Analisi discriminante lineare in python (passo dopo passo)
L’analisi discriminante lineare è un metodo che è possibile utilizzare quando si dispone di un insieme di variabili predittive e si desidera classificare una variabile di risposta in due o più classi.
Questo tutorial fornisce un esempio passo passo di come eseguire l’analisi discriminante lineare in Python.
Passaggio 1: caricare le librerie necessarie
Innanzitutto, caricheremo le funzioni e le librerie necessarie per questo esempio:
from sklearn. model_selection import train_test_split
from sklearn. model_selection import RepeatedStratifiedKFold
from sklearn. model_selection import cross_val_score
from sklearn. discriminant_analysis import LinearDiscriminantAnalysis
from sklearn import datasets
import matplotlib. pyplot as plt
import pandas as pd
import numpy as np
Passaggio 2: caricare i dati
Per questo esempio, utilizzeremo il set di dati iris dalla libreria sklearn. Il codice seguente mostra come caricare questo set di dati e convertirlo in un DataFrame panda per facilità d’uso:
#load iris dataset iris = datasets. load_iris () #convert dataset to pandas DataFrame df = pd.DataFrame(data = np.c_[iris[' data '], iris[' target ']], columns = iris[' feature_names '] + [' target ']) df[' species '] = pd. Categorical . from_codes (iris.target, iris.target_names) df.columns = [' s_length ', ' s_width ', ' p_length ', ' p_width ', ' target ', ' species '] #view first six rows of DataFrame df. head () s_length s_width p_length p_width target species 0 5.1 3.5 1.4 0.2 0.0 setosa 1 4.9 3.0 1.4 0.2 0.0 setosa 2 4.7 3.2 1.3 0.2 0.0 setosa 3 4.6 3.1 1.5 0.2 0.0 setosa 4 5.0 3.6 1.4 0.2 0.0 setosa #find how many total observations are in dataset len( df.index ) 150
Possiamo vedere che il set di dati contiene 150 osservazioni in totale.
Per questo esempio, costruiremo un modello di analisi discriminante lineare per classificare a quale specie appartiene un dato fiore.
Utilizzeremo le seguenti variabili predittive nel modello:
- Lunghezza del sepalo
- Larghezza del sepalo
- Lunghezza del petalo
- Larghezza del petalo
E li useremo per prevedere la variabile di risposta Specie , che supporta le seguenti tre classi potenziali:
- setosa
- versicolor
- Virginia
Passaggio 3: modificare il modello LDA
Successivamente, adatteremo il modello LDA ai nostri dati utilizzando la funzione LinearDiscriminantAnalsys di sklearn:
#define predictor and response variables X = df[[' s_length ',' s_width ',' p_length ',' p_width ']] y = df[' species '] #Fit the LDA model model = LinearDiscriminantAnalysis() model. fit (x,y)
Passaggio 4: utilizzare il modello per fare previsioni
Una volta adattato il modello utilizzando i nostri dati, possiamo valutare le prestazioni del modello utilizzando ripetute validazioni incrociate stratificate k-fold.
Per questo esempio utilizzeremo 10 pieghe e 3 ripetizioni:
#Define method to evaluate model
cv = RepeatedStratifiedKFold(n_splits= 10 , n_repeats= 3 , random_state= 1 )
#evaluate model
scores = cross_val_score(model, X, y, scoring=' accuracy ', cv=cv, n_jobs=-1)
print( np.mean (scores))
0.9777777777777779
Possiamo vedere che il modello ha raggiunto una precisione media del 97,78% .
Possiamo anche utilizzare il modello per prevedere a quale classe appartiene un nuovo fiore, in base ai valori di input:
#define new observation new = [5, 3, 1, .4] #predict which class the new observation belongs to model. predict ([new]) array(['setosa'], dtype='<U10')
Vediamo che il modello prevede che questa nuova osservazione appartenga alla specie chiamata setosa .
Passaggio 5: visualizzare i risultati
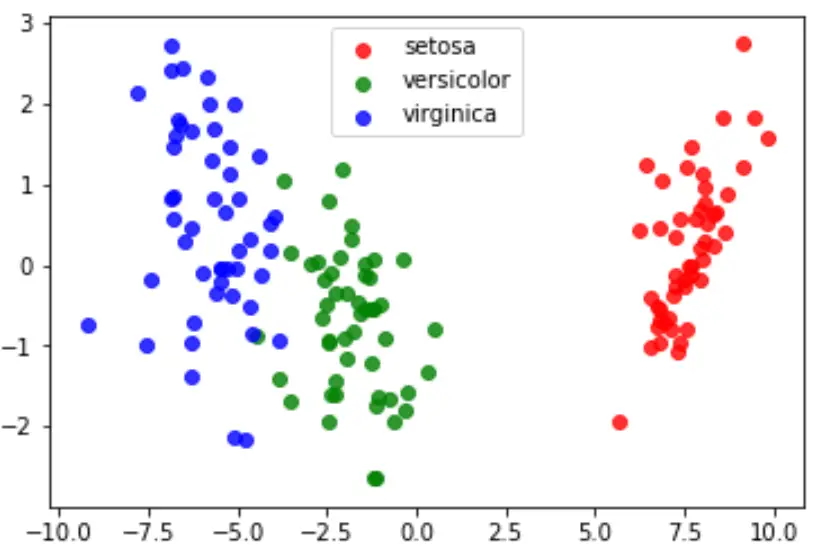
Infine, possiamo creare un grafico LDA per visualizzare i discriminanti lineari del modello e quanto bene separa le tre diverse specie nel nostro set di dati:
#define data to plot X = iris.data y = iris.target model = LinearDiscriminantAnalysis() data_plot = model. fit (x,y). transform (X) target_names = iris. target_names #create LDA plot plt. figure () colors = [' red ', ' green ', ' blue '] lw = 2 for color, i, target_name in zip(colors, [0, 1, 2], target_names): plt. scatter (data_plot[y == i, 0], data_plot[y == i, 1], alpha=.8, color=color, label=target_name) #add legend to plot plt. legend (loc=' best ', shadow= False , scatterpoints=1) #display LDA plot plt. show ()
Puoi trovare il codice Python completo utilizzato in questo tutorial qui .
Informazioni sull'autore
Benjamin anderson
Ciao, sono Benjamin, un professore di statistica in pensione diventato insegnante dedicato di Statorials. Con una vasta esperienza e competenza nel campo della statistica, sono ansioso di condividere le mie conoscenze per potenziare gli studenti attraverso Statorials. Scopri di più