaggi e gli svantaggi degli alberi decisionali rispetto alle foreste casuali:
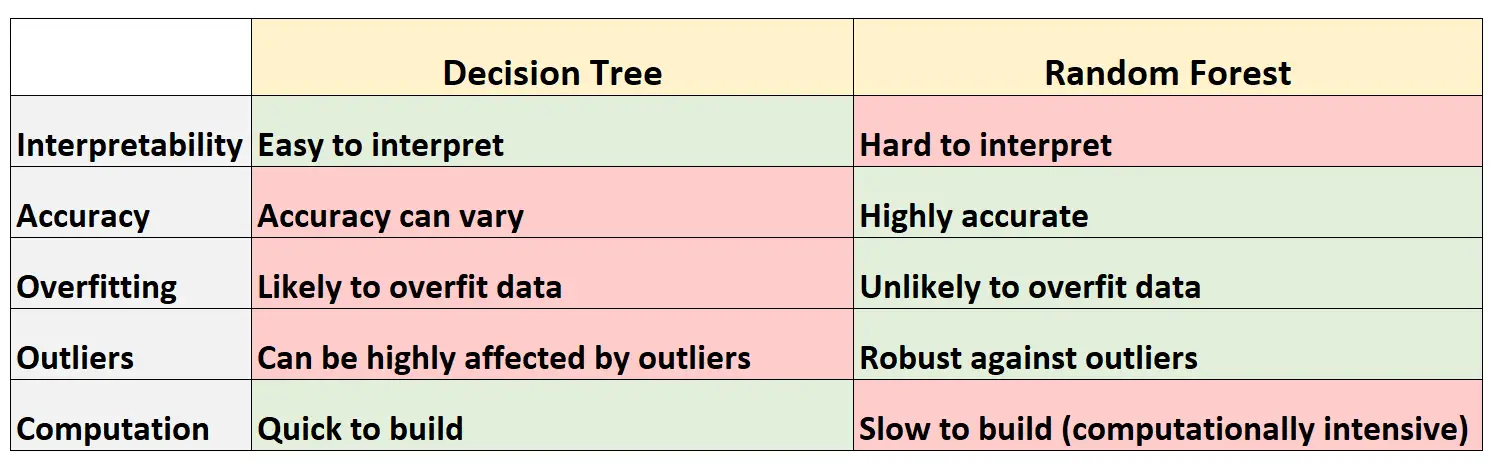
Di seguito è riportata una breve spiegazione di ciascuna riga della tabella:
1. Interpretabilità
Gli alberi decisionali sono facili da interpretare perché possiamo creare un diagramma ad albero per visualizzare e comprendere il modello finale.
Al contrario, non possiamo visualizzare una foresta casuale e spesso può essere difficile capire come il modello finale della foresta casuale prenda le decisioni.
2. Precisione
Poiché è probabile che gli alberi decisionali si adattino eccessivamente a un set di dati di addestramento, tendono a funzionare peggio su set di dati invisibili.
Al contrario, le foreste casuali tendono ad essere molto precise su set di dati invisibili perché evitano l’adattamento eccessivo dei set di dati di addestramento.
3. Adattamento eccessivo
Come accennato in precedenza, gli alberi decisionali spesso si adattano eccessivamente ai dati di addestramento: ciò significa che è probabile che si adattino al “rumore” di un set di dati, in contrapposizione al vero modello sottostante.
Al contrario, poiché le foreste casuali utilizzano solo determinate variabili predittive per costruire ogni singolo albero decisionale, gli alberi finali tendono ad essere decorati, il che significa che è improbabile che i modelli di foreste casuali si adattino eccessivamente ai set di dati.
4. Valori anomali
Gli alberi decisionali sono molto suscettibili a essere influenzati da valori anomali.
Al contrario, poiché un modello di foresta casuale costruisce molti alberi decisionali individuali e poi prende la media delle previsioni da quegli alberi, è molto meno probabile che sia influenzato da valori anomali.
5. Calcolo
Gli alberi decisionali possono essere rapidamente adattati ai set di dati.
Al contrario, le foreste casuali richiedono un utilizzo molto più intenso dal punto di vista computazionale e possono richiedere molto tempo per la creazione, a seconda delle dimensioni del set di dati.
Quando utilizzare alberi decisionali o foreste casuali
Generalmente:
Dovresti utilizzare un albero decisionale se desideri creare rapidamente un modello non lineare ed essere in grado di interpretare facilmente il modo in cui il modello prende le decisioni.
Tuttavia, dovresti utilizzare una foresta casuale se disponi di molta potenza di calcolo e desideri creare un modello che sia probabilmente molto accurato senza preoccuparti di come interpretarlo.
Nel mondo reale, gli ingegneri e i data scientist del machine learning utilizzano spesso foreste casuali perché sono molto precise e i computer e i sistemi moderni sono spesso in grado di gestire set di dati di grandi dimensioni che prima non potevano essere gestiti.
Risorse addizionali
Le seguenti esercitazioni forniscono un’introduzione agli alberi decisionali e ai modelli di foreste casuali:
I seguenti tutorial spiegano come adattare alberi decisionali e foreste casuali in R:
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più